
[네이버 부스트 캠프] AI-Tech - Lv3 데이터 제작(3)
학습 기록
DBNet
Introduction
Segmentation 기반의 방법이 다양한 모양의 텍스트를 유연하게 잡아낼 수 있지만, 인접해 있을 경우 구분이 어려운 단점을 갖고 있습니다.
이러한 문제를 해결하기 위한 방법으로, 다음과 같이 2가지 방법을 이용했습니다.
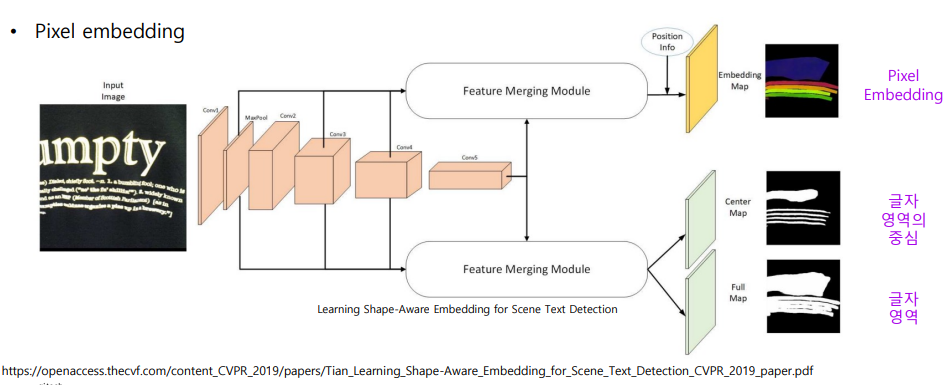
- Pixel Embedding
- 같은 영역 내 화소끼리는 가깝게 다른 영역은 멀게 학습 시켜서 후처리에 사용됩니다.
- 글자 영역 정보 외에 Pixel embedding 정보와 글자 영역의 중심 정보를 이용합니다.
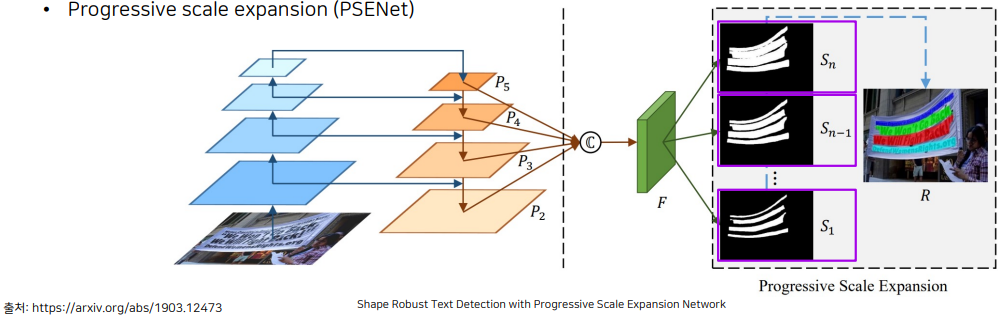
- PSENet (Progressive scale expansion)
- 글자 영역을 추측하는 feature map에서 다양한 scale의 글자 영역을 추출합니다. feature map을 저 많이 지나갈수록 center line에 가까운 영역을 만들 수 있도록 합니다.
-
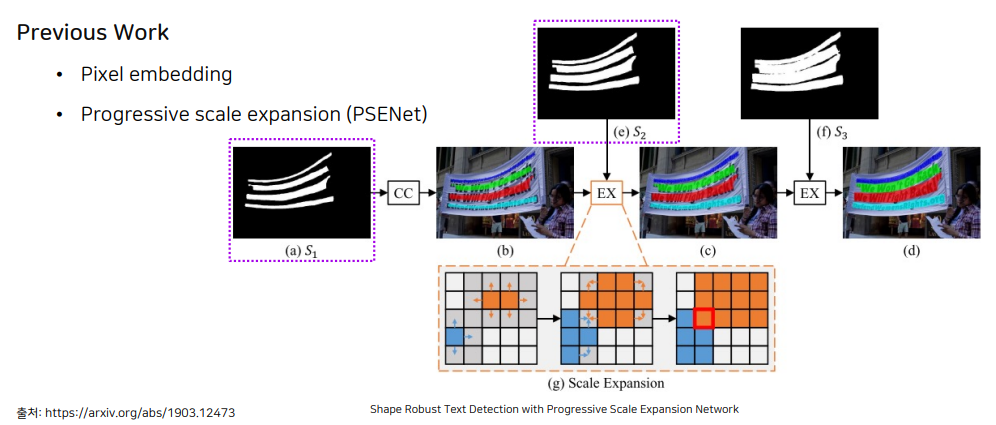
다양한 scale에서 map을 확보한 후에 제일 작은 영역부터 글자 영역을 확정 지은 뒤, 차례대로 그 다음 맵을 가져와서 글자 영역을 키워나가고 구분합니다.
Idea : Adaptive thresholding
DBNet은 글자 영역을 구분 짓는 근간인 임계치 (threshold) 적용을 모델이 생성하면 어떨까?? 라는 idea로 시작했습니다.
경계선 부분에서는 더 높은 값으로 임계치를 적용하면 영역 구분이 잘 되지 않을까?
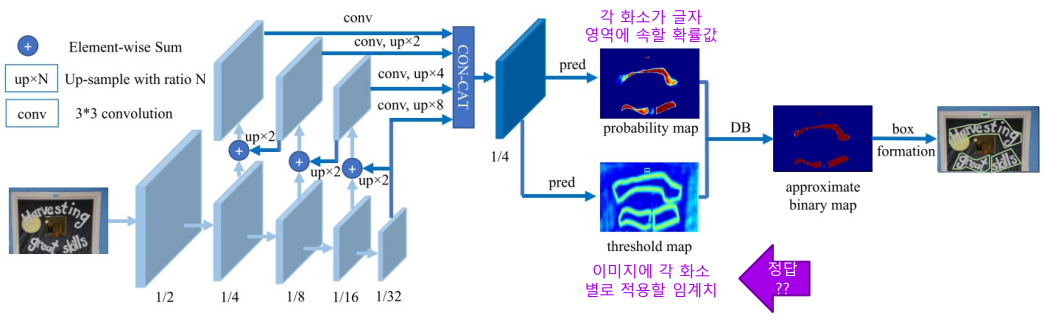
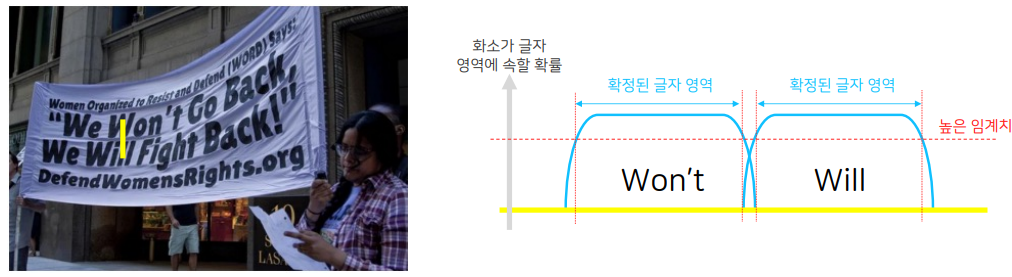
Adaptive Thresholding
글자영역 경계부분에서만 높은 임계치를 적용하고 나머지 영역은 낮은 임계치를 줍니다.
경계부분에서 바깥으로 벗어날수록 더 높은 임계치를 적용해서 찾을 수 있도록 하고, 경계부분 안쪽으로 갈수록 더 낮은 임계치를 적용해서 글자영역을 정의할 수 있도록 합니다. (글자영역의 중심 부분)
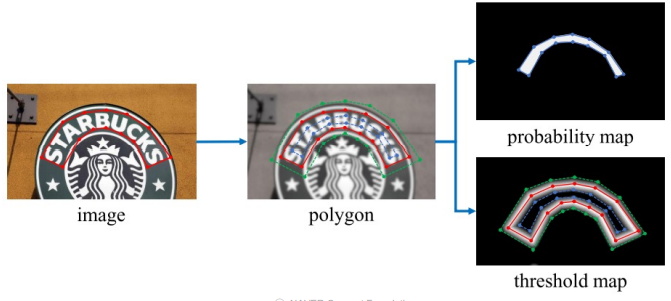
Differentiable Binarization
Threshold map을 학습을 통해 얻고자 할 때, 가장 문제되는 것은 임계치를 통한 이진화 과정이 미분 불가능한 것이 문제가 되었습니다. 해당 논문은 이러한 이유에서 Differentiable Binarization을 제안했습니다.

Training
Loss function
Loss 같은 경우, 두가지의 loss를 이용합니다.
Segmentation map(GT)는 Binarization map과 BCE loss를 구성하게 되고, Threshold map의 경우 GT threshold map과 L1 loss를 구성합니다.
GT threshold map의 경우, probablity map을 erosion, dilation, distance function을 이용해서 구할 수 있습니다.
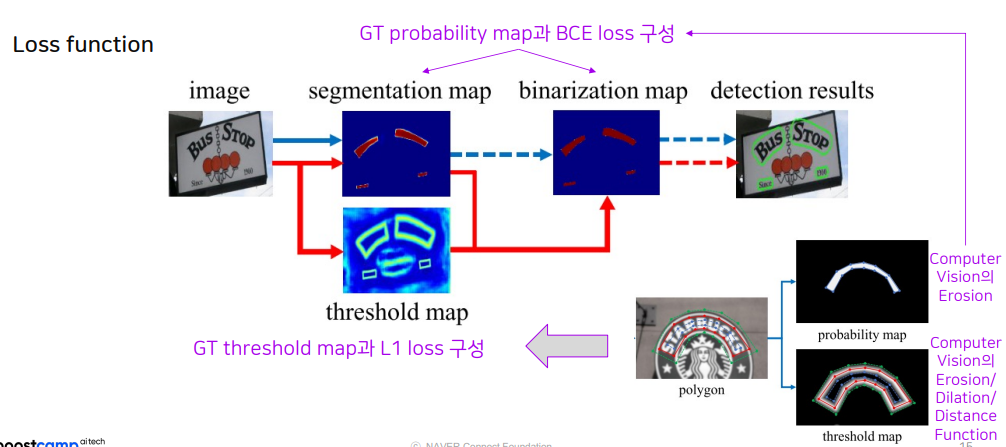
Results
우상단은 Threshold map을 (글자영역 경계에서 높은 값을 가집니다.), 우하단은 글자영역의 Probablity map을 보여줍니다. (글자영역 중심부에서 높은 값을 가집니다.)

Tips for RRC Site
RRC는 Robust Reading Competition OCR전문 학회인 icdar에서 격년으로 개최되는 컴피티션을 관리하는 사이트
음.. 여러가지가 있다…. ㅇㅅㅇ;;
MOST
Introduction
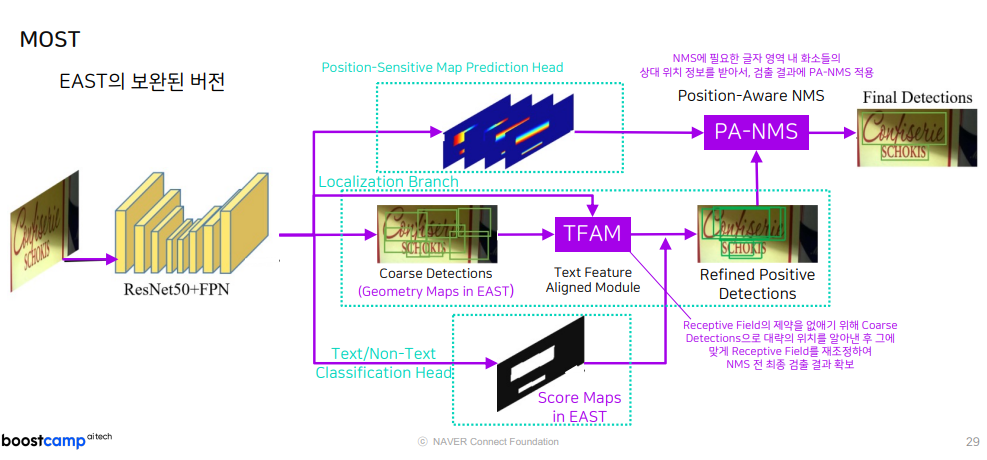
EAST 논문의 개선판!
EAST는 단순하고 빠르지만, Extreme aspect ration sample에 대해 성능이 많이 떨어집니다.
1) Receptive field의 한계, 2) LA-NMS의 문제점
이러한 EAST의 문제점을 2가지 모듈을 추가해서 보완하고자 했습니다.
첫번째는, EAST가 갖고 있는 모듈에서 TFAM(Text Feature Aligned Module)을 추가합니다.
해당 모듈은 Receptive Field의 제약을 없애기 위해 Coarse Detections으로 대략의 위치를 알아낸 후 그에 맞게 Receptive Field를 재조정하여 NMS 전 최종 검출 결과를 확보합니다.
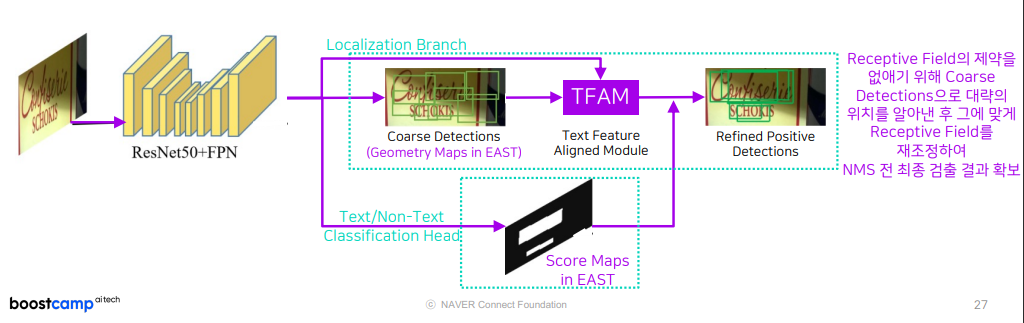
두번째는, PA-NMS (Position-Aware NMS) 입니다.
Position-Sensitive Map 이라는 글자 영역 내 화소들의 상대 위치 정보를 활용합니다.
해당 모듈은 NMS에 필요한 글자 영역 내 화소들의 상대 위치 정보를 받아서, 검출 결과에 PA-NMS를 적용합니다.
Text Feature Aligned Module TFAM
Input
- Coarse Detections 에서는 EAST의 geometry map을 출력 -> Output: H/4 x W/4 x 5
- 5ch : 상, 하, 좌, 우로 텍스트 영역 경계까지의 거리, 텍스트 각도
모든 sample들의 사각 영역을 복원하고 위와 같은 정보들이 TFAM에 들어갑니다.
Deformable Convolution
기존 Convolution은 중심점(p0)를 기준으로 총 9개의 Receptive pixel들의 위치를 지정합니다.
Deformable Convolution의 경우, 다음과 같이 델타 pn이라는 추가 offset을 넣어서 학습을 통해 정해줄 수 있도록 합니다.

Feature-based (FB) sampling
= original deformable convolution
Localization-based (LB) sampling
= Coarse detection box에 따라 offset 설정, uniform sampling
특정 화소 중심으로 사각 영역 추정, 이 사각 영역에 맞춰서 receptive field를 키워줍니다.
-> 글자영역에 맞게 키워지기 때문에 종횡비가 높아도 맞춰줄 수 있습니다.

Position-Aware NMS (PA-NMS)
Locality-aware NMS
EAST에서 고안된 NMS 방법
Row first order로 detection bbox에 대한 merging
Position-Aware NMS (PA-NMS)같은 경우, 실제 경계에서 가까운 곳에 예측한 정보일수록 가중치를 많이 주자.