
[네이버 부스트 캠프] AI-Tech - Lv2 week7(2)
학습기록 - 52
1. 강의 복습 내용
FCN의 한계점
- 객체의 크기가 크거나 작은 경우 예측을 잘 하지 못하는 문제
- 큰 Object의 경우 지역적인 정보만으로 예측
- 버스 유리창에 비친 자전거를 인식하는 경우
- 같은 Object여도 다르게 labeling
- 작은 Object가 무시되는 문제가 생김
왜 그런 것일까?
Convolution 자체의 Receptive Field가 작게 잡힌다면 전체 Object에 대한 인식이 어려워지는 것 같다. - 큰 Object의 경우 지역적인 정보만으로 예측
- Object의 디테일한 모습이 사라지는 문제 발생
- Deconvolution 절차가 간단해 경계를 학습하기 어려움
Max pool을 통해서 Detail한 정보가 이미 손실되고 있는 데 단순하게 feature map을 늘려버리기 때문에, 손실된 정보를 가져올 수가 없다. (skip connection)
- Deconvolution 절차가 간단해 경계를 학습하기 어려움
DeconvNet
-
Architecture
위와 같은 FCN의 한계점을 극복하고자 Decoder와 Encoder를 대칭으로 만든 형태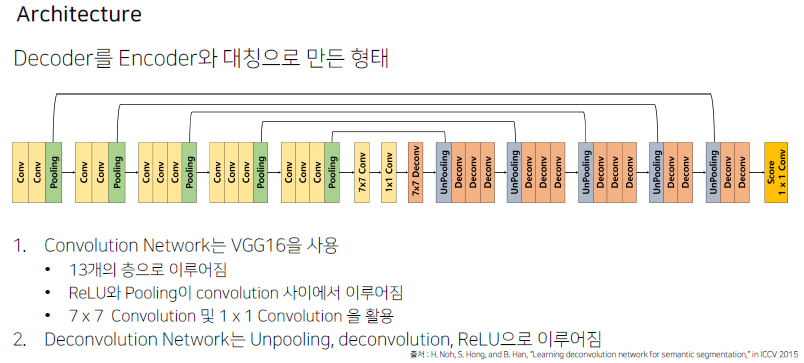
이전과 마찬가지로 Conv는 Conv-BN-ReLU 과정으로 이루어져 있습니다.
Decoder 단에는 Unpooling과 Deconv (Transposed convolution)을 가지고 있습니다. Unpooling은 Detail한 모습을 포착하고 Deconv는 전반적인 모습을 가져옵니다.