
[네이버 부스트 캠프] AI-Tech - week5(6)
Tips
이제 우리는 학습할 때 고려해야할 것들에 대해서 알아본다.
Maximum Likelihood Estimation
optimization via Gradient Descent
overfitting and Regularization
Training and Test Dataset
1. Maximum Likelihood Estimation
Maximum Likelihood Estimation (최대 가능도 추정)은 random variable의 parameter를 추정하는 방법 중 하나이다. 즉, 데이터들을 가지고 parameter을 추정하는 방법이다.
예를 들자면, probability density function f0가 있다고 가정해보자.
그리고 X=(x1,x2,x3,…,xn)를 그 확률로 생성되는 Observation 이라 하자 (측정한 데이터라고 생각하면 된다).
이제 density function이 다음과 같이 θ로 parameterize된 어떤 분포의 family라고 가정해보자. {f(⋅|θ)}.
만약 observation x가 주어진다면, θ의 값만 알 수 있다면 바로 f(x|θ)의 값을 계산할 수 있는 것이다.
이처럼 우리는 적절한 f를 찾기 위해 θ를 estimate해야하고, 이를 위해서 θ를 estimate하기 위한 방법으로 MLE을 이용한다. 그리고 MLE가 최대일 때 θ를 구해 적절한 f를 찾도록 한다.
2. optimization via Gradient Descent
Gradient Descent(경사 하강법)은 θ와 X의 그래프가 주어졌을 때, 한 점에서의 기울기를 이용해서 가장 최소가 되는 값을 찾는 방법이다.
$\Theta = \Theta - \alpha \bigtriangledown _{\Theta }L(x; \Theta )$
여기서 $\alpha$ 는 learning rate를 의미하는 데 값의 크기가 크다면, theta 값이 발산할 수 있고 작다면, theta값이 움직이지 않을 수 있다. 적당한 값을 찾도록 조정해야한다.
Gradient Descent 를 하면서 가장 최소 값을 찾을 수 있지만, 그와 함께 overfitting은 항상 따라오게 된다. 그 이유는 데이터가 항상 일관적이지 않고 몇몇 일관적이지 않은 변수에 의해 함수 그래프가 달라지게 되기 때문이다.
3. Overfitting and Regularization
Overfitting은 데이터에서 일관되지 않은 정보가 있다면, 학습 데이터에 과도하게 fitting 되어 함수가 나오게 된다. 우리는 이 경우를 overfitting이라고 한다.
overfitting을 피하기 위해서는 observation을 나눠서 Training을 진행한다.
` Data = Training Set(80%) + Dev Set(0~10%) + Test Set(10~20%) `
Dev Set은 Validation Set이라고 부르기도 하며, Test Set에 대한 overfitting을 방지하기 위함이다.
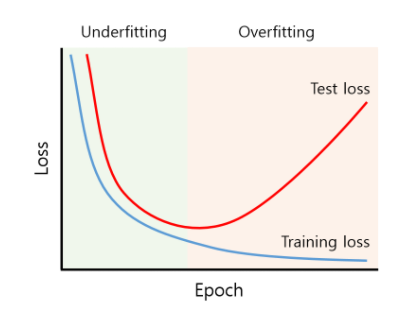
위의 그림과 같이 Epoch가 지날수록 식은 Trainig Data에 적합하게 Loss가 줄어들지만 Test Set의 경우 Loss가 증가하게 되어 적절치 않은 함수가 만들어지게 될 수 있다.
따라서 서로의 loss의 차이가 최소가 되는 theta를 찾아야한다.
Overfitting을 막기 위한 방법은 3가지 정도가 있다.
- More Data
- Less Feature
- Regularization
데이터를 많이 수집하거나 Feature를 줄여 일반화시킬 수 있도록 한다.
여기서 우리는 Regularization 방법을 봐야한다.
Regularization 은 ‘정규화’를 뜻하며, overfitting을 줄일 때 쓰는 주요한 방법이다. 정규화 방법은 여러가지가 있다.
- Early Stopping (validation loss가 더이상 낮아지지 않을 때 멈추는 방법)
- Reduce Network Sizing
- Weight Decay
- Drop Out
- Batch Normalization
4번, 5번 두가지가 주로 쓰인다.
현재까지 했던 이론을 토대로 해서 가장 기초적으로 DNN을 만드는 방법을 접근하자면 3가지로 나눌 수 있다.
- Make a neural network architecture
- Train and Check that model is overfitted a. if x, increase the model size (deeper and wider) b. if o, add regularization (drop-out, batch-normalization)
- Repeat 2.
4. Full Code & nn.module
코드는 jupyter notebook에 있는 강의 코드를 참고하자.
Training & Test Data를 분리하여 학습시킨 모델
Learning Rate의 크기에 따른 Cost 결과
Data Preprocessing (데이터 전처리), data를 normalize했을 때 (Batch Normalization)
Regularization