
[네이버 부스트 캠프] AI-Tech - Lv2 week7(3)
학습기록 - 53
1. 강의 복습 내용
이전 강의
FCN, Encoder, Decoder는 5개의 Max pooling을 통해 1/32만큼 줄이고 원본으로 키우고
DilatedNet, DeepLab-LargeFOV는 1/8만큼 줄이고 원본으로 키웠습니다.
여기에서 새로운 Architecture DeepLabv2를 제안합니다..
DeepLabv2
DeepLabv2부터는 conv5에서 Average Pooling 부분이 제거, FC6~FC8이 서로 다른 4개의 Dilated Convolution를 취합니다. ASPP(Atrous Spatial Pyramid Poolings) 방식을 적용해서 서로 다른 layer들에 대해서 summation을 합니다.
서로 다른 Object들을 (큰 object, 작은 object) 모두 파악할 수 있습니다.
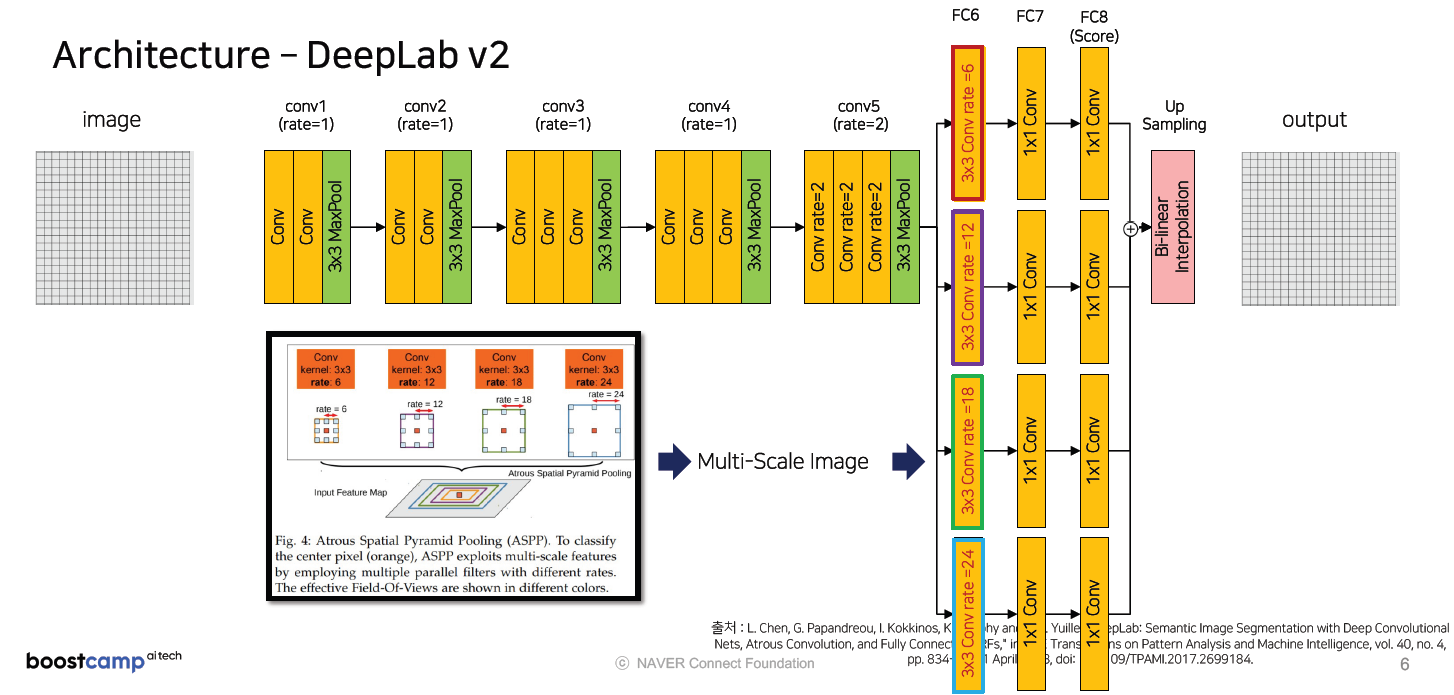
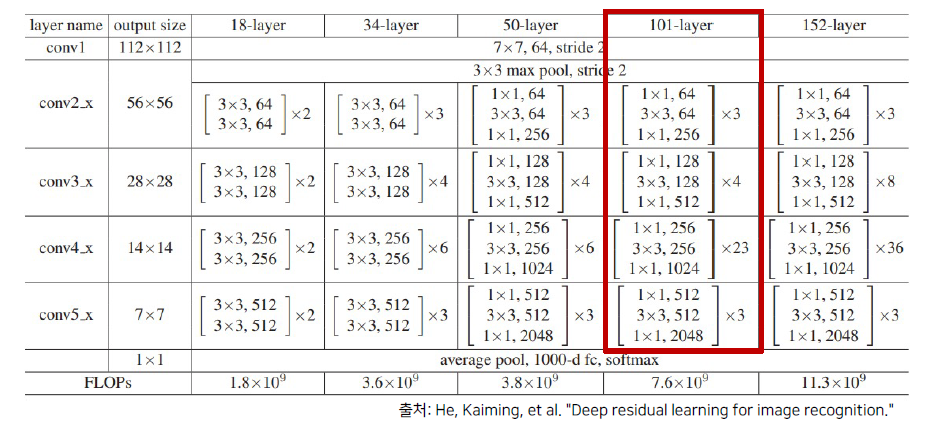
DeepLab v2는 더 높은 성능 향상을 위해서 ResNet-101 구조를 사용했습니다.(이전엔 VGG16을 사용)
Conv1 block은 다음과 같이 padding = 3, stride = 2 의 Convolution과 BatchNorm, ReLU 연산을 진행한다. 다음과 같은 연산을 통해서 Image size가 256x256으로 줄어들게 됩니다.
conv1_block = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_features=64),
nn.ReLU()
)

그 후, 이전과 동일하게 Maxpool을 통해서 2배만큼 더 감소시켜 줍니다. stride = 2, padding = 1
maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
다음 conv2_x (conv2 block)의 구성은 다음과 같습니다.
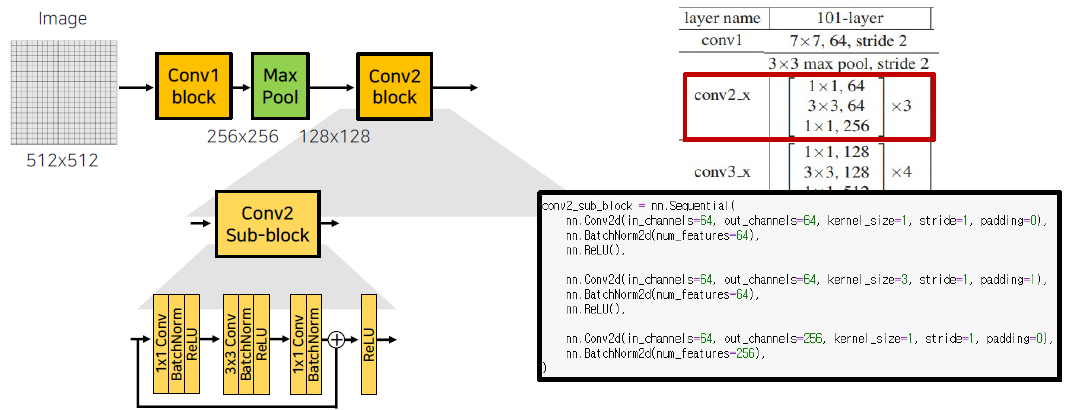
이 때, Input channel과 Output Channel의 수가 서로 맞지 않게 됩니다. 채널 수를 맞추기 위해서 skip-connection 사이에 1by1 Conv를 추가합니다. (64 -> 256)

이러한 sub-block은 처음 skip-connection 사이를 제외하고 나머지 block은 입력 채널과 출력 채널이 같이 때문에 convolution 추가 없이 2회 더 반복해서 총 3회 수행하도록 합니다.
conv3_x (conv3 block)의 구성 또한 동일합니다. 128x128 이미지의 해상도를 stride=2를 통해 down-sampling을 수행하고, 크기와 채널 수를 맞추기 위해서 stride=2 1x1 Conv 연산을 추가하게 됩니다.
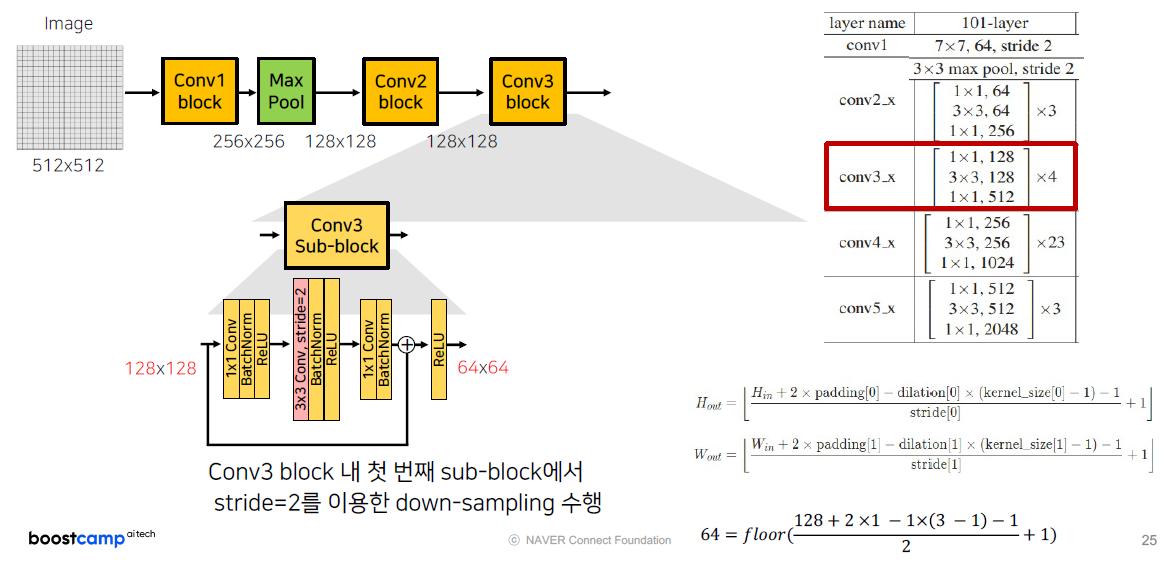
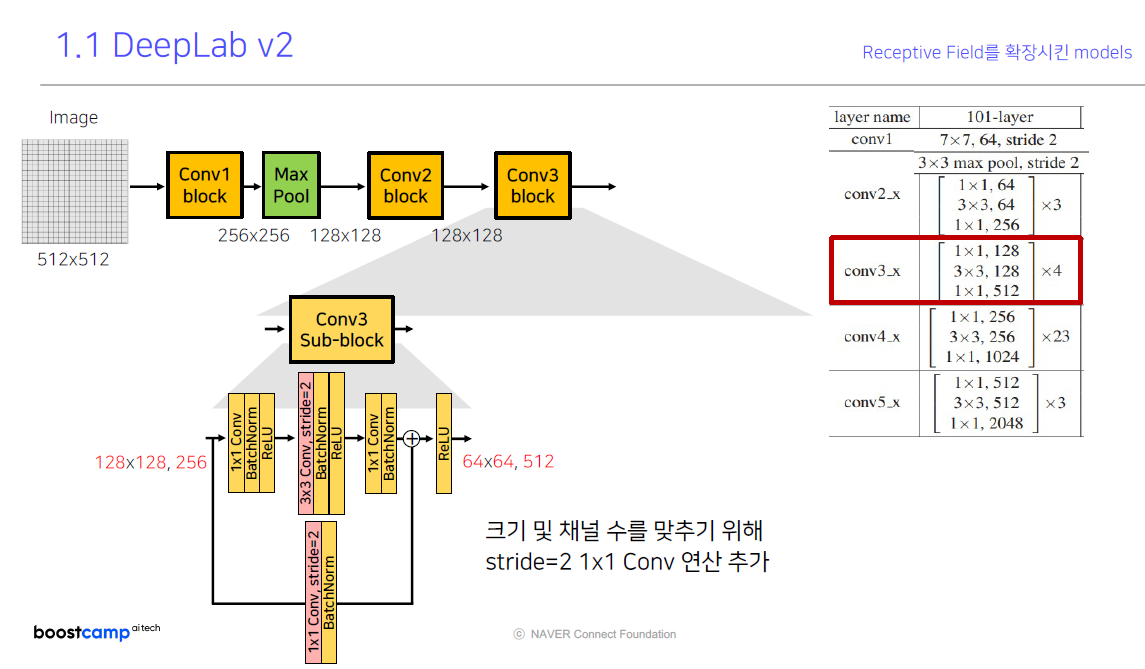
그 다음 sub-block부터는 Conv2 sub-block과 동일하게 그 다음부터 1by1 convolution이 진행하고 총 4회 진행합니다.
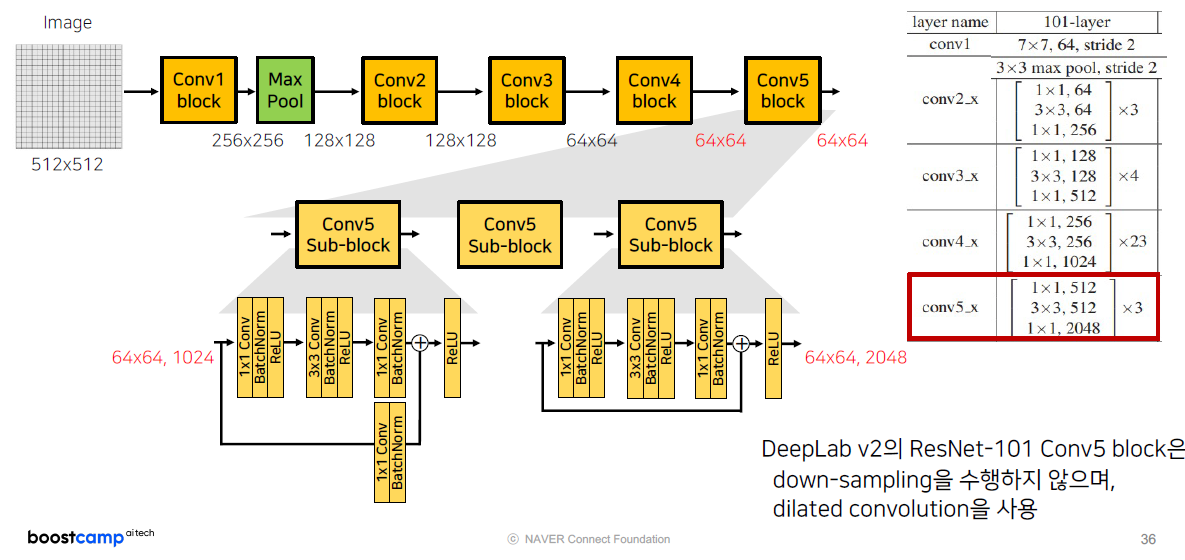
그 이후, Conv4, Conv5는 ‘Original ResNet-101’에서는 Conv3 block과 동일하게 진행했는데,
DeepLab v2의 ResNet-101 Conv4, Conv5는 Dilated Convolution을 수행해서 따로 Stride를 적용하지 않는 모습을 보여주고 있습니다.
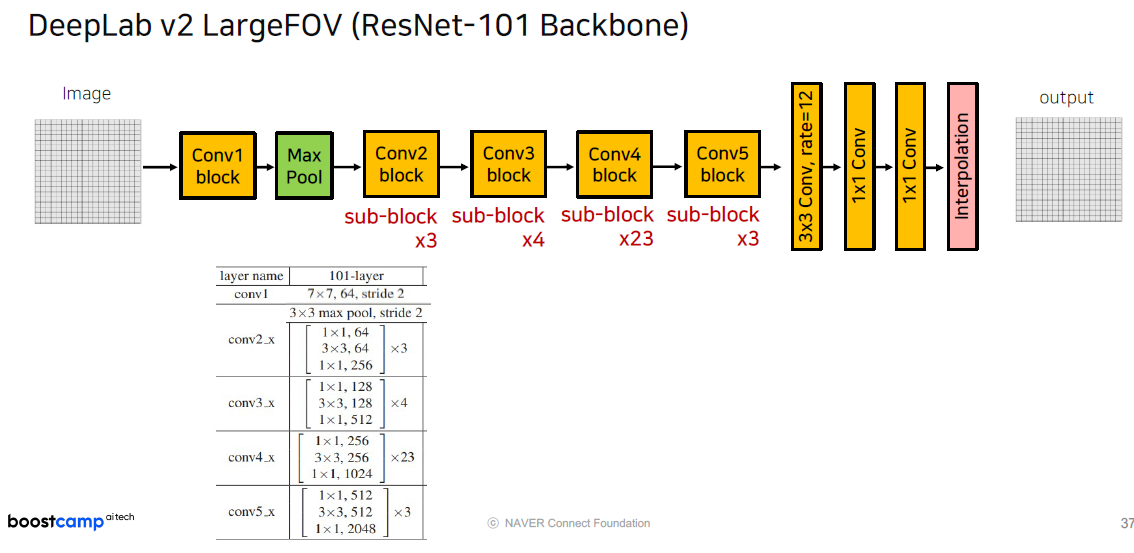
이제 ResNet-101 Backbone을 적용한 DeepLab Model의 Architecture를 비교하면 다음과 같습니다.
그와 동시에 ASPP를 이용했을 때, mIoU가 더 높게 나온다는 것을 볼 수 있습니다.

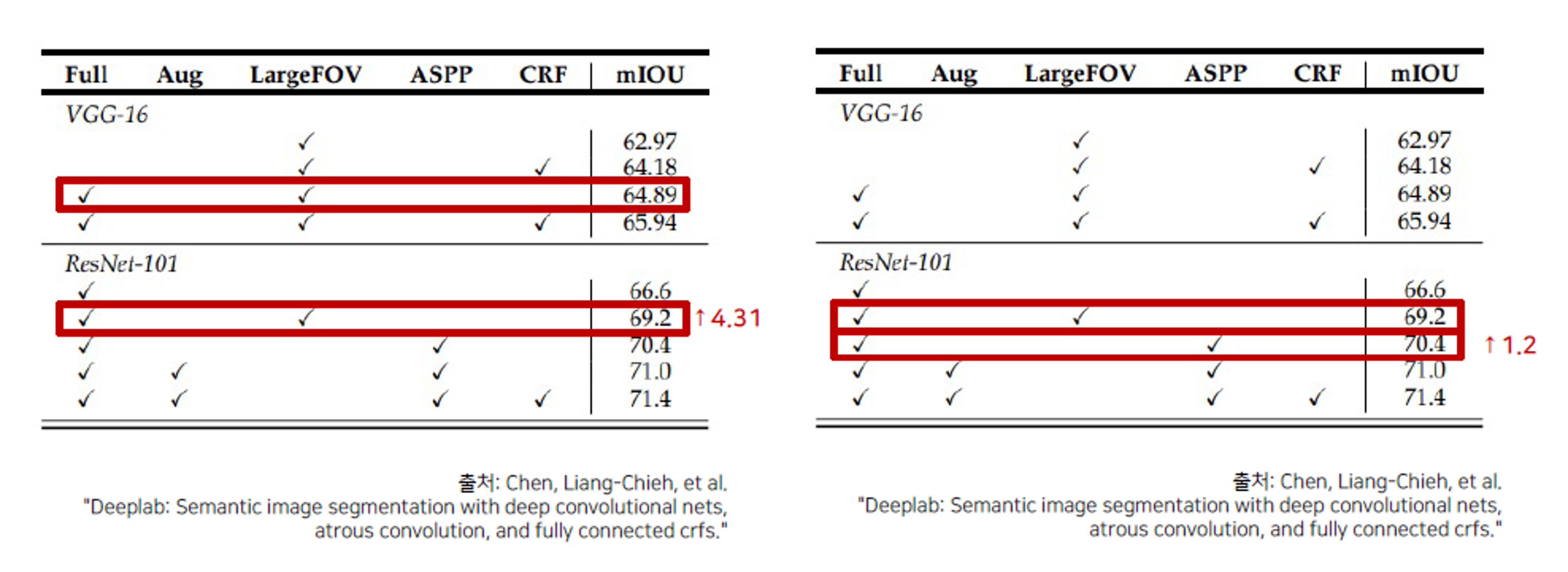
PSPNet
- 도입 배경
- Mismatched Relationship
- Confusion Categories
-
Inconspicuous Classes
-
FCN도 Receptive Field를 크게 가지고 예측을 진행했는데 왜 객체간에 관계를 파악하지 못할까?
실제 실험을 했을 때, pooling이 진행될수록 이론적인 사이즈와 실제 사이즈가 많이 다르다는 것을 보입니다..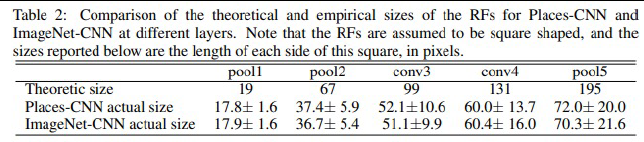
이러한 문제점을 해결하기 위해 Global Context를 갖기 위한 Global Average Pooling을 도입합니다.
-
Architecture - Pyramid Pooling Module 2
같은 feature map에 서로 다른 Average Pooling은 적용해 각기 다른 feature map을 가지도록 합니다.
(질문) 여기에 Global Average Pooling을 한 번 수행한다는 뜻인가?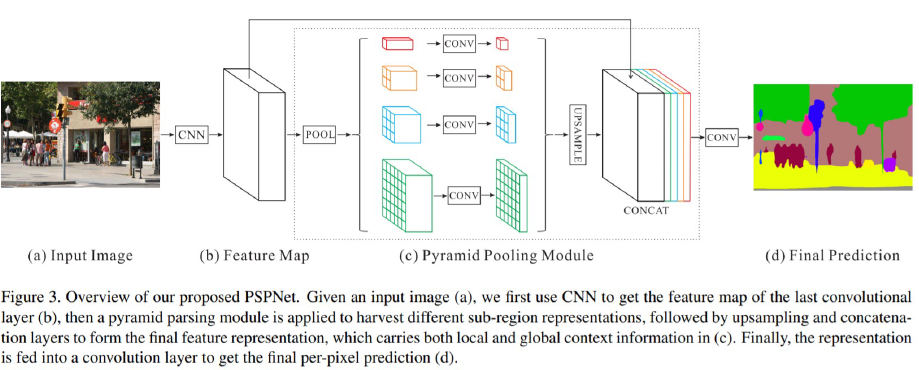
Global Average Pooling
전체 feature map을 1x1 크기의 픽셀로 이미지 전체의 정보를 평균 냅니다.
이러한 방법을 통해서 feature map의 global한 context에 대해서 더 정보를 얻을 수 있습니다. (주변 문맥 파악 가능)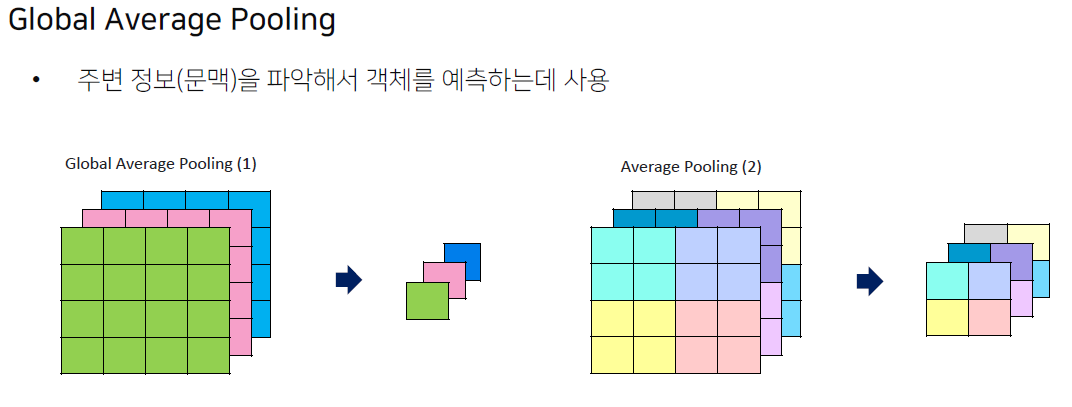
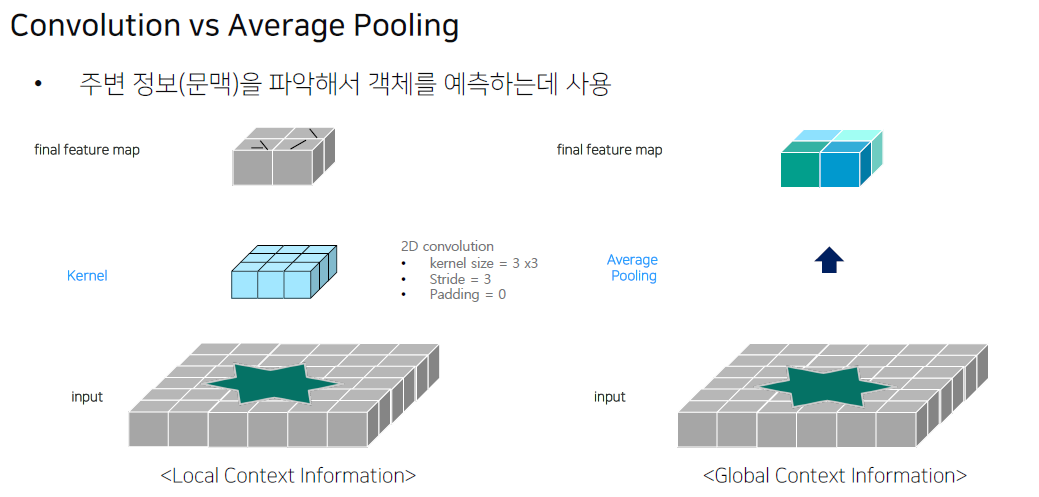
Convolution과 Average Pooling의 차이점은 다음 그림과 같습니다.
Convolution은 Object의 특징점 (외관의 모습)을 잡아서 feature map을 추출했다면,
Average Pooling은 feature map 전체적인 모습에 대해서 feature map을 추출하기 때문에 주변 정보를 파악할 수 있도록 합니다.(질문) 왜 둘을 비교하는 건지..? Convolution과 Pooling 둘 다 수행되는 게 아녔던가..?
다시 Architecture로 돌아와서 1by1 convolution을 통해서 channel을 1로 만들어줍니다.
그 후, feature map과 module에서 나온 feature map들을 upsampling을 통해 크기를 맞춰주고 Concat 할 수 있도록 한다.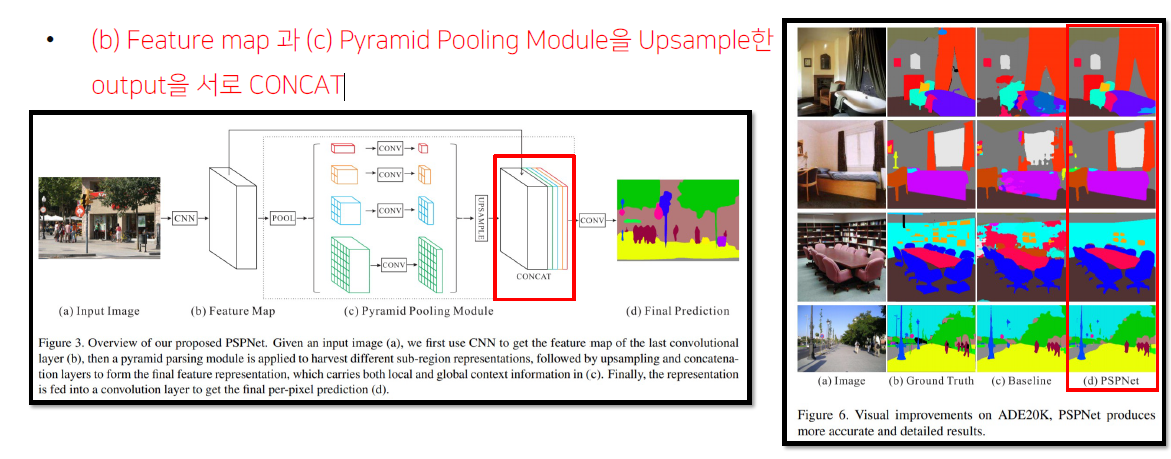
PSPNet의 결과를 이전 DeepLab과 비교했을 때, 성능이 좀 더 좋아진 것을 볼 수 있다.
DeepLab v3
이전 DeepLab v2와 다른 점은 ASPP 내에 Image Pooling (1x1의 Global Average Pooling)을 추가했습니다.
또한, 아래의 그림에서 보듯이 마지막 Dilated Convolution (Conv rate = 24) 인 layer가 없어졌고, 1by1 Convolution이 추가 되었습니다.
기존 구조는 모든 Conv layer의 output을 summation하는 구조였다면, v3는 Concat을 하게 됩니다.
(질문) 위의 모듈과 Image size가 달라진다..? global Average pooling을 통해서 만들어진 1x1 size의 feature map을 다시 크게 만든다는 건가? 그렇다면 아주 비효율적이지 않나?
DeepLab v3+
Architecture - DeepLav v3+ (Encoder-Decoder 구조 적용)
Backbone - Modified Xception을 새롭게 적용
Xception 관련 내용을 자세하게 파는 것은.. 추후에..