
[네이버 부스트 캠프] AI-Tech - Lv3 데이터 제작(1)
학습 기록
Software 1.0
딥러닝이 아닌 software, 일반적인 프로그램 (C++, C)과 같은 고전적인 스택을 의미합니다.
- 문제 정의
- 큰 문제를 작은 문제들의 집합으로 분해
- 개별 문제 별로 알고리즘 설계
- 솔루션들을 합쳐 하나의 시스템화
Visual Recognition Task
이미지 인식 기술도 처음엔 Software 1.0 철학으로 개발
문제를 정의하고 큰 문제에 대해 작은 무제로 분해, 각각의 솔루션들을 합쳐 시스템화 시킵니다.
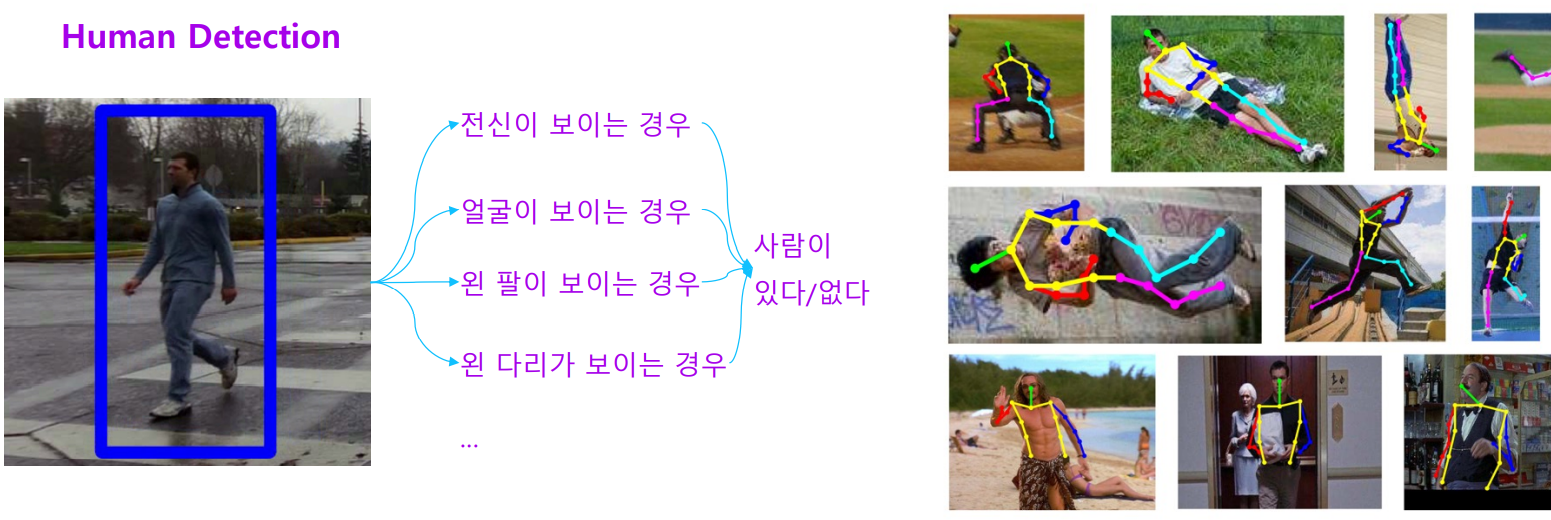
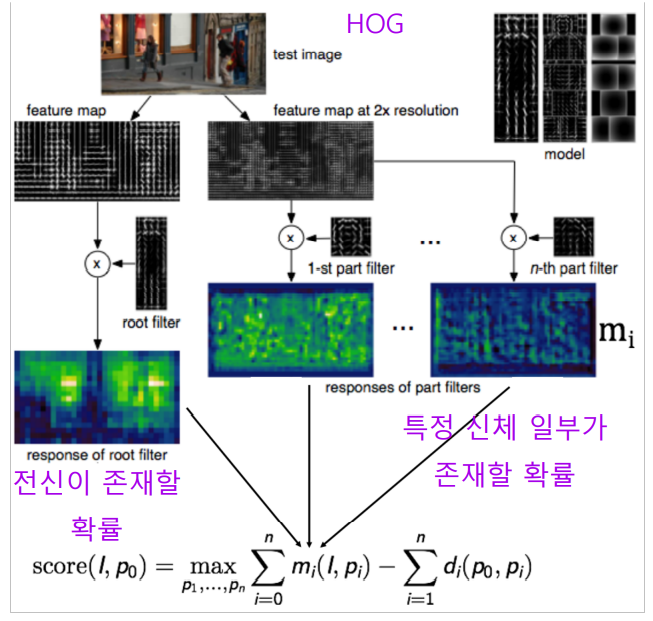
하지만 객체 검출에서 대응하기 어려운 케이스가 많았습니다.
이 객체 검출을 더 고도화 시켰지만, 한계가 찾아왔습니다.
이 한계를 극복하고자 Software 2.0 방법이 등장했습니다.
그 이후, 많은 논문들이 등장했고 성능이 빠르게 오르기 시작했습니다.
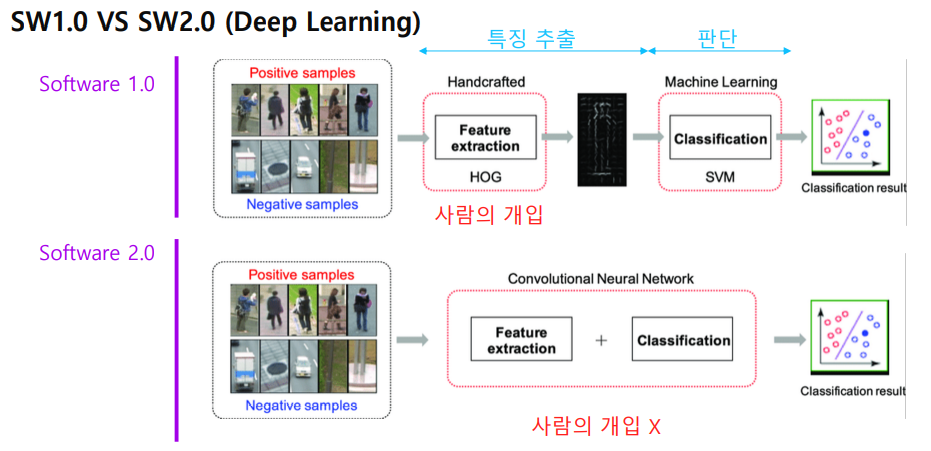
Software 1.0 vs 2.0은 다음과 같습니다.
특징을 추출하는데 사람의 개입이 없어지고 연산을 통해 특징 추출과 분류를 할 수 있도록 했습니다.
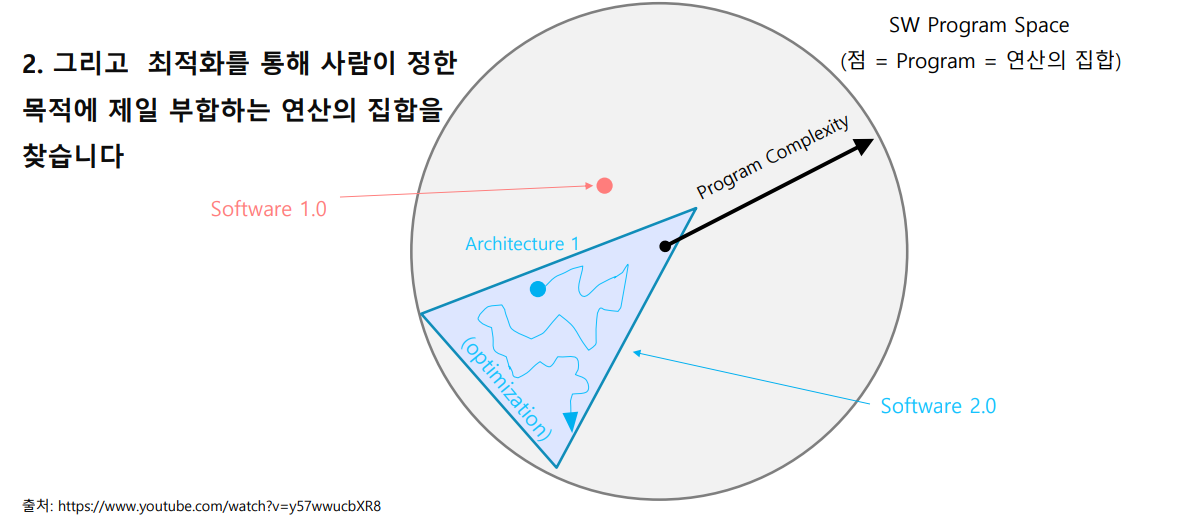
이를 구(Sphere) 모형으로 표현하면, 다음과 같습니다.
Software 1.0은 어떤 정해진 연산(점)을 사람이 직접 만들어야 한다면,
Software 2.0에서는 CNN을 통해 Architecture를 그리고 그 안에서 최적화된 연산(점)을 스스로 찾아나가는 방법입니다.
요약한다면,
Software 1.0은 사람이 고민하여 프로그램을 만드는 것
Software 2.0은 AI 모델의 구조로 프로그램의 검색 범위를 한정, 데이터와 최적화 방법을 통해 최적의 프로그램을 찾음
AI 모델의 성능 = (모델 구조 + 최적화 방법) + 데이터 = 코드 + 데이터
이러한 Software 2.0은 다양한 분야에서 성과를 내고 있습니다.
최근에는 사람의 개입이 거의 사라지고, 모델의 최적화에 많이 신경을 쓰고 있습니다.
모델은 Transformer를 통해 컴퓨터 비전 외 다양한 분야에서도 성과를 내고 있습니다.
아직 산업계에는 CNN에 대한 많은 불신이 존재하지만, 그 신뢰성은 점점 올라가고 있는 추세입니다.
Lifecycle of an AI Project
AI project의 경우, 실제 업무 (서비스)에 있을 때, 서비스의 요구사항만 주어질 뿐 데이터에 대해서는 주어지지 않습니다.
따라서 데이터를 제작할 수 있고, 테스트 데이터 셋을 만들 수 있어야 합니다.
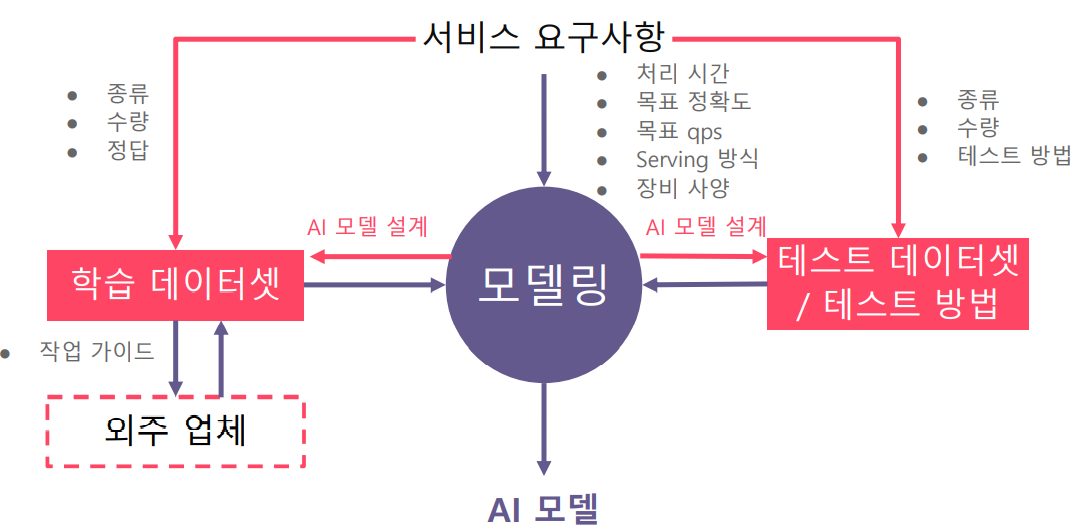
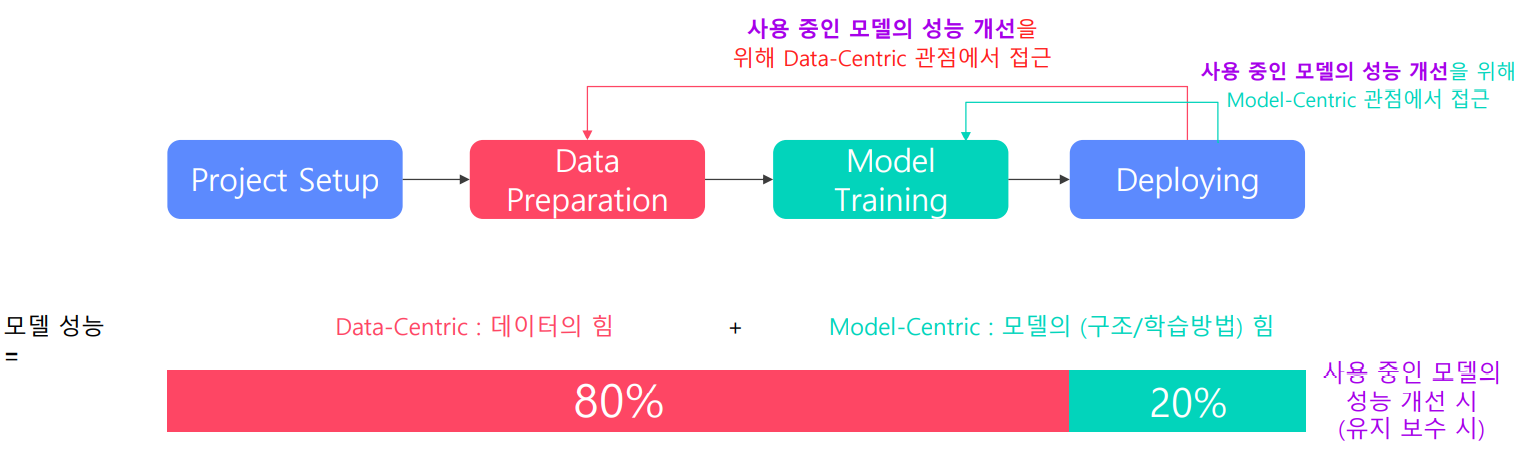
Production Process of AI Model
서비스향 AI 모델 개발 과정은 크게 4가지 단계로 구성되어 있습니다.
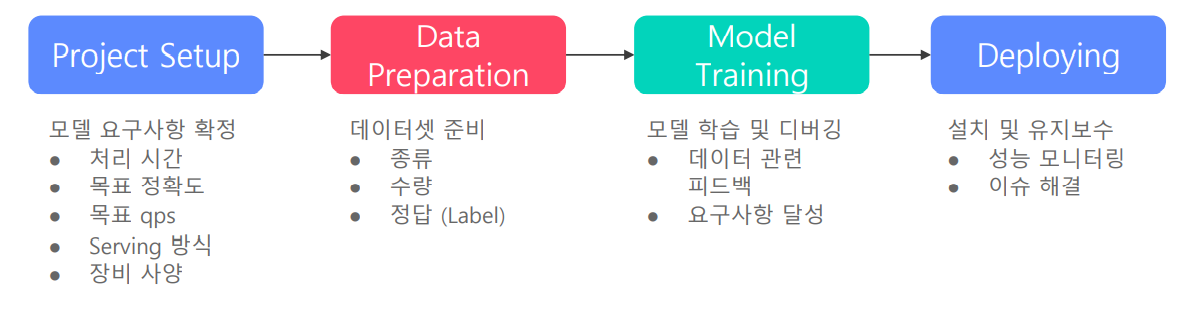
위와 같은 개발 과정에서의 목표는 요구사항을 충족할 수 있는 지속 가능한 모델을 설계하는 것입니다. 이와 같은 목표를 이루기 위해서 2가지 방법이 존재합니다.
- 데이터만 수정하여 모델 성능을 끌어올리는 방법 : Data-Centric
- 데이터는 고정시키고 모델 성능을 끌어올리는 방법 : Model-Centric
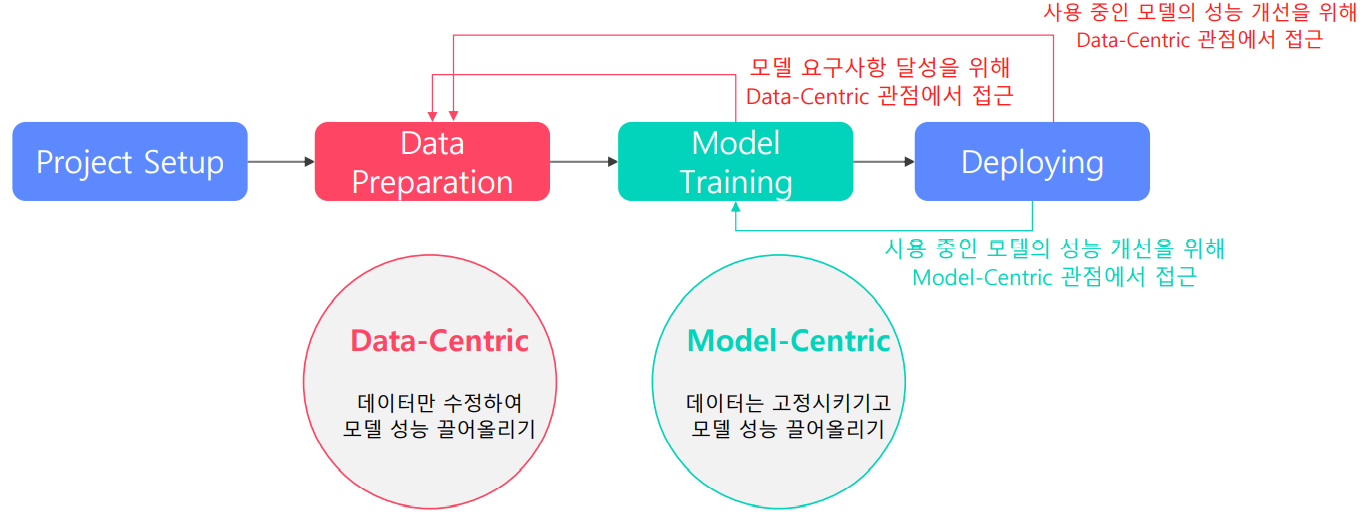
모델 성능 달성에 있어서 데이터, 모델의 비중은 어떻게 될까요? (Deploy 전) why? 모델의 요구사항을 맞추기 위해 모델의 최적화와 데이터 셋 모두 중요합니다.
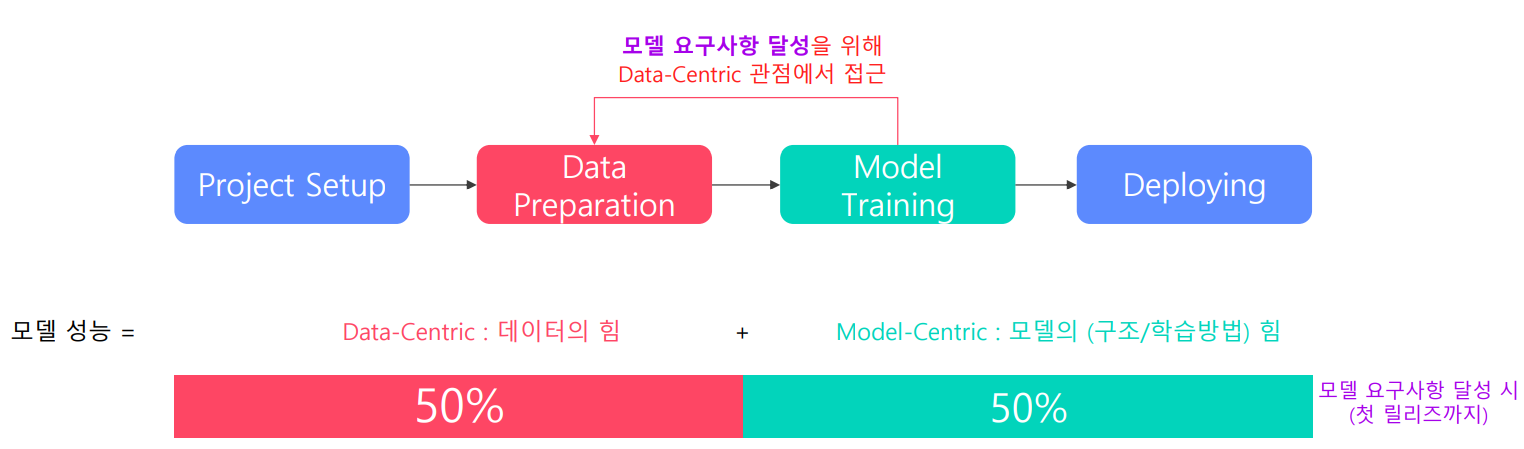
모델 성능 달성에 있어서 데이터, 모델의 비중은 어떻게 될까요? (Deploy 후) why? 모델 구조를 바꾼다면, 비용이 커집니다.
Data!
데이터 라벨링 중요!