[네이버 부스트 캠프] AI-Tech - Lv2 week8(3)
학습기록 - 57
1. 강의 복습 내용
1.1 HRNet의 필요성
HRNet의 경우, 성능적인 측면에서 좋습니다. Cityscape 대회에서도 충분히 우수한 성적을 보였고, 현재 여러 연구 분야에서도 HRNet을 기반으로 upgrade하는 모델들을 많이 연구하기 시작했습니다.
이번에는 이 중에서 Deep High-Resolution Representation Learning for Visual Recognition (HRNetv2) 를 살펴보려 합니다.

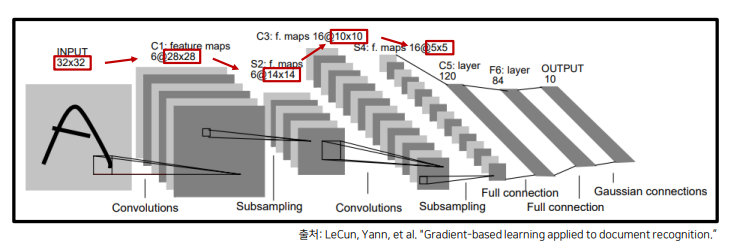
Image Classification Networks의 발전의 시작 : LeNet
다음과 같이 고해상도 이미지로부터 conv & pooling 연산을 반복하며 저해상도 feature을 생성했습니다.
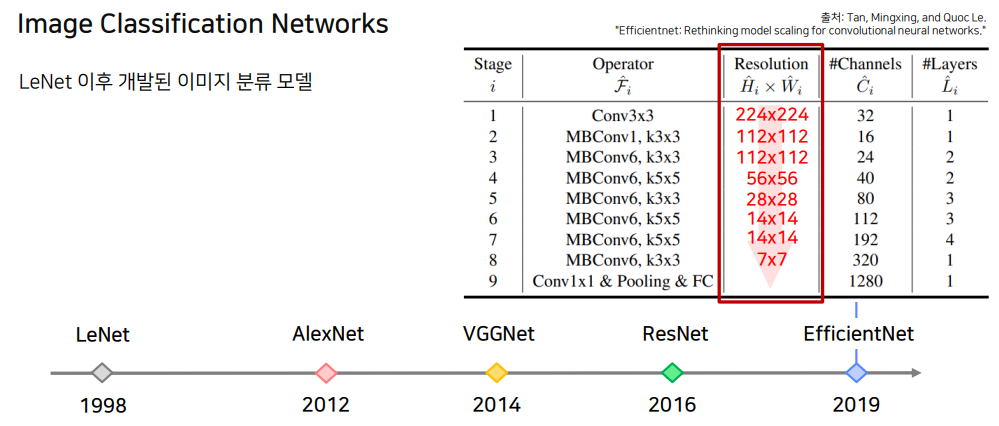
LeNet 이후 개발된 이미지 분류 모델은 다음과 같이 연대기를 거쳐왔습니다.
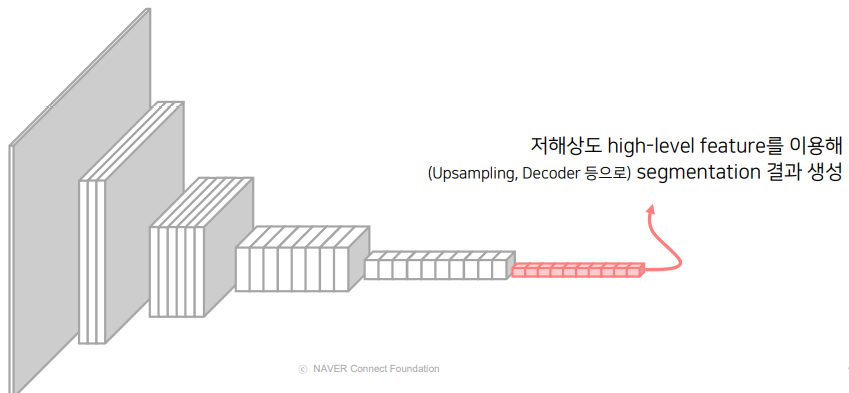
위와 같은 Network들은 공통적으로 고해상도 입력을 점차 저해상도로 줄여나가는 설계 방식을 이용했습니다.
Segmentation 연구에서는 Image-classification backbone을 기준으로 저해상도 high-level feature를 이용해서 segmentation 결과를 생성했습니다.
여기서 Image Classification 모델의 해상도를 줄여가는 이유?
- 특정 물체를 분류하는데 이미지 내 모든 특징이 필요하지 않음
- 해상도가 줄어 효율적인 연산 가능, 넓은 receptive field를 갖게 됨
- 중요한 특징만을 추출 (by maxpooling) 하여 overfitting 방지
Image classification vs Semantic Segmentation (차이점)
- 이미지 분류 모델은 공간적 정보 고려 x,
Segmentation은 예측하려는 각 픽셀 주변의 context 파악을 위한 공간 상의 위치 정보가 중요 - 중요 특징을 추출하기 위해 수행하는 pooling 등의 연산은,
모든 픽셀에 대해 정확히 분류하기에 자세한 정보를 유지하지 못함. - 즉, Segmentation에서는 더 높은 해상도를 유지해서 자세한 정보를 유지할 필요가 있습니다.
Revisit : DeconvNet, SegNet, U-Net
-
저해상도 특징을 생성하고, 다시 고해상도로 복원하는 방식의 기존 연구입니다.
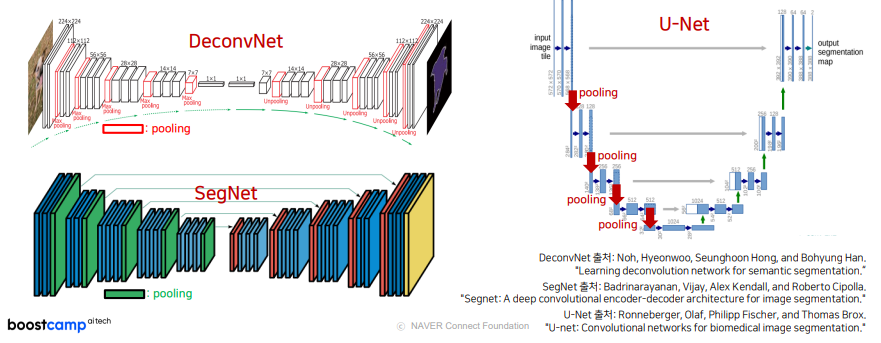
U-Net의 경우 down-sampling 과정을 진행한 후, 다시 Upsampling을 하면서 이전 feature map을 crop하게 되는데 여기서 고해상도로 복원하는 과정은 Sparse한 feature map을 생성한다는 문제점을 가지고 있습니다.
Revisit : DilatedNet, DeepLab
-
DeepLab의 경우, 위에 나타난 Sparse feature map의 문제점을 막기 위해서 dilated convolution을 사용해서 Dense feature map을 추출하도록 했습니다.
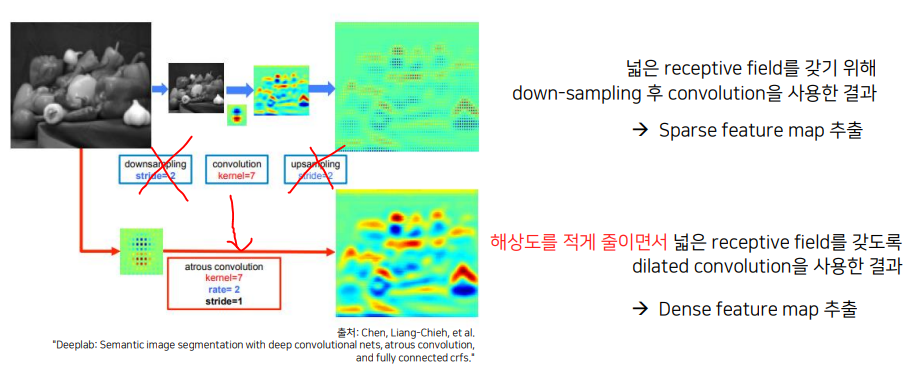
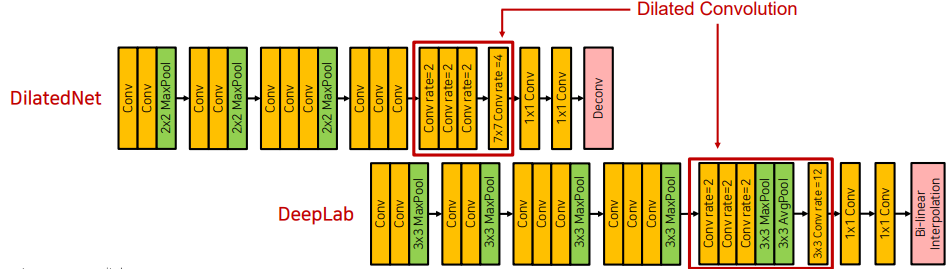
- DilatedNet 및 DeepLab 구조는 해상도의 이점을 위해 dilated conv를 이용했습니다.
- 저해상도가 아닌 중해상도 (1/8만큼) 정보를 고해상도로 복원했습니다.
-
둘의 차이점은 Deconv (Transposed Convolution) 와 Bi-linear interpolation의 차이가 있습니다.
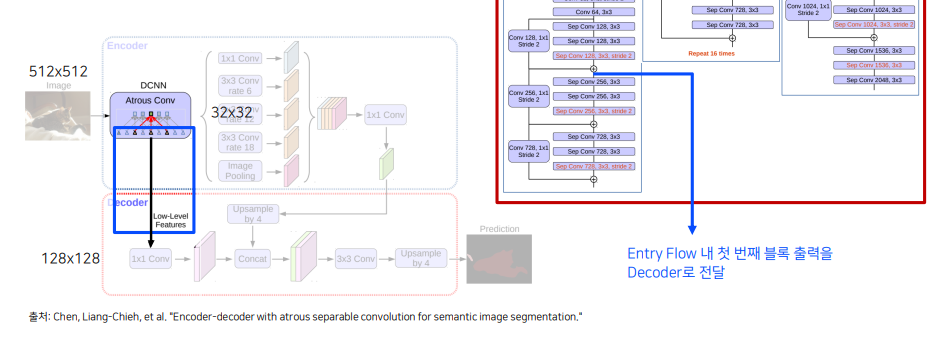
Revisit : DeepLab v3+
- Encoder-Decoder의 장점과 dilated conv의 장점을 모두 가져온 구조입니다.
-
자세한 정보를 유지하기 위해서 Xception 구조 내 max-pooling 연산을 depthwise separable conv (stride2) 로 변경했습니다.
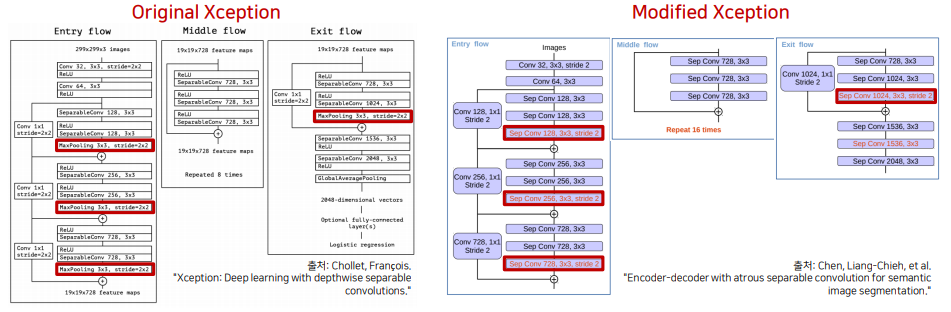
-
기존의 Encoder-Decoder 구조처럼 low-level feature를 이용해서 skip-connection을 하는 것 또한 적용 -> down-sampling 과정에서 잃어버린 정보를 복원해주는 것과 같은 역할을 해준다.
Revisit : Previous Segmentation Networks (위의 내용 정리)
- DeconvNet, SegNet, U-Net
- 여러 번의 pooling 연산을 통한 저해상도 정보를 활용
- DilatedNet, DeepLab
- Dilated Convolution 적용 or pooling 연산을 제거해서 중해상도 정보를 활용
Revisit : Classification based Networks (backbone)
Deconvnet - vgg16
segnet - vgg16 + full connected layer 제거
DilatedNet, DeepLabv1 - Network 수정 -> Maxpooling 연산 제거 or 연산 변경 (stride, padding 조절)
Deeplabv3++ - modified xception + stride2 conv -> stride1 conv (해상도 변화 x )
- 문제점 1) 기존 classification Network 사용에 필요했던 높은 time complexity
- 문제점 2) Upsampling을 이용해 저해상도 -> 고해상도로 복원했을 때, 위치정보의 민감도가 낮다.
-> 위의 문제들을 해결하기 위해서 강력한 위치 정보를 갖는 visual recognition 문제에 적합한 구조가 필요
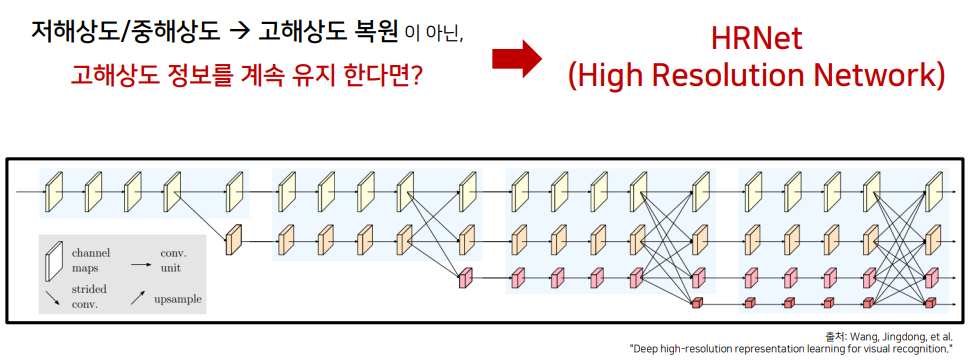
결국엔 저/중해상도 -> 고해상도 복원이 아닌 고해상도를 계속 유지하는 Network를 만들기 위해 고안해낸 방법이 HRNet (High Resolution Network) 입니다.
HRNet 같은 경우, image classification에서 사용하는 backbone network가 아닌 위치 정보가 중요한 visual recognition 문제에 사용할 수 있는 새로운 backbone network 입니다.
2. HRNet 구조
2.1 HRNet의 구성 요소
HRNet (High Resolution Network)
- 구성요소 1. 전체 과정에서 고해상도 특징을 계속 유지
-
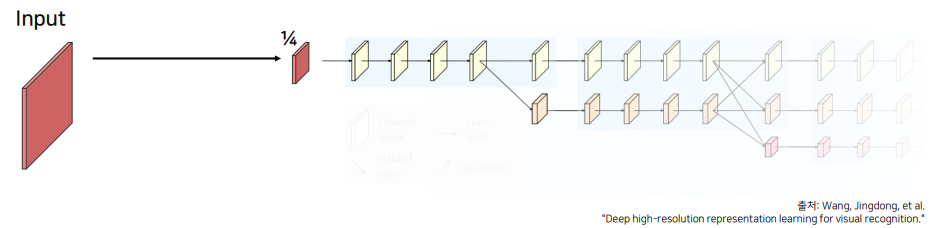
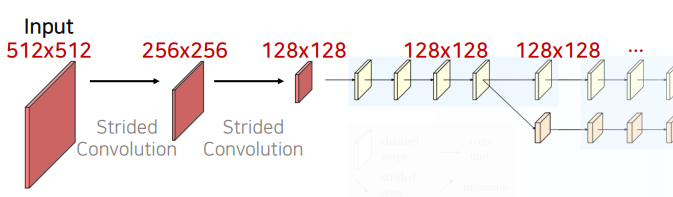
입력 이미지를 그대로 이용하는 것이 아닌 Strided Convolution을 이용해 해상도를 1/4로 줄임 -> 계속 유지
-
1/4로 만드는 것은 1/2씩 strided Convolution을 이용해서 resolution을 맞춰줍니다.
-
왜 High Resolution 이라고 하는 것일까?
다른 모델에 비해 고해상도를 계속 유지하고 있는 것 (U-Net : 1/20, DeepLab v3+ : 1/16)
-
2.2 다중 해상도 정보 생성 및 병렬 처리
- 구성요소 2. 고해상도 ~ 저해상도까지 다양한 해상도를 갖는 특징을 병렬적으로 연산
- 기존의 경우, Receptive field를 넓히거나 연산의 효율을 위해서 Image의 크기를 줄였습니다.
그렇게 된다면 고해상도를 유지하기 위해서는 많은 연산량이 필요하고 receptive field 또한 작았을 것입니다. -
다양한 해상도의 병렬화를 통해 Receptive field의 문제에 대해서 해결하려고 시도했습니다.
저해상도는 차원을 크게, 고해상도는 차원을 작게 만들어서 효율적인 연산을 고안해냈습니다.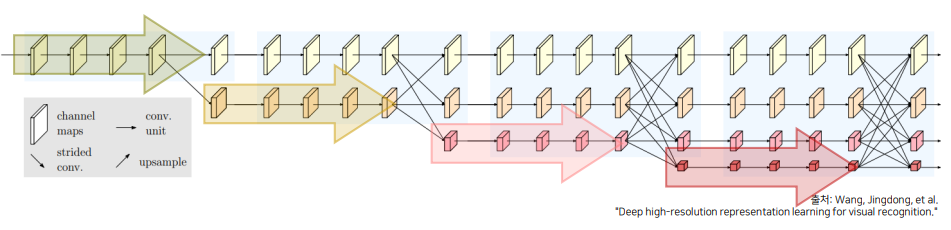
-
아래와 같이 새로운 stream이 생성될 때마다 이전 단계 해상도의 1/2로 감소합니다.
이를 통해, 넓은 receptive field를 갖는 특징을 고해상도 특징과 함께 학습합니다.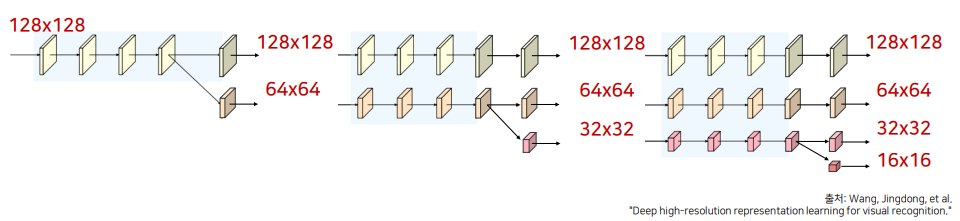
- 기존의 경우, Receptive field를 넓히거나 연산의 효율을 위해서 Image의 크기를 줄였습니다.
2.3 다중 해상도 정보의 반복적 융합
- 구성요소 3. 다중 해상도 정보를 반복적으로 융합
- 각각의 해상도가 갖는 정보를 다른 해상도 stream에 전달하여 정보를 융합
- 고해상도 : 공간 상의 높은 위치 정보 민감도
- 저해상도 : 넓은 receptive field로 인해 상대적으로 풍부한 semantic information을 가짐 (조금 더 detail한 information을 가진다.)
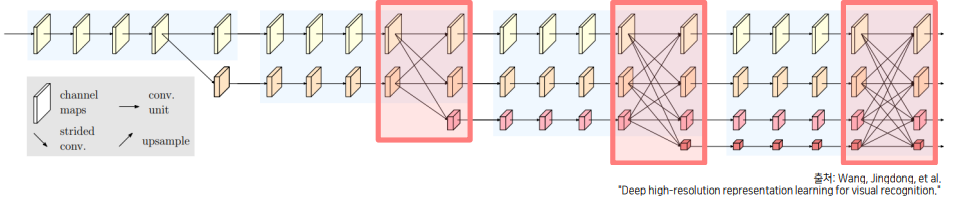
-
고해상도 -> 저해상도 : Strided Conv (정보 손실 최소) 저해상도 -> 고해상도 : Bilinear Upsampling + 1x1 Conv (Time Complexity & 채널 수)
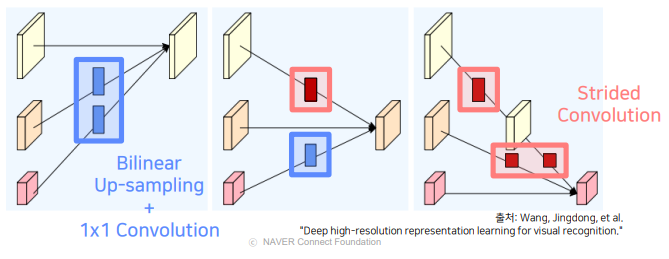
- 각각의 해상도가 갖는 정보를 다른 해상도 stream에 전달하여 정보를 융합
2.4 다양한 종류의 출력 생성
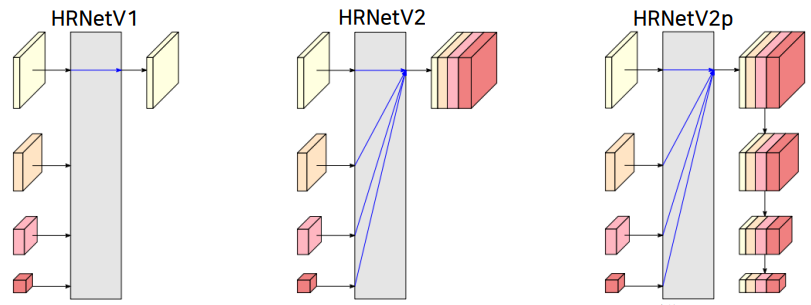
-
HRNetV1 : 저해상도를 제외한 고해상도 특징만을 최종 출력으로 사용 (ex. Pose Estimation)

-
HRNetV2 : 저해상도 특징들을 bilinear upsampling을 통해 고해상도 크기로 변환 후 모든 특징들을 합하여 출력 (ex. Semantic Segmentation)

-
HRNetV2p : HRNetV2의 결과에서 추가로 down sampling한 결과 출력, Faster-RCNN등의 backbone으로 사용 (ex. object detection)

2.5 정리
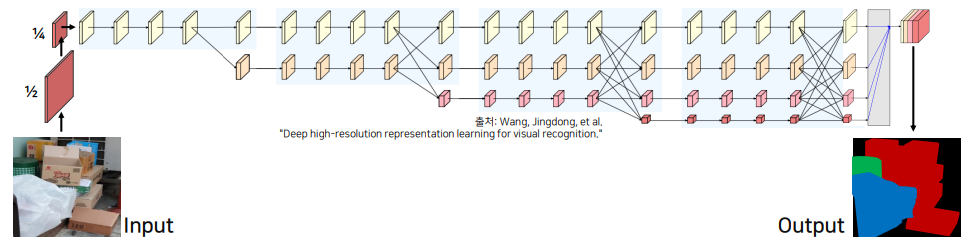
HRNet for Semantic Segmentation
1) 입력 이미지는 1/4 해상도를 가짐
2) 1/4 해상도 유지 + 새로운 저해상도 생성 및 서로의 정보 융합
3) 모든 해상도 정보를 합한 후, 각 해상도를 representation head 내에서 bilinear upsampling 진행, Concat 후, Segmentation Head를 통과해서 Segmentation 수행
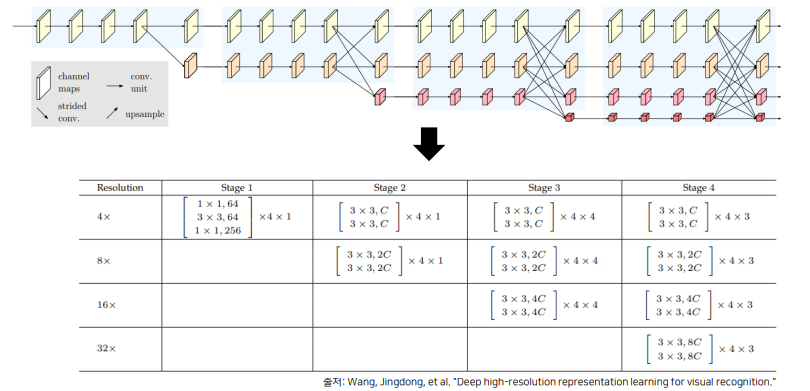
3. HRNet의 세부 구조 및 구현
HRNet의 경우, Residual Unit으로 구성된 block 구문이 반복되는 것을 볼 수 있습니다.
4x라는 뜻은 4를 곱해야 원본 이미지가 될 수 있다라는 뜻으로 원본 이미지의 1/4 만큼의 해상도를 갖고 있습니다.
각 Stage, 해상도 별로 Residual Unit이 몇 번 반복되는 지 알 수 있습니다.
여기서 C는 가장 높은 해상도 stram의 채널 수를 의미합니다. 그리고 이 C에 따라서 모델의 이름이 정해집니다.
# W(width) = C(Channel)
HRNetV2-W18 # C = 18
HRNetV2-W32 # C = 32
HRNetV2-W40 # C = 40
HRNetV2-W48 # C = 48
(질문) H, W가 각각 2로 나눈다면, 해상도가 안맞지 않나? (ppt)
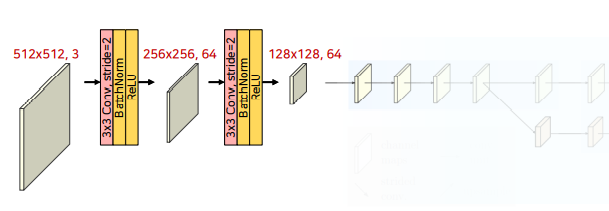
-
Stem in HRNetV2-W48
512x512 입력, 채널 수 48일 때의 예시입니다.
아래 코드와 같이
채널은 3에서 64로 만들어 주고, kernel_size와 stride를 통해서 해상도를 줄여주는 것을 볼 수 있습니다.Code
class StemBlock(nn.Module): def __init__(self): super().__init__() self.block = nn.Sequential( nn.Conv2d(in_channels, 64, kernel_size=1, bias=False), nn.BatchNorm2d(64), nn.ReLU(), nn.Conv2d(64, 64, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU() ) -
Stage1 in HRNetV2-W48
-
Stage1은 이전에 봤듯이, 1x1,64 -> 3x3,64 -> 1x1,256 이 Residual Unit이 4번 반복되는 것을 볼 수 있습니다.
-
여기서 알아야할 점은 skip-connection을 적용하는 데 입력 채널과 출력 채널이 맞지 않기 때문에 1x1 Conv를 적용하게 됩니다.
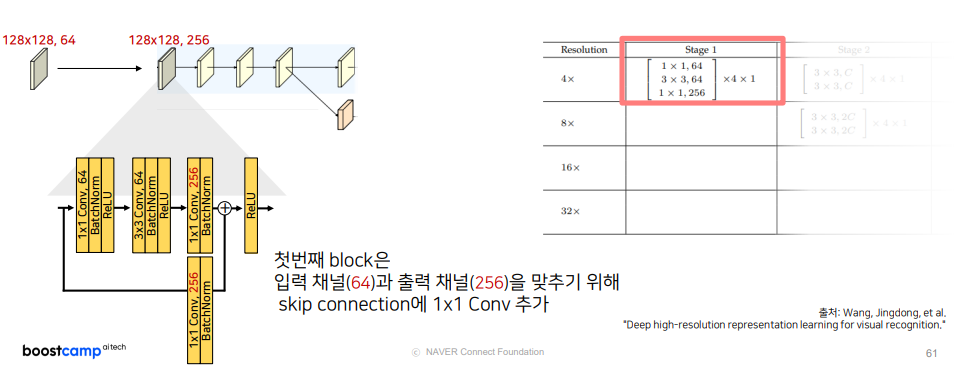
Code
class Stage01Block(nn.Module): def __init__(self): super().__init__() # Residual Unit self.block = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU(), nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU() nn.Conv2d(64, 256, kernel_size=1, bias=False), nn.BatchNorm2d(256), nn.ReLU() ) # skip-connection if in_channels == 64: self.identity_block = nn.Sequential( nn.Conv2d(in_channels, 256, kernel_size=1, bias=False), nn.BatchNorm2d(256), ) self.relu = nn.ReLU() self.In_channels = in_channels def forward(self, inputs): identity = inputs out = self.block(inputs) if self.in_channels == 64: identity = self.identity_block(identity) out += identity return self.relu(out) -
이후, 두번째 이상의 block부터도 동일한 과정을 거칩니다. 단, Input의 채널 수가 256으로 동일하기 때문에 skip connection에서 1x1 conv 과정이 적용되지 않습니다.
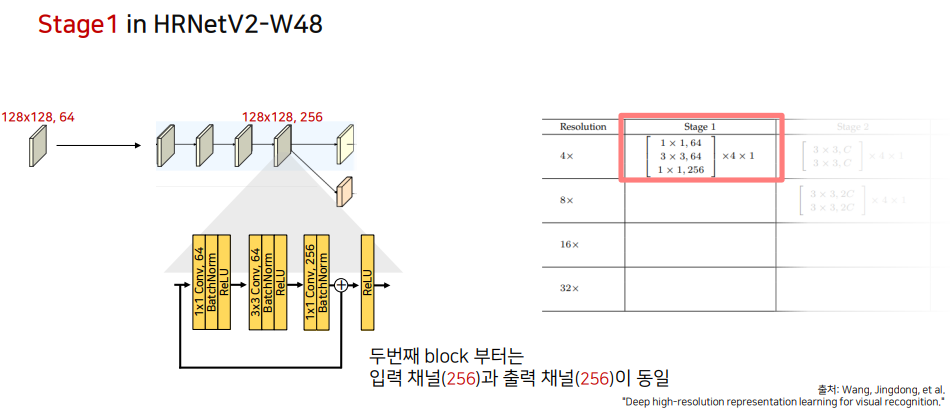
-
4번의 Residual Unit 과정이 끝난 후, Strided Conv를 통해서 새로운 하위 stream을 생성합니다.
생성된 stream의 해상도는 이전 단계의 1/2로 감소, 채널 수는 2배 증가합니다.
이 단계부터는 가장 높은 해상도 Stream의 채널 수를 48로 설정합니다. (W48)Code
class Stage01StreamGenerateBlock(nn.Module): def __init__(self): super().__init__() # change channel, high--> high self.high_res_block = nn.Sequential( nn.Conv2d(256, 48, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(48), nn.ReLU() ) # make stream, high -> low self.medium_res_block = nn.Sequential( nn.Conv2d(256, 96, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(96), nn.ReLU() ) def forward(self, inputs): out_high = self.high_res_block(inputs) out_medium = self.medium_res_block(inputs) return out_high, out_medium
-
- Stage2 in HRNetV2-W48
-
두번째 Stage부터는 해상도와 채널을 유지하면서 4번의 반복 연산을 하게 됩니다.
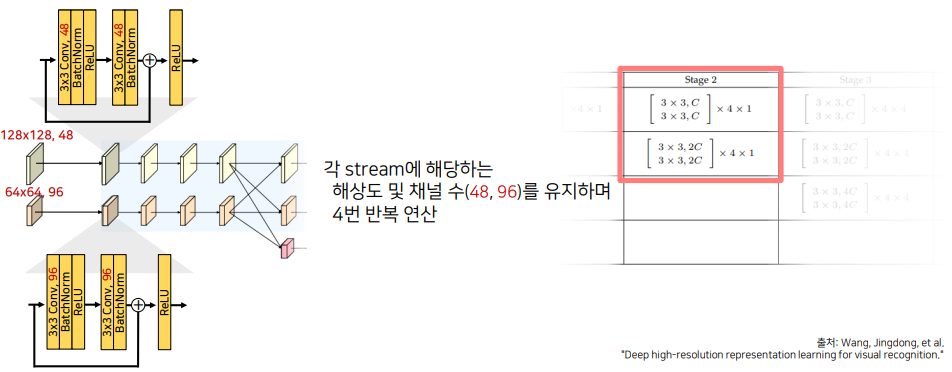
Code
class StageBlock(nn.Module): def __init__(self, in_channels): super().__init__() self.block = nn.Sequential( nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(in_channels), nn.ReLU(), nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(in_channels) ) self.relu = nn.ReLU() def forward(self, inputs): identity = inputs out = self.block(inputs) out += identity out = self.relu(out) return outclass Stage02(nn.Module): def __init__(self): super().__init__() # 4번 반복 high_res_blocks = [StageBlock(48) for _ in range(4)] medium_res_blocks = [StageBlock(96) for _ in range(4)] self.high_res_blocks = nn.Sequential(*high_res_blocks) self.medium_res_blocks = nn.Sequential(*medium_res_blocks) def forward(self, inputs_high, inputs_medium): out_high = self.high_res_blocks(inputs_high) out_medium = self.medium_res_blocks(inputs_medium) return out_high, out_medium -
이후, 상위 Stream은 하위 stream을 생성하게 되고, 하위는 상위를 생성합니다.
상위 생성 : Bilinear upsampling & 1x1 Conv
새로운 stream의 해상도 : 이전 단계 해상도의 1/2로 감소 및 채널 수 2배 증가 -
여기서 HRNet의 공식 구현은 논문과 다른 양상을 보여줍니다.
해당 이슈에서 저자의 말은 다음과 같았습니다.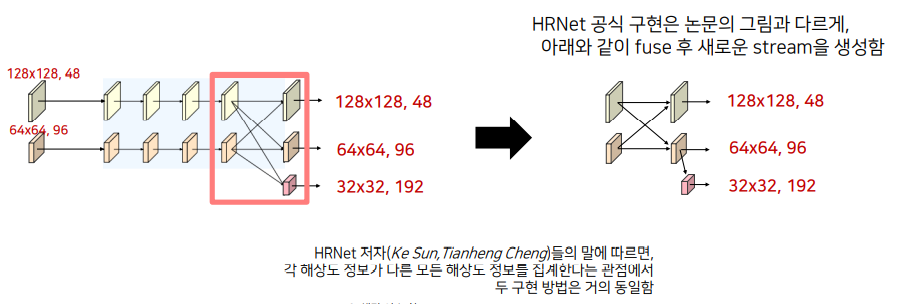
Code
class Stage02Fuse(nn.Module): def __init__(self): super().__init() # high -> medium self.high_to_medium = nn.Sequential( nn.Conv2d(48, 96, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(96) ) # medium -> high self.medium_to_high = nn.Sequential( nn.Conv2d(256, 96, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(96), nn.ReLU() ) self.relu = nn.ReLU() def forward(self, inputs_high, inputs_medium): high_size = (inputs_high.shape[-1], inputs_high.shape[-2]) # 논문에 나온 코드 방식은 interpolate -> 1x1 conv med2high = F.interpolate( inputs_medium, size=high_size, mode="bilinear", align_corners=True ) med2high = self.medium_to_high(med2high) # 구현 코드에서는 위에 구현된 논문과는 다른 방식으로 적용한다. # 1x1 conv -> interpolate... / why? Computational Complexity 감소 효과 # (이슈참고) https://github.com/HRNet/HRNet-Semantic-Segmentation/issues/115 med2high = self.medium_to_high(med2high) med2high = F.interpolate( med2high, size=high_size, mode="bilinear", align_corners=True ) high2high = self.high_to_medium(inputs_high) # concat이 아닌 sum을 진행한다. out_high = inputs_high + med2high out_medium = inputs_medium + high2med out_high = self.relu(out_high) out_medium = self.relu(out_medium) return out_high, out_mediumclass StreamGenerateBlock(nn.Module): def __init__(self, in_channels): super().__init__() # medium -> low (fuse 후 진행) self.block = nn.Sequential( nn.Conv2d(in_channels, in_channels*2, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(in_channels*2), nn.ReLU() ) def forward(self, input): return self.block(inputs)
-
-
Stage3 in HRNetV2-W48
-
Stage3는 다음 강의 슬라이드와 같습니다.
마지막 작은 Conv는 16x16, 384 로 이전 단계에서 했던 방식과 같습니다.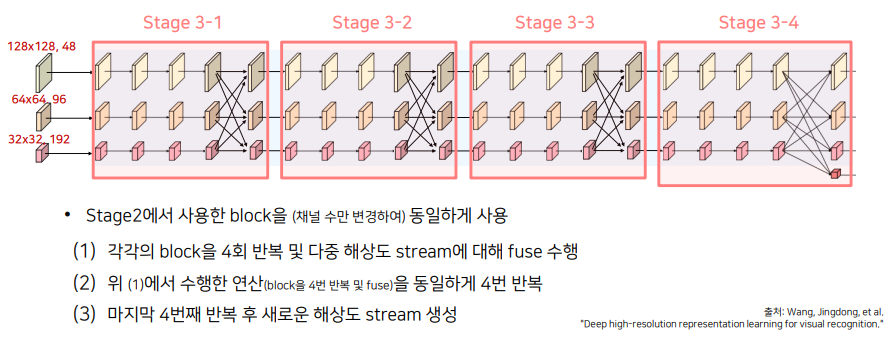
-
코드 구현은 생략하고, 세부 구조에 대해 보면 이전에 Stage에서 진행했던 방식과 같은 방식입니다.

-
-
Stage4 in HRNetV2-W48
-
Stage4에서는 Stage3에서 했던 내용과 전반적으로 동일하고, 반복 횟수를 4->3으로 줄였습니다.
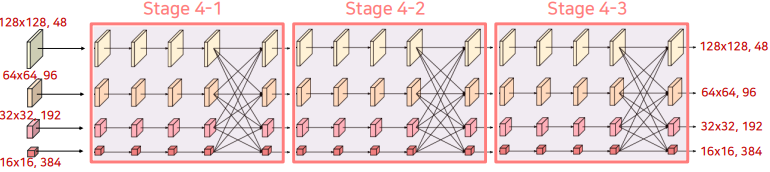
-
-
Representation Head in HRNetV2-W48
-
Representation Head는 모든 특징들을 고해상도 특징에 맞추기 위해 bilinear upsampling을 해주고 concat을 시켜줍니다. 1x1 conv 2번 (or 3x3 conv) 을 해서 최종 num_classes 채널을 생성하고 다시 Bilinear Upsampling을 통해 출력을 생성합니다.

Code
class LastBlock(nn.Module): def __init__(self, num_classes): super().__init__() total_channels = 48 + 96 + 192 + 384 self.block = nn.Sequential( nn.Conv2d(total_channels, total_channels, kernel_size=1, bias=False) nn.BatchNorm2d(total_channels), nn.ReLU(), nn.Conv2d(total_channels, num_classes, kernel_size=1, bias=False) ) def forward(self, inputs_high, inputs_medium, inputs_low, inputs_vlow): high_size = (inputs_high.shape[-1], inputs_high.shape[-2]) original_size = (high_size[0]*4, high_size[1]*4) med2high = F.interpolate(inputs_medium, size=high_size, mode="bilinear", align_corners = True) low2high = F.interpolate(inputs_low, size=high_size, mode="bilinear", align_corners = True) vlow2high = F.interpolate(inputs_vlow, size=high_size, mode="bilinear", align_corners = True) out = torch.cat([inputs_high, med2high, low2high, vlow2high]) out = self.block(out) out = F.interpolate(out, size=original_size, mode="bilinear", align_corners=True) return out
-
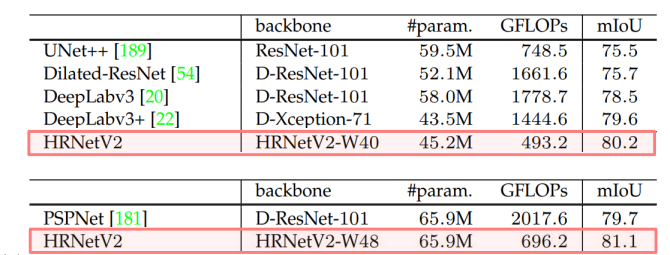
4. HRNet의 실험결과
모델 크기 (#param.), 계산 복잡도(GFLOPs)에 따른 성능 (mIoU) 비교