
[네이버 부스트 캠프] AI-Tech-re - week2(4)
학습기록 - 9
오늘 한 일
- 알고리즘 (30분 문제풀이 30분 해설)
- Modern CNN, RNN(과제), Transformer (과제)
- git 강의 (git merge 부분 병합 시 충돌 대처 방법 정확히 (30분))
- 피어세션
- 과제해설 (선택과제 1,2,3)
- 학습정리
1. 강의 복습 내용
Modern CNN
네트워크를 깊게 쌓는데 파라미터를 줄이는 방법?
ILSVRC - ImageNet Large-Scale Visual
이미지 분류 알고리즘, 성능이 계속 매년 증가했다.
-
Alexnet
- 2개의 GPU를 이용해서 따로 NN을 넣음 (1개의 Input), 총 8단
- Key Ideas
- ReLU activation을 이용 : 학습 유용, overcome the vanishing gradient problem
- 2GPU
- Data augmentation, Dropout
-
VGGNet
- 3 by 3 convolution filter 활용
- Why? Receptive field of Parameters
Receptive field 란 각 단계의 입력 이미지에 대해 하나의 필터가 커버할 수 있는 이미지의 영역
3by3 X 2 receptive field = 5by5 receptive field
But, 3by3을 두 번 쓰는 것이 5byb를 한번 쓰는 것보다 파라미터의 수가 적다.
- Why? Receptive field of Parameters
- 3 by 3 convolution filter 활용
-
GoogleNet
- 1 by 1 convolution 활용
- Network in Network(NiN) 구조 활용
-
Inception Block
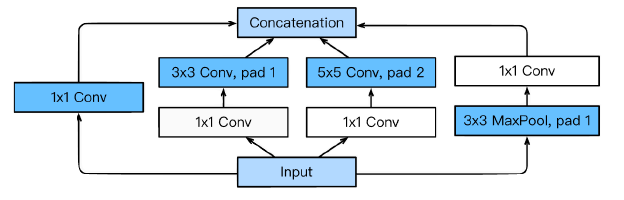
- 3 by 3 Conv 이전에 1 by 1을 한번씩 넣어준다.
- Parameter 줄어듬, How? Channel 방향으로 dimension을 줄이는 효과 존재.
- Why?
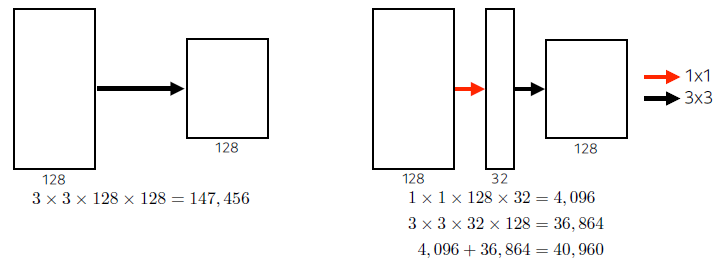
결론 : Parameter 수 - Alexnet (60M) VGGNET (110M) GoogleNet(4M)
- 1 by 1 convolution 활용
-
ResNet
- Network가 깊어지고 Parameter가 많아짐에 따라 트레이닝이 어려워진다.
보통 Overfitting으로 말하지만 이 경우에는 layer가 증가함에 따라 오히려 학습 자체가 잘 안된다. (train에서도)
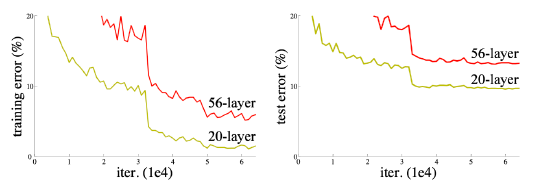
- Skip Connection : Identitiy map을 추가한다.
Input을 f(x)에 더해줘서 학습시킨다. (식은 이해가 가겠는데 이 의미를 이해하지 못하겠다.)
차이만 학습을 한다? Input을 f(x)에 플러스한다는 의미가 뭐지?
Batch Norm이 뭐였지?- Why? 가중치 소멸 문제 (Gradient Vanishing) 또는 가중치 폭발 문제 (Gradient explode) 를 해결하기 위한 접근 방법
- 배치 정규화는 활성화 함수의 활성화값 또는 출력값을 정규화하는 작업.
- 작은 가중치에서도 효과를 발휘
- Network가 깊어지고 Parameter가 많아짐에 따라 트레이닝이 어려워진다.
-
DenseNet
-
Feature를 쌓는 (Concatenation) 방법을 이용한다.
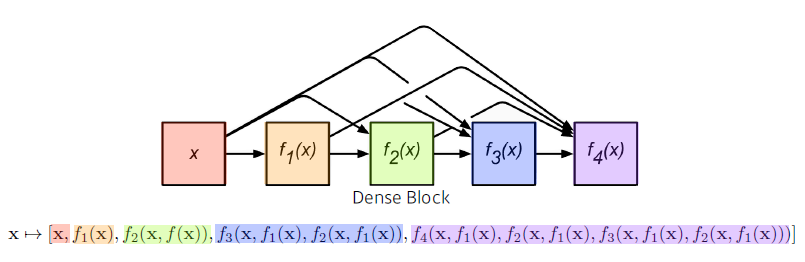
-
Dense Block, Transition Block을 통해 Feature를 쌓고 Channel을 줄이고를 반복한다.
-
RNN
-
Sequential Model
-
Naïve Sequence Model
과거의 정보량이 점점 늘어나게 된다. -> Fix the past timespan -
Markov model
내가 가정하기에 나의 현재는 과거에만 dependent (바로 직전 과거) But, 많은 정보를 버리게 된다. -
Latent autoregressive model
과거의 정보를 hidden state에만 dependent (과거 정보를 summarize 한다.)
-
-
Recurrent Neural Network
-
자기 자신으로 돌아오는 state를 하나 추가 시킨다. Hidden state으로 오는 input이 x(t) 와 h(t-1) 을 이용한다.
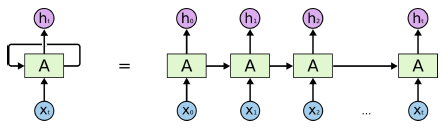
-
Long-term dependencies
엄청 먼 과거의 정보는 고려할 수가 없게 된다.
(Short Term Dependencies 에는 강하다.)
Gradient Vanishing(Sigmoid) & Gradient Explode(다른 function에 의해, 계속 곱해지기 때문에) -
이 문제를 해결하기 위해 LSTM
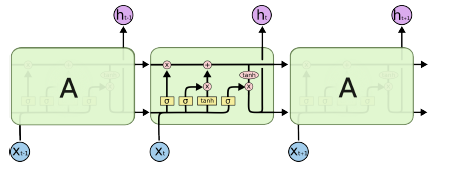
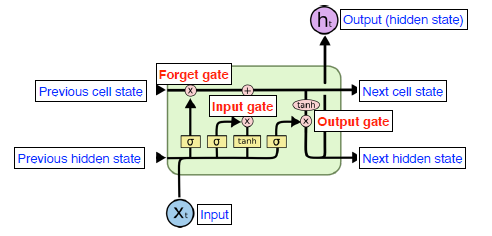
- 입력
- Previous Cell state : 과거 정보들을 취합해줌(summarize. 정보를 이용만 할 뿐 Output이 되지 않는다.
- Previous hidden state : 과거 Hidden state, Output에 이용
- Input : 현재 입력 값
-
Gate (정보를 조작하는 역할)
-
Forget gate : 어떤 정보를 버릴 것인지 판단, (0~1 by sigmoid)
$ f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right) $
-
Input Gate : 어떤 정보를 얼마나 올릴지 판단
$i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right)$
$\tilde{C}{t}=\tanh \left(W{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)$
-
Update Gate : 어떤 정보를 버릴지 올릴지 판단. (Forget Gate + Input Gate) -> Cell State 의 결과를 만들어 준다.
$i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right)$
$C_{t}=f_{t} * C_{t-1}+i_{t} * \tilde{C}_{t}$
-
Output gate : 어떤 정보를 밖으로 빼낼지 판단. 이전 hidden state에서 현재 업데이트 된
Cell State를 이용해서 Output과 Hidden State를 만들어 준다.$o_{t}=\sigma\left(W_{o}\left[h_{t-1}, x_{t}\right]+b_{o}\right)$ $h_{t}=o_{t} * \tanh \left(C_{t}\right)$
-
- 출력
Output, Next Cell State, Next hidden State
- 입력
-
-
Gated Recurrent Unit (GRU)
-
reset Gate 와 update Gate만으로 구성된 구조
(Cell State와 Hidden State를 없앰 -> Parameter를 줄임)
-
Transformer
Git 강의
오늘 배웠던 내용
- 로컬에서 만들어서 원격 저장소에 잇기
- 여러 개의 commit을 나눠서 하고 싶을 때는 ? Add를 이용해서 stage에 올리고 commit 하기
- “HEAD”란 현재 워킹 디렉토리가 어느 버전인지 알려준다.
- “checkout” 현재 워킹 디렉토리 버전을 바꿔준다. (시간여행)
- Main은 마지막 워킹 디렉토리 버전이 어딨는지 알려준다.
- Mian 칸과 Main의 빈칸 중 main칸에 checkout을해서 시간여행을 복귀시켜준다. (시간여행 복귀)
-
하나의 저장소에서 여러 개의 작업을 할 때? (Test, 작업1, 작업2…)
=>저장소 전체를 카피하는 방법 (branch)를 이용
=> main의 공칸 오른쪽 “branch create”
=> Head가 exp를 가리키도록 branch check out (Head는 글씨 옆에 동글맹이)
Head가 가리키는 버전이 commit을 따라간다. -
Master가 exp를 병합 “Merge into current branch”
Exp에서 Master를 계속 병합해주면서 해야 된다.
충돌 났을 때 Link - 코드 리뷰는 ? Pull request를 이용한다.
외부에서 브랜치 생성 후, 원격에 push 하면 자동으로 pull request가 뜸 눌러줘서 comment 및 업데이트
pull request Link
마지막 작업 시 main에 브랜치를 merge 시켜줘서 완성품을 만든다.
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
-
필수 과제 : CNN
강의 따라 실습 진행, 다시 혼자 보면서 진행해봐야겠다.
코드에 대해 완벽히 이해하지 못했다. Convolution을 진행해야한다는 것뿐계속 이런 에러가 떴었는데,
CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`RuntimeError: cuda runtime error (2) : out of memory atstack over flower를 통해 해결, 런타임을 다시 시작해서 GPU를 재부팅(?) 해줘야 했었다.
3. 피어세션 정리
-
새로운 정보를 업데이트 하는 것 자체가 있어도 activation function이 존재하는 데 똑같이 explode 되고 vanishing 되지 않나? - Hidden을 골라주는 역할의 cell state가 있기 때문에 ..
-
Gradient Vanishing & exploding :
ReLU는 exploding 하는 것이 아니라 vanishing gradient를 잡아주기 위한 것, exploding 이유는
다른 activation 함수 중에 기울기가 1이 넘는 함수가 존재할 시에 생김. -
부분 문자열 :
KMP 알고리즘 & 정규표현식 -
Vit, AAE 선택과제 리뷰
4. 학습 회고
- 어제 학습 회고에서 반성했던 내용을 지켜서 오늘 하루를 마쳤다.
- 8시반 부터 계획 시작, 계획 시간이 지나면 과감하게 넘어가기
- 강의에 대한 집중
- 질문 정리
-
오늘 꽤 많은 강의가 있었는데 충분히 집중해서 들었다. 하지만 풀지 못한 선택 과제에서는 졸아버렸다.. Zzz.. 이해가 너무 어려웠기 때문인 것 같다. 하지만 멘토님들의 얘기를 듣고 느꼈던 것은 그냥 내가 시도를 안했기 때문이라고 생각한다.
결국 딥러닝이라는 이 분야에 왔으면 계속해서 공부는 해야하는 것 같다. 멘토님들의 말씀을 정리해보면,-
딥러닝은 결국 다음과 같은 과정을 필수적으로 알아야하고, Transformer는 너무 중요한 이론! MLP, Backpropa -> CNN
-> RNN -> transformer
-> NLP -> transformer -
쉬운 것부터 하나씩 이해하자. 그리고 보는 것이 아닌 직접 ‘해봐야’ 한다.
-
계속 정리 해두고, 공부하고 논문을 자주 보자.
-
조급해하지말자. 피어세션을 많이 이용하자.
-
Pytorch : 튜토리얼 이용 및 Kaggle 등 많이 해보면서 코드를 시도 해보자.
-
- 거의 모든 패턴이 만족하긴 했지만, 선택과제를 못한 것은 아쉽긴 하다.