
[네이버 부스트 캠프] AI-Tech - Lv3 데이터 제작(2)
학습 기록
대회 성능 평가
일반화 성능 : 성능평가는 새로운 데이터가 들어왔을 때 얼마나 잘 동작하는지 측정하는 것
ex) 미국에서 잘 작동하는 자율주행 알고리즘이 한국에서 잘 작동될까?
성능 평가 시 데이터 분리 방법
Data -> train-test split -> train-test split -> Validation split (k-fold + ensemble)
성능 평가 시 추가 분석 내용 (정량 평가)
Recall : 실제 Truth 일 때, 예측 결과가 Truth인 경우
Precision : 예측 Truth 일 때, 실제 Truth인 경우
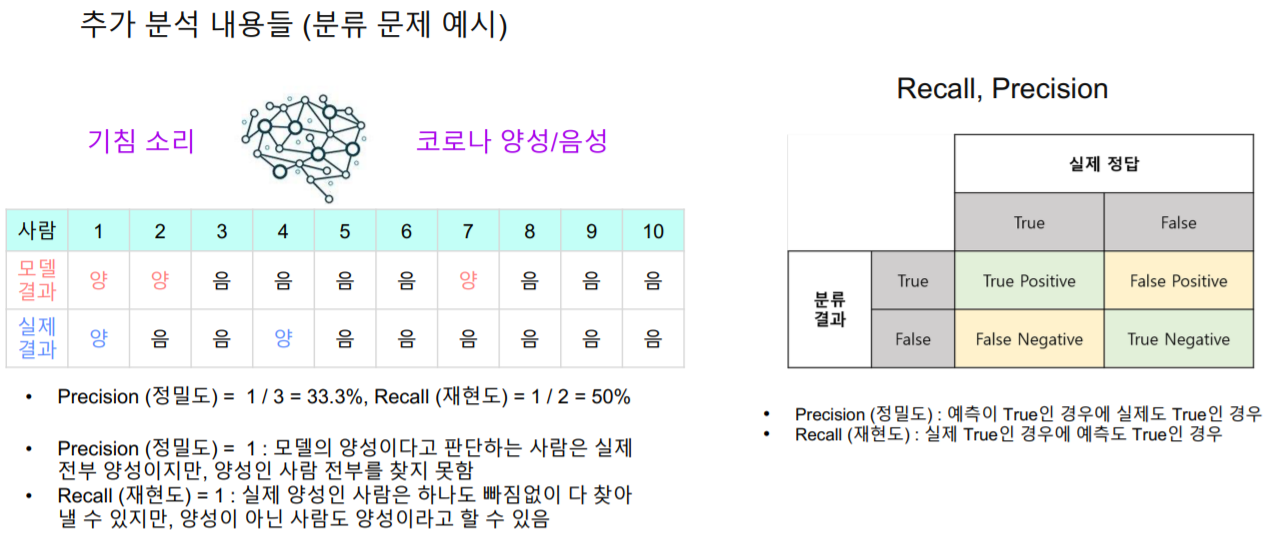
(예시)
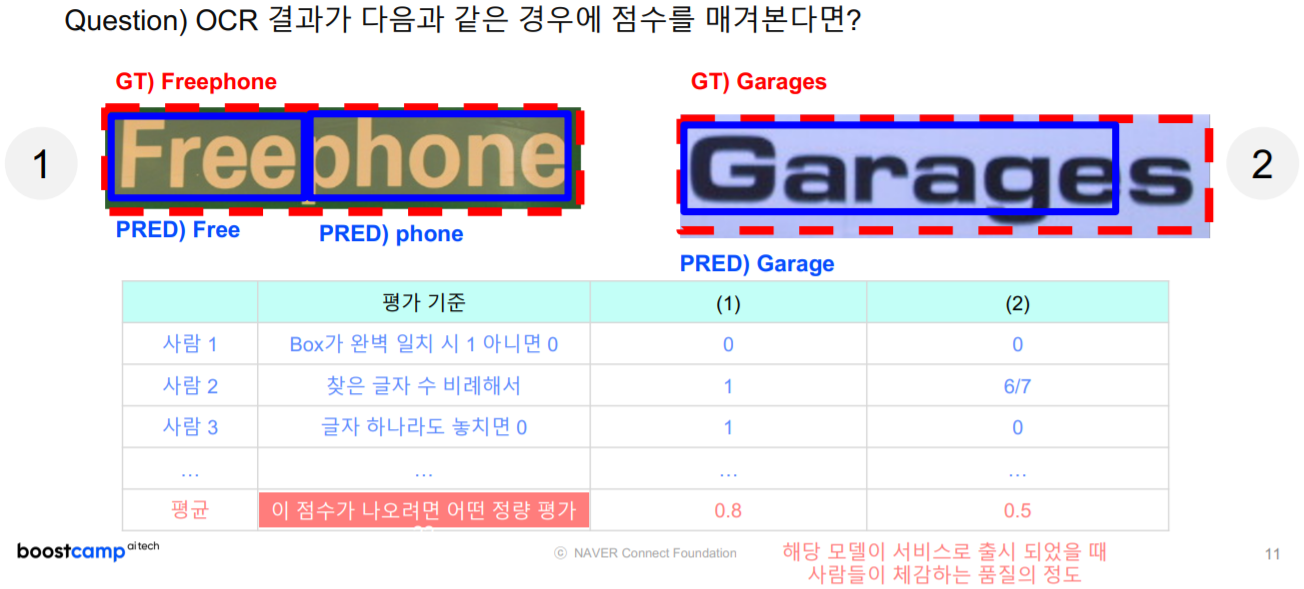
글자 검출 모델 평가
글자 검출 모델 평가 방식의 구성 요소 검출 모델 평가 다이어그램
두 영역 간의 매칭 판단 방법 (매칭 행렬 계산) + 매칭 행렬에서 유사도 수치 계산 방법 (유사도 계산)

두 영역 간 매칭 판단 방법 (기본 용어 예시)
- IoU
- Area Recall / Area Precision
-
One-to-One One-to-Many Many-to-One Match 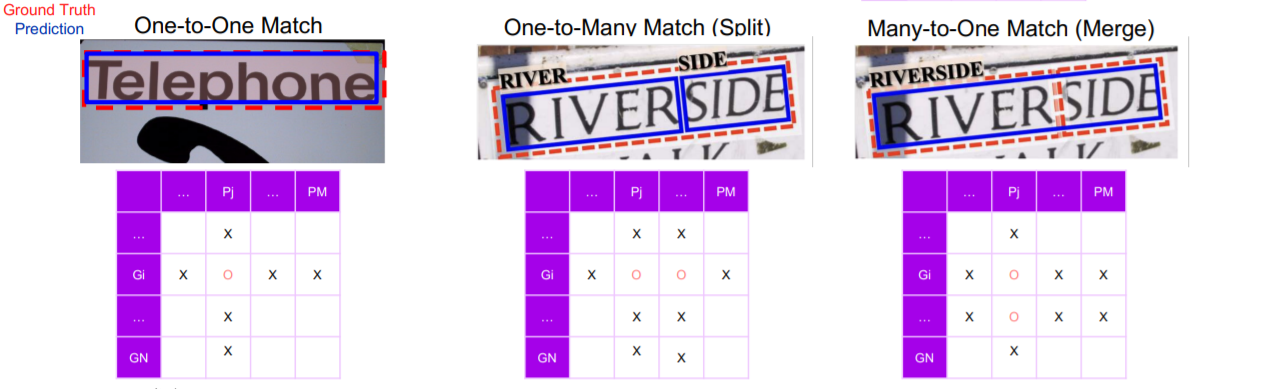
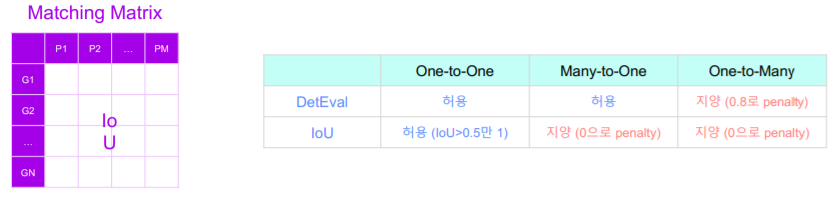
실제 사용되는 정량 평가 방식 (가장 많이 사용되는 방식 중 하나)
DetEval
- 매칭 행렬의 한 셀마다 Area Recall, Area Precision을 구합니다. (2개의 수치 확보)
- 셀 중에 area recall >= 0.8 and area precision >= 0.4 조건을 충족시키면 1 아니면 0 값으로 관계 행렬 값을 바꿈
-
Binary map이 완성됐으면, 아래의 그림과 같이 판단.. (?)
(질문) 무슨 얘기지? 어떤 방식으로 학습을 시키는지 이해가 안감.

IoU
Intersection over Union
- one-to-one matching만 허용
-
one-to-one matching이 성립 (IoU value > 0.5 일 경우)
- 한계점
- 부족한 영역에 대해서도 좋은 점수를 매김
-
split으로 예측했을 때, 아예 점수를 안매김

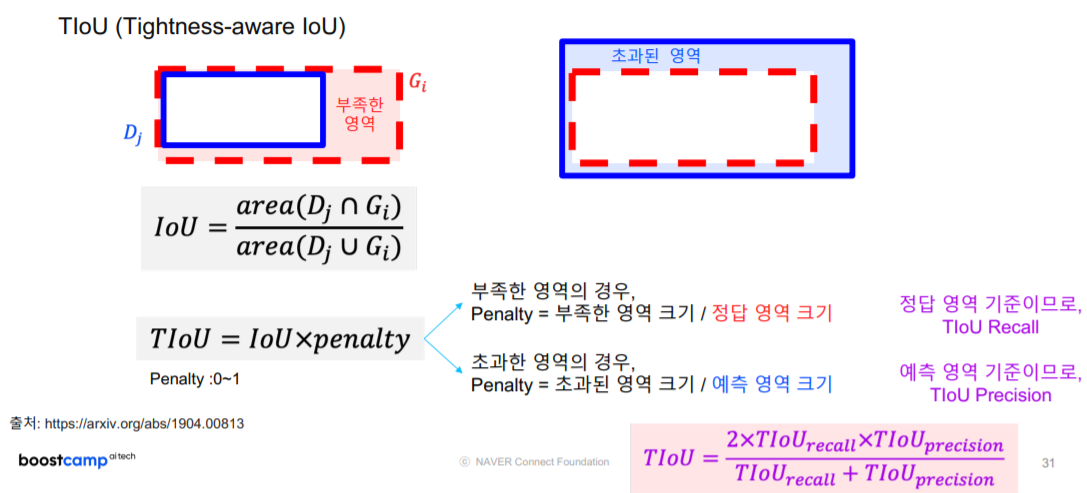
TIoU (Tightness-aware IoU)
- 부족하거나 초과된 영역 크기에 비례하여 IoU 점수에 대해 penalty를 부여
- GT의 completeness, 예측 박스의 타이트함을 점수에 반영
- GT가 Golden Ground Truth (완벽한 정답) -> 정답 자체가 잘못되어있다면, 여파가 크다.
-
각각의 기준에 따라 TIoU를 만들어주고 이것의 ‘조화평균’을 이용해서 TIoU를 만들어줍니다.
- 한계점
-
부족한 영역의 크기는 같은데 동일한 점수를 부여해도 괜찮을까?

-
CLEval (Character-Level Evaluation)
- 검출기(글자 위치)의 성능은 인식기(글자)의 관점에서 바라봐야 한다.
- 얼마나 많은 글자를 맞추고 틀렸느냐를 가지고 평가.