
[네이버 부스트 캠프] AI-Tech - Lv3 데이터 제작(4)
학습 기록
Bag of Tricks
1.1 Need for Synthetic Data
데이터 제작에 있어서 가장 중요한 것은 양질의 데이터를 확보하는 것이다.
Real data 확보 = Public dataset 가져오기 + 직접 만들기로 구성됩니다.
하지만 여기서 문제는, 도메인(예: 한국어)에 따라 public dataset 규모가 충분하지 않을 수 있습니다.
데이터를 만들기 위해선 다음과 같은 방법이 일반적입니다.
이미지 수집:
- 웹 수집 -> 라이센스 문제
- 직접 수집 -> 직접 Annotation 생성, but, 난이도가 많이 어렵습니다.
Synthetic Data (합성 데이터) : Real Data에 대한 부담을 덜어준다.
- 비용이 덜 듭니다.
- 개인정보나 라이센스에 관한 제약으로부터 자유롭다.
- 더 세밀한 수준의 annotation도 쉽게 얻을 수 있다.
1.2 Synth Text
“Synthetic Data for Text Localisation in Natural Images”
800K dataset + 글자 이미지 합성 코드 제공

이미지 Data + 글자 Data
원본 이미지는 글자 이미지가 없어야 합니다. -> Fully annotated dataset 보장
Depth Estimation -> 적절한 위치에, 표면이라고 판단되는 곳에 맞춰서 글자를 합성 -> Realistic!

1.3 SynthText3D & Unreal Text
SynthText3D : 3D 가상 세계를 이용한 텍스트 이미지 합성
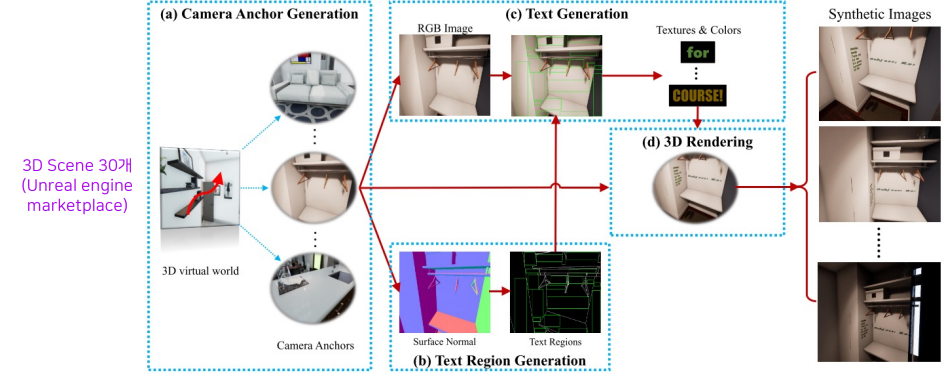
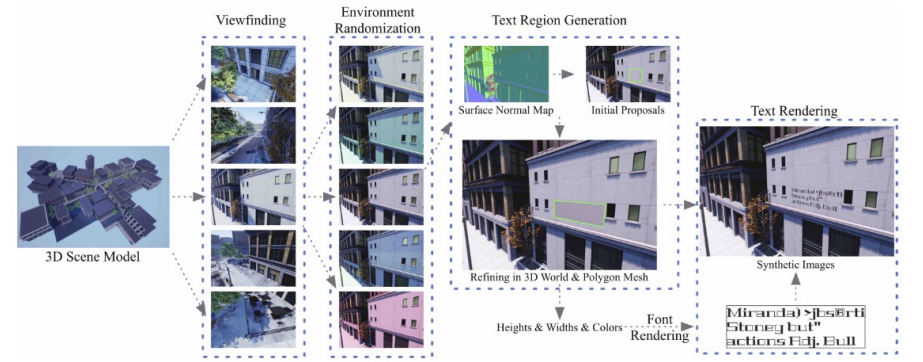
Unreal Text : 3D Virtual Engine을 이용 (개선된 viewfinding)
자동으로 있을법한 위치를 찾아서 글자를 mapping 시켜줍니다.
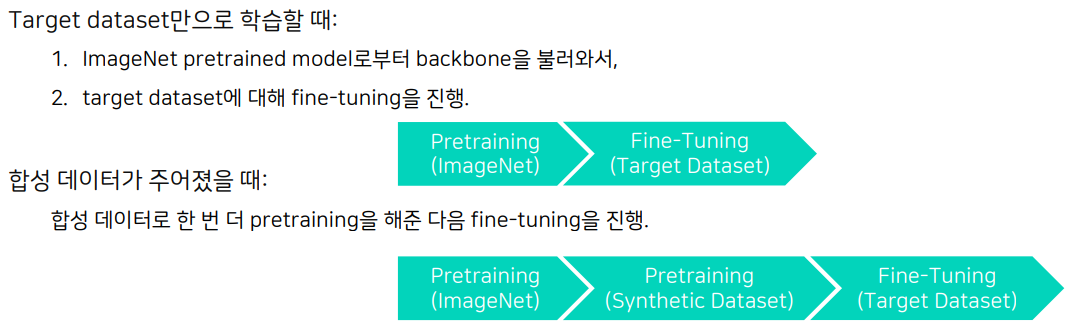
1.4 How to Use
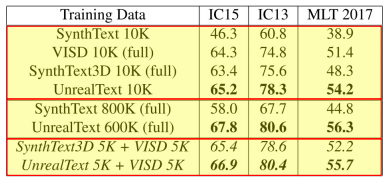
효과?.. 합성 데이터를 이용했을 때 효과가 더 좋았습니다.
10K, full (sample 수를 뜻함)
Weekly Supervised Learning
Character-level detection을 수행하는 모델 (글자 단위)
- CRAFT, TextFuseNet 등
- Real dataset 대부분은 word-level anno만 포함하기 때문에
- 학습 단계:
- 합성 데이터로 pretraining된 모델을 생성
- Real dataset에 적용해서 pseudo annotation 확보
- pseudo annotation을 이용해서 real dataset에 대한 fine-tuning을 진행
2.1 Data Augmentation
Image Data Augmentation = Geometric Transformation + Style Transformation + …
Geometric transformation: Global-level의 변화를 주는 변형 Random4crop, 4resize, 4rotate, 4flip, shear4 등

Style transformation: Local-level의 변화를 주는 변형 Color4jitter, 4channel4shuffle, 4noise4filter4 등

other Transformation
하지만 Transformation의 경우, 무분별하게 사용하면 안된다.
글자가 잘리거나 글자가 포함되지 못하는 경우가 생길 수 있다.
따라서 몇가지 규칙을 준수해 야 합니다.
Rule 1. Positive ratio 보장
최소 1개의 개체를 포함해야 한다.
별도의 hard negative mining 기법을 도입해서 해결할 수 있다.
잘린 객체 이미지에 대해 학습을 할 수 없습니다.
Rule 2. 개체 잘림 방지
잘리는 개체가 없어야 한다.
최소 하나의 개체는 잘리지 않고 포함하게 만든다.
잘린 경우, 학습에 포함되지 않도록 한다.
실제의 경우?
실제로 모델에 입력되는 이미지 관찰
- 특히 loss가 크게 발생하는 영역들을 분석해서 Rule을 업데이트하는 피드백이 필요