
[네이버 부스트 캠프] AI-Tech-re - week2(2)
학습기록 - 7
오늘 한 일
- 시각화 2-1 - bar plot
- optimization
- 필수과제
- 알고리즘
- 도메인 강의
- 피어) Optim & 데이터 시각화 알고리즘
1. 강의 복습 내용
Concepts in Optimization
-
Generalization
- 일반화 성능?
- 학습을 시킬 때마다 Training Error는 줄어든다. 하지만 학습하지 않은 데이터에 대해서는 성능이 좋지 않다. (Test Error)
-> Overfitting
그 반대, 학습데이터 조차 못 맞춘다. -> underfitting
- 학습을 시킬 때마다 Training Error는 줄어든다. 하지만 학습하지 않은 데이터에 대해서는 성능이 좋지 않다. (Test Error)
- 일반화 성능?
-
Cross-validation
-
Training data, validation data
Cross-validation : 학습 데이터로 학습 시킨 모델이 validation 기준으로 얼마나 잘 되는지를 본다.
K로 나눴을 때, k-1로 학습, 1로 validation- Cv 를 해서 최적의 para를 찾고, 그 다음에 가정된 hyper에 모든 데이터를 학습
- Training Data 와 validation data 활용, test data는 활용해서 hyper parameter를 찾는 것 자체가 cheating
-
-
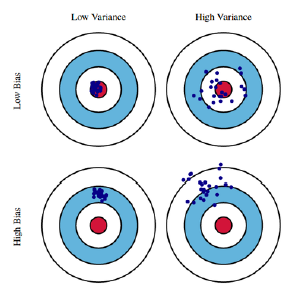
Bias and variance
- Variance : 출력이 얼마나 일관적이냐?
- Bias : 평균적으로 봤을 때, True Target에 비슷하게 접근한지?
-
결국 bias 와 variance를 둘 다 줄여야 True Target에 가까워지지만, 실제로 Trade off의 관계에 있다.
Cost를 minimize했을 때, 세가지의 요소들이 나오는데 고정된 cost값에서 bias가 낮아지면 var이 높아지는 식을 얻게 된다.
- Bootstrapping
-
이는 가설 검증(test)을 하거나 메트릭(metric)을 계산하기 전에 random sampling을 적용하는 방법(이 때에 random samling은 중복을 허용해야 한다.)
예를 들자면, 어떤 집단에서 값을 측정했을때, 그 중에서 임의로 100개를 뽑아서 평균(sample mean)을 구하는 것이다. -
Bagging VS Boosting
-
Bagging (Bootstrapping aggregating), Kaggle 앙상블
학습 데이터를 여러 개 만든다. (random subsampling)
각각의 데이터의 결과를 독립적으로 보아 결과 추출 -
Boosting
간단한 sequential 한 데이터를 만들어서 학습 시킨 뒤, weak learner 한 부분을 다시 학습시켜서 strong learner 를 만든다.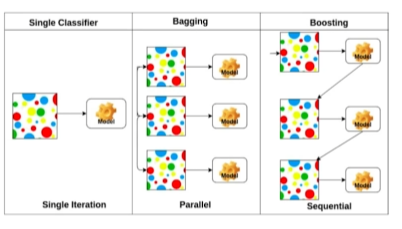
-
-
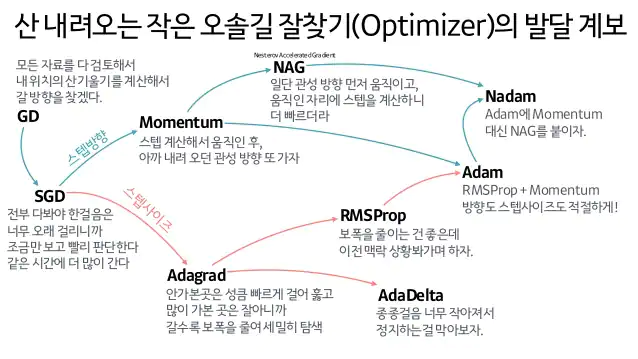
- Gradient Descent Methods
-
SGD, Mini-batch, Batch(Full) ->SGD local minimum 에 빠지지 않기 위해서 쓰인다.
- Batch-size Matters
- Sharp minimizer 보다는 flat minimizer를 찾는게 낫다.
Testing Function을 통해 확인했을 때, Batch size를 줄이면 Generalize performance 가 높아진다는 것을 보이고, (Flat minimizer) . 그렇다면 우리는 large batch size를 활용하려면 어떻게 해야할까? (논문)
- Sharp minimizer 보다는 flat minimizer를 찾는게 낫다.
- 알아서 애들이 계산을 해주지만 어떤 방법을 쓰는 것이 나을까? (Optimization)
-
GD W =W + alph*gd -> step size를 잡는 것이 어렵다.
-
Momentum
한 번 Gradient가 흐르는 방향을 그대로 가져가자. (이전 배치에서 가지고 있는 결과를 그대로 가져온다.)
But, local minimum을 지난다면, 발산하는 현상이 생긴다.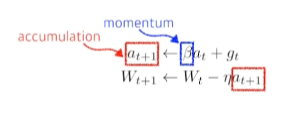
-
NAG (Nesterov Accelerated Gradient) Momentum : Momentum step 계산 후에 Gradient step 계산
NAG : Momentum 계산과 함께 Momentum과 learning rate 계산해서 Lookahead gradient 계산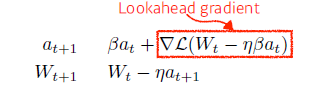
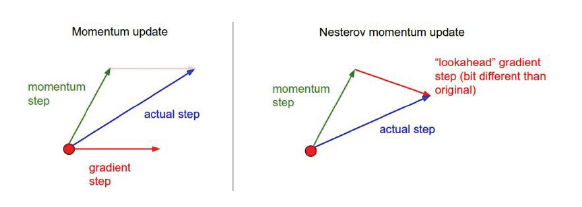
-
Adagrad
적게 변화시킨 파라미터, 크게 변화시킨 파라미터를 제곱의 합으로 가져와서 adaptive 하게 변화시킴
뒤로 가면 갈수록 학습이 멈춰지는 현상이 생김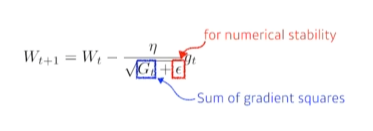
-
Adadelta
위에서 Gt가 계속해서 증가해지는 현상을 막고자 만들어진 것.
-> but, learning rate가 따로 없음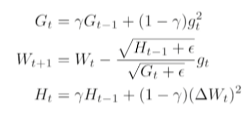
-
RMSprop

-
Adam
Momentum + RMSProp (adaptive learning rate approach)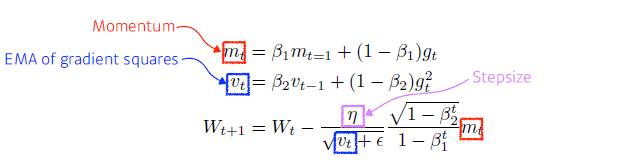
-
-
어려우니까.. 요약하자면,,
-
- Regularization
학습에 방해하도록 규정해준다. -> 학습 + Test에서 다 적용되어야 한다.
- Early stopping : 추가적인 validation data 필요
- Parameter Norm Penalty : 부드러운 함수일 수록 Generalizer performance가 높을 것이다. / Parameter norm penalty

-
Data Augmentation
More data are always welcomed
Data set이 한정이므로, data를 직접 만들어낸다. -
Noise Robustness
입력데이터, weight에 노이즈를 집어넣어준다. (실험적인 결과) -
Label Smoothing
학습 데이터 두개를 뽑아서 두개를 섞어준다. -> Decision Boundary 를 찾는 것

데이터를 다음과 같이 섞어서 데이터를 만들어준다.
데이터 셋을 더 많이 만들어준다. -
Dropout
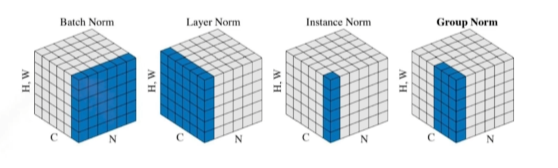
50% 정도를 random하게 0으로 만들어준다. - Batch Normalization -> 논란이 많다.
Layer를 정규화 시키는 역할
간단한 분류문제에서 성능을 올릴 수 있다.
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
- 필수 과제 : optim
linear Regression 에서 Optimizer에 따라 결과가 어떻게 출력되는지 결과를 알아본다.
-
Random Dataset을 만든다. x에 따른 노이즈가 섞인 y 값
-
모델 정의 : x -> h -> y optim에 따른 각각의 모델 생성 (SGD, momentum, adam)
optm_sgd = optim.SGD(model_sgd.parameters(), lr=LEARNING_RATE) optm_momentum = optim.SGD(model_momentum.parameters(), lr=LEARNING_RATE, momentum=0.9) optm_adam = optim.Adam(model_adam.parameters(),lr=LEARNING_RATE) -
check parameter : 모델 지정 후, parameter의 shape check
-
Train : epoch마다 모델의 학습을 시작하고, 데이터를 시각화 시켜준다.
-
-
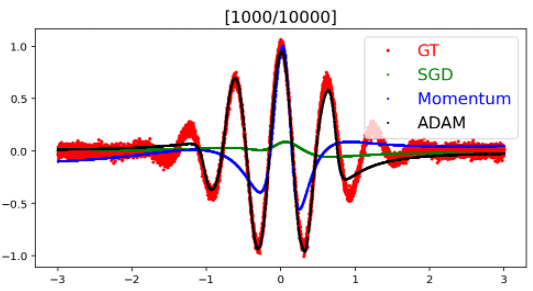
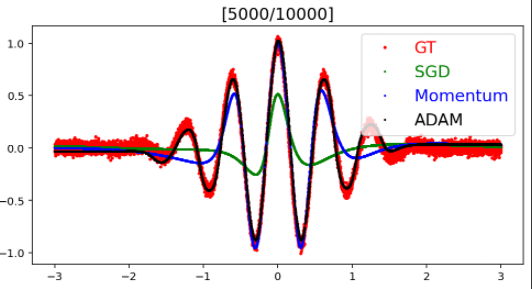
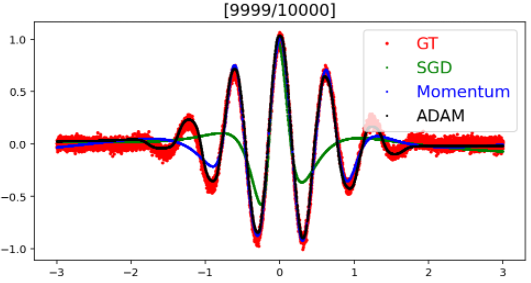
결과
결과 내용을 보면, ADAM > Momentum > SGD 순으로 모델의 에측률이 좋다.
3. 피어세션 정리
-
강의요약발표진행
- 내용: 데이터전처리 1-1~1-3, Optimization
-
알고리즘 스터디
- 내용: 백준 1013 Contact 리뷰
-
리뷰 및 질문 진행
- Optimization에서 알고리즘 몰랐거나 헷갈렸던 부분 토론
-
선택과제 1~3 리뷰 진행날짜 선정 -> 8월 17일 리뷰 확정
4. 학습 회고
-
딥러닝의 optimaization 에 대해 직관적으로 배울 수 있었다.
현재까지도 다양한 연구가 진행 중이고, 지금은 Adam이라는 optim 방법이 가장 효율적이라는 것을 알 수 있었다.
내가 데이터를 가져와서 모델을 직접 만들어 보며 효율성을 느껴야겠다. -
도메인 특강을 통해 CV, NLP의 차이를 전체적으로 알 수 있었다. 다양한 연구가 진행 중이며, 현재 시장에서도 많은 수요를 요구한다.
그런데 여기서 어떤 것을 골라야 하는 지에 대한 명확한 답을 내놓을 수는 없었다.
서로의 트렌드를 내가 겪어보지도 못했을 뿐더러, 해봐야 뭘 알기 때문이라고 생각했다.
일단 Computer Vision 쪽으로 업무를 진행했으니까, Vision 쪽으로 가보고는 싶다. 운동, 의학 쪽으로도 관심이 많았기 때문에 그 쪽을 생각해봐야겠다. -
마스터 클래스 (안수빈 마스터님)
새로운 분야를 접할 수 있어서 너무 좋았던 것 같다.
어떤 모델의 결과를 사람들에게 어떻게 표현하고 얼마나 직관적으로 그들이 잘 해석하도록 디자인 하는 지 중요한 역할인 것을 배웠다. Vision쪽으로 할 생각이 생기면서, 이 쪽도 관심이 생긴 듯하다.