
[네이버 부스트 캠프] AI-Tech - Lv2 week7(1)
학습기록 - 51
오늘 할 일
- Semantic Segmentation의 기초와 이해
1. 강의 복습 내용
Overview
- Fully Connected Layer vs Convolution Layer
- Transposed Convolution
-
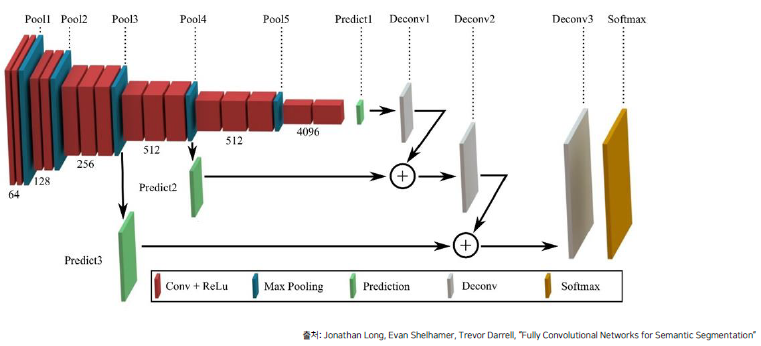
FCN에서 성능을 향상시키기 위한 방법 -> skip connection
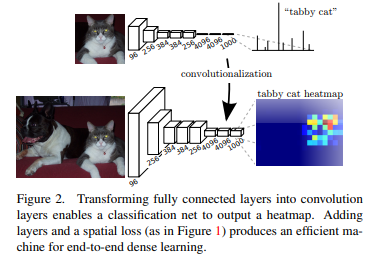
FCN
- VGG 네트워크 백본을 사용 (Backbone : feature extracting network, ex : VGG, AlexNet, ResNet, … ), VGG를 이용해서 feature map을 추출한다.
- VGG 네트워크의 FC Layer (nn.Linear)를 Convolution으로 대체
- Transposed Convolution을 이용해서 Pixel Wise prediction을 수행
-
VGG
3x3 conv을 5가지의 block으로 적용함과 동시에 max_pooling을 이용해서 feature map의 크기를 줄여나가는 것을 볼 수 있습니다. 마지막 단에서는 FCN 3개를 적용
여기서 backbone으로 VGG를 썼다는 것의 의미는?
-
Pretrained 모델을 이용할 수 있다. (어느 정도 학습된 것을 이용 가능), 자원의 낭비 방지,
VGG16을 backbone으로 해서 FCN을 학습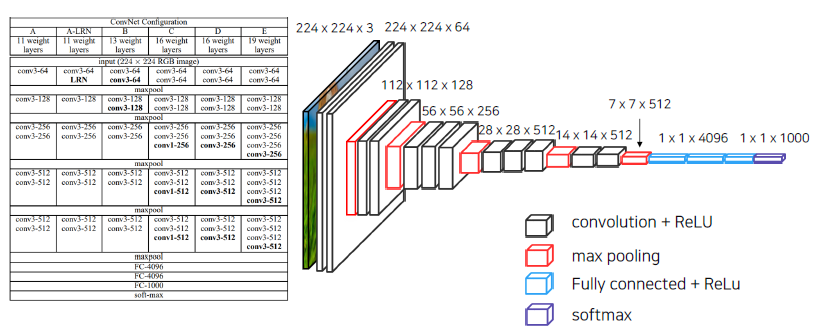
-
-
Fully Connected Layer vs Convolution Layer
-
특징?
첫번째 특징,
FC Layer (nn.Linear)를 Convolution layer 로 대체, 위치 정보를 유지할 수 있는 특징
Fully Connected Layer의 경우, flatten을 통해서 fc-layer를 만들어도 괜찮았다. 그 이유는 object가 ‘무엇인지’ 판단하는 classification에만 관심있기 때문입니다.
하지만, Sematic Segmentation이나, object detection의 경우, object가 ‘어느 위치’에 있는 지와 ‘무엇인지’ 판단해야하기 때문에 위치정보를 함께 갖고 있어야 합니다.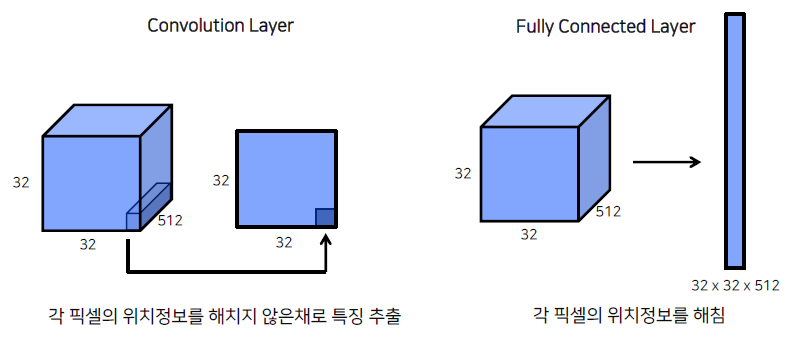

두번째 특징,
1x1 Convolution을 사용할 경우, 임의의 입력값에 대해서도 상관이 없습니다. Image size가 영향을 주지 않고, kernel의 파라미터와 입력 channel의 영향을 받습니다. (kernel_size의 영향을 받음)nn.Linear의 경우, flatten 과정이 필요하기 때문에, input_channelxheightxwidth의 연산이 필요하기 때문에, Image의 size에 영향을 받습니다.

-
-
Transposed Convolution
Image가 VGG Net을 통해서 convolution과 max pooling 과정을 거치게 되고, feature map의 size가 줄어들게 됩니다. (5개의 max pooling 이후, 224 -> 7)
우리는 여기서 픽셀 단위의 prediction을 수행해야 하기 때문에, 각 픽셀마다 어떤 클래스를 가지는 지 알아야 합니다. 따라서, output의 size를 늘리기 위해 upsampling 과정인 Transposed Convolution 과정을 진행합니다.-
Convolution remind
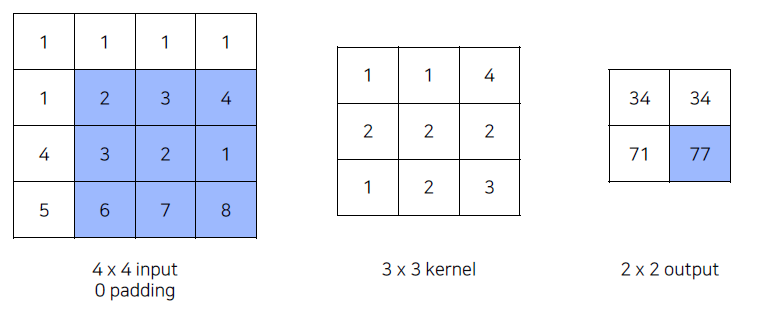
-
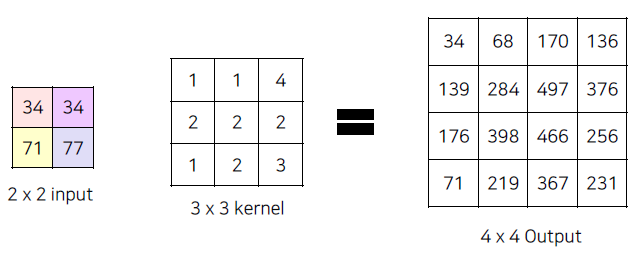
Transposed Convolution process
Transposed Convolution은 위에서 만들어진 작은 사이즈의 output을 3x3 kernel에 다시 convolution 연산을 수행하는 과정입니다. 아래에서 보면 위에서 했던 kernel 값과 동일한 값이 아니라, 학습이 가능한 Parameter 입니다. 그렇기에 Initialize된 weight가 BackProp을 통해 값이 Update되면서 더 좋은 Parameter를 만듭니다.

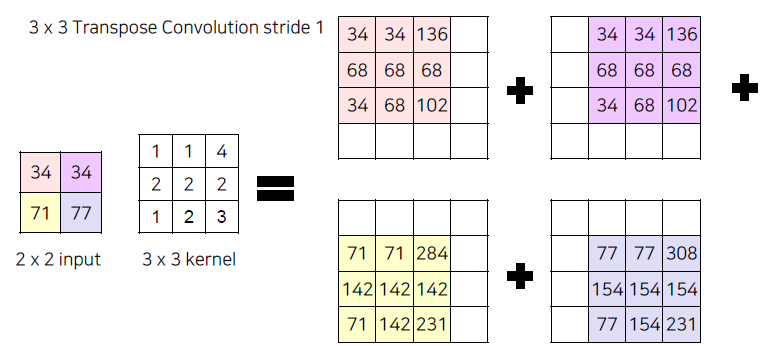
겹치는 영역은 서로 summation 해줍니다.
만일 사이즈가 더 큰 Output을 만들고 싶은 경우, stride = 2 로 늘려서 채워줄 수 있도록 합니다.
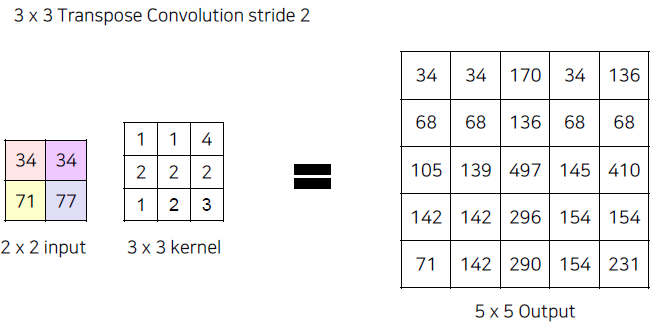
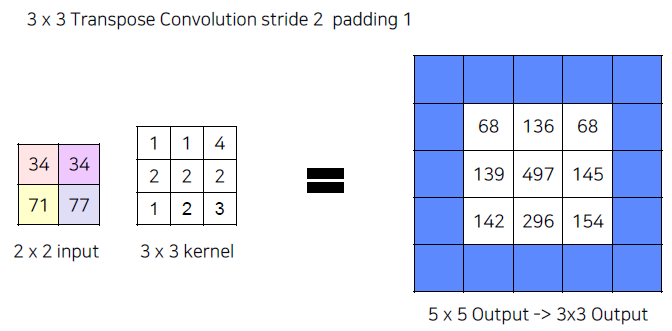
(질문) 더 큰 output일 경우,,,? -> Input에 Padding을 준다면 괜찮아지지 않을까?
(질문) 겹친 부분에 대해서 문제가 생기지 않을까?만약 Padding을 넣어줄 경우, 다음과 같이 바깥 라인은 지워져서 Output의 size가 달라질 수 있다.
-
Upsampling = Deconvolution = Transposed Convolution
엄밀한 명칭은 ‘Transposed Convolution’이다. 왜 그런 것일까?
위에서 했던 과정을 하나의 행렬로 나타내면 다음과 같이 나타낼 수 있습니다.Convolution by matrix
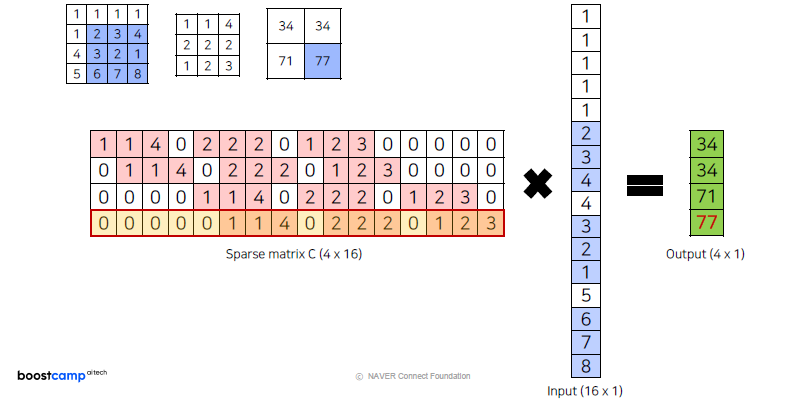
Transposed Convolution by matrix
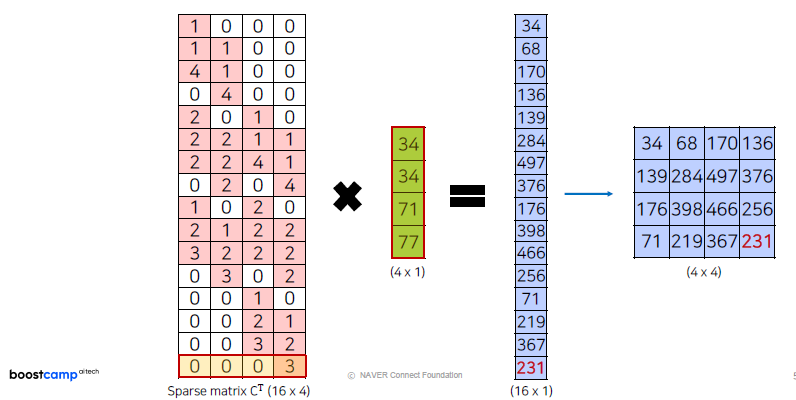
위에서 만들었던 Output과 같은 결과를 나타냅니다.
즉 이전에 했던 Upsampling 과정은 transposed된 kernel matrix를 다시 곱해주는 것과 같습니다.Deconvolution은 신호처리의 의미에서 원래 신호를 ‘복구’하다라는 개념으로 사용됩니다.
하지만 여기서 보면 Convolution을 통해 만들어진 Output이 다시, Input Image로 ‘복원’하는 개념이 아니기 때문에 Deconvolution이라는 용어는 잘못 되었다고 말할 수 있습니다. (by cs231)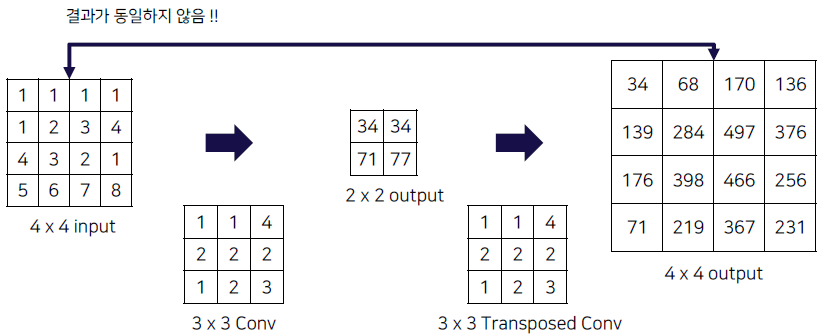
하지만 논문, 강의 자료들에서는 3가지 용어를 혼용해서 많이 쓴다고 합니다.
-
정리
- 중요한 점은 Convolution 과 마찬가지로 학습이 가능한 파라미터를 통해서 줄어든 이미지를 다시 키우는 Convolution 이라는 점
- 엄밀한 명칭은 Transposed Convolution 이라고 부르는게 정확 하지만 많이들 Deconvolution 이라는 용어와 같이 사용하니 참고
-
-
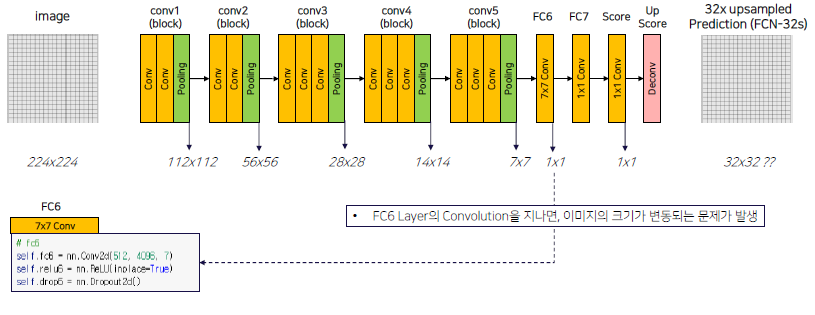
FCN에서 성능을 향상시키기 위한 방법
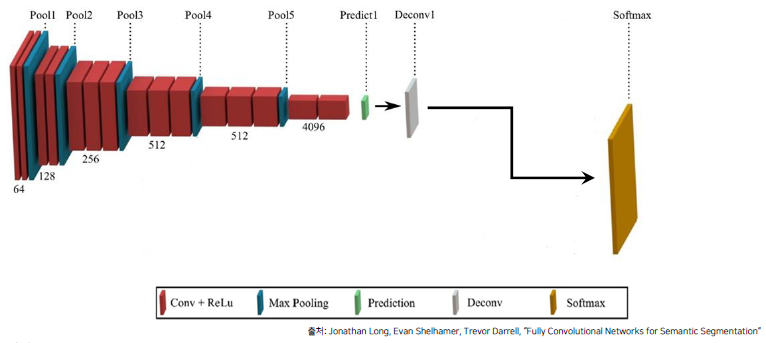
먼저, 전제는 다음과 같습니다. 실제 논문 상에서 FC6은 7x7 convolution을 보여주지만, 편의상 fc6은 1x1 convolution을 이용합니다. 이에 대해서는 후에 다뤄볼 예정입니다.
강의에서는 위의 과정을 다음과 같이 반복되는 Conv에 Convolution, ReLU 연산을 묶어서 코드를 작성했고 MaxPool을 놓았습니다. 이 반복하는 block들의 channel수만 맞도록 했습니다.

def CBR(in_channels, out_channels, kernel_size=3, strid=1, padding=1): return nn.Sequential(nn.Conv2d(in_channels = in_channels, out_channels = out_channels, kernel_size = kernel_size, stride = stride, padding = padding), nn.ReLU(inplace=True) )block 예시)


이렇게 conv를 진행하고, FC부터는 fully connected layer와 동일한 channel 연산을 하면서 위치 정보를 잃지 않게 1by1 convolution 적용합니다. 그 후, Dropout을 통해 robust하게 만들어줍니다.
(질문) 이 뜻이 구체적으로 뭘까? Dropout을 통해 파라미터의 수를 줄여 overfitting을 적게 해줌으로써 어떤 이상 값에도 크게 반응하지 않는 layer를 만든다는 뜻인가..?
마지막 Score는 동일한 연산 후 마지막 channel의 output을 num_classes만큼 반환합니다.
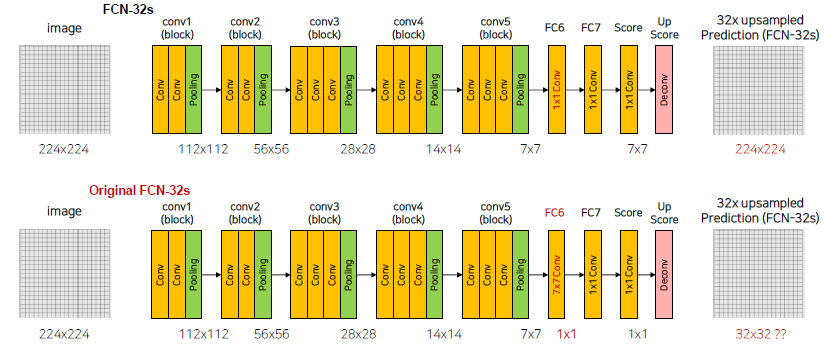
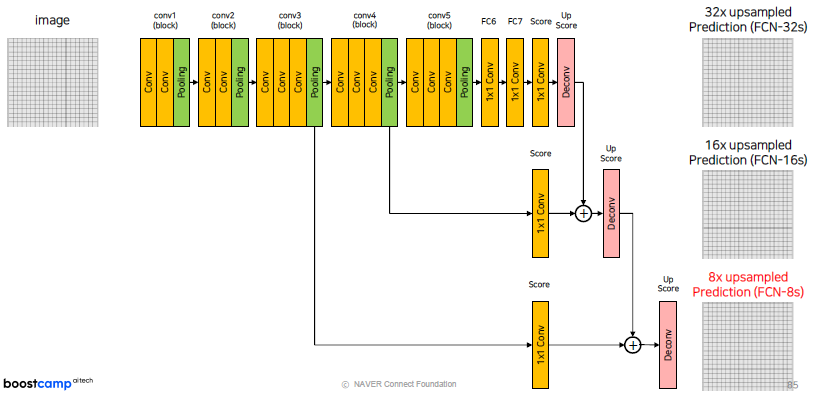
# Scores self.score_fr = nn.Conv2d(4096, num_classes, 1, 1, 0)위와 같은 긴 과정을 통해서, Image의 size는 Maxpooling을 통해 1/32 배만큼 줄어들게 되었습니다. 다시 Up sampling을 하기 위해서 마지막 과정은 32배만큼 다시 키워주게 됩니다.
(FCN-32s는 32-stride를 의미)# Scores self.upscore32 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=64, stride=32, padding=16)32배만큼 바로 키우는게 효과가 있을까??

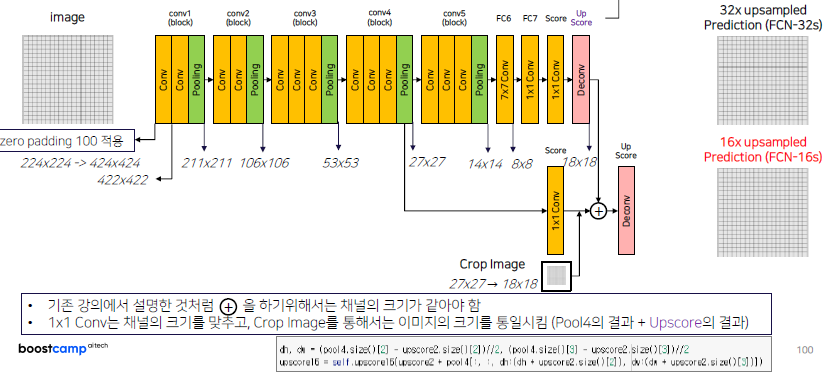
위 그림과 같이, 많은 Stride를 줄 수록 Detail한 정보들이 많이 사라지는 것을 볼 수 있습니다.
이러한 정보 손실을 막고자, Maxpooling을 통해 사라졌던 이미지 정보와 feature map의 Stride를 최대한 줄이고자 합니다.아래와 같이 Pooling 후 feature map을 뽑아내서 Upsampling한 output과 summation 과정을 통해 정보 손실을 줄였습니다.
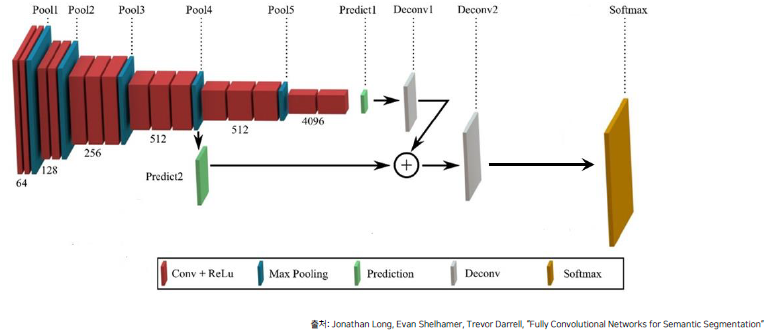
이로 인해 얻는 두가지 효과를 얻을 수 있습니다.
MaxPooling 에 의해서 잃어버린 정보를 복원해주는 작업을 진행
Upsampled Size 를 줄여주기에 좀 더 효율적인 이미지 복원이 가능위의 이미지를 더 정확히 살펴보면 다음과 같습니다.
pooling을 통해 1/16배 만큼 줄어든 score poolings 값(output은 num classes)과 Upscore를 통해 생성된 feature map의 합을 다시 upsampling하는 과정을 진행합니다.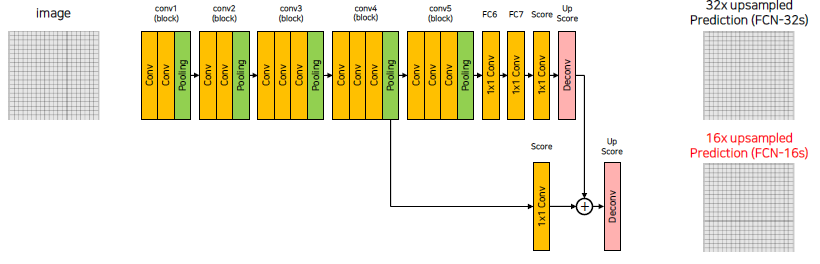
#score pool4 self.score_pool4_fr = nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0) #upscore2 self.upscore2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1) h = upscore2 + score_pool4_fr # 16x Upsample Prediction self.upscore16 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=16, padding=8)8x upsampled Prediction (FCN-8s) 또한 위와 같은 방식으로 진행하면 되겠습니다.
그 결과는 다음과 같이 성능 향상이 조금씩 있다는 것을 볼 수 있습니다.
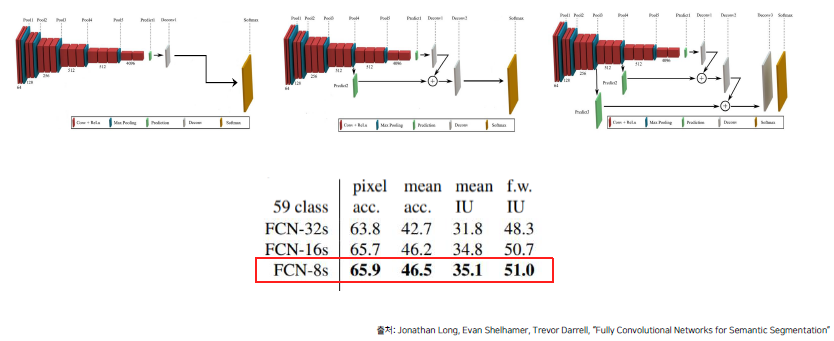
-
평가 지표
평가 지표는 Pixel Accuracy와 mIoU로 나눠서 볼 수 있습니다.
Pixel Accuracy 같은 경우, 전체 이미지에서 pixel이 얼마나 정확한 지 측정하는 것입니다.
mIoU 같은 경우, 각각의 클래스 내에서 Predict한 부분과 Ground Truth의 합집합에서 얼마나 일치하는 지 판단하는 IoU를 구합니다. 그리고 모든 클래스들의 IoU를 평균 값을 구합니다.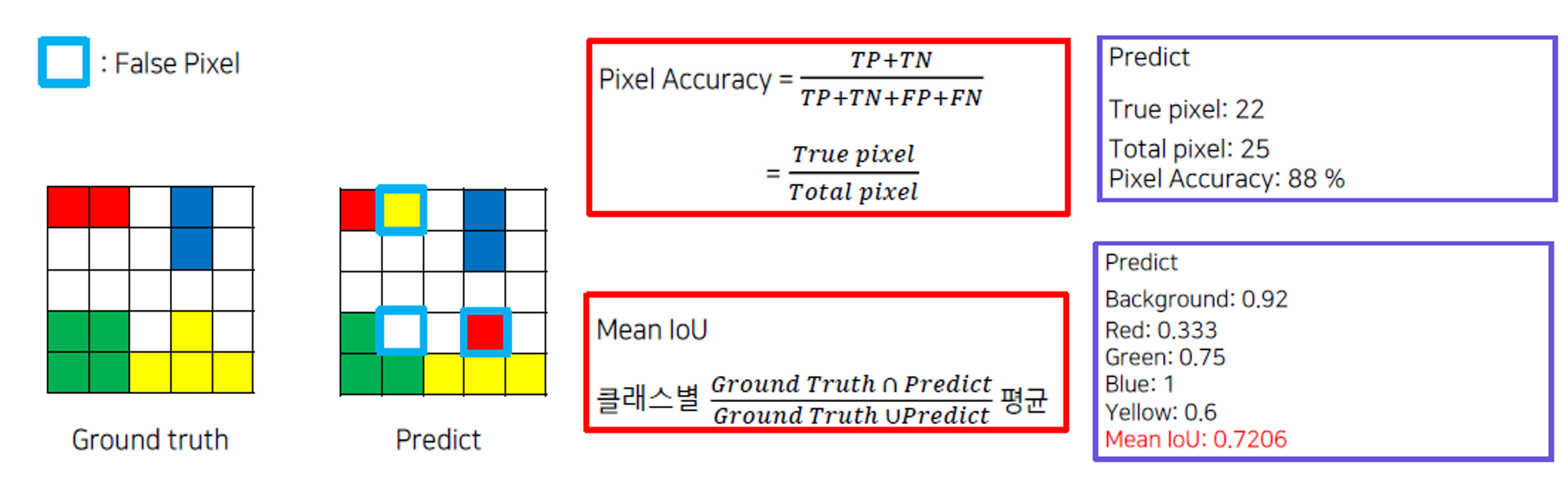
Further Reading
-
실제 논문에서는 FC6가 7x7 convolution을 수행하게 됩니다. 이 Convolution을 통하면 이미지의 크기가 줄어들게 되고 Deconv를 적용할 때, Input은 1by1이 되기 때문에 output은 32by32 feature가 됩니다.
저자의 코드에서는 위의 문제를 해결하기 위해서 conv1의 첫번째에 zero padding을 넣어줍니다.
하지만 그 결과 또한 256x256 map이 나왔습니다.
이 결과를 해결하고자 Output을 Crop 시킨 이미지를 이용했습니다.
같은 방식으로 FCN-16s에서도 이용했습니다. 다만, Crop Image 이전에 채널의 크기와 Image size를 맞춰서 합해줄 수 있어야 합니다.
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
프로젝트 수행
-
resnet50 baseline으로만 돌렸을 때, best_loss를 이용해서 model을 뽑음. LB : mIoU = 0.491
-
deeplabv3_resnet50로 돌렸을 때, best_loss 이용해서 model 뽑음. 관찰했을 때, Average Loss: 0.2839, Accuracy : 0.92, mIoU: 0.4901 이때 이후로 저장을 안하는 것을 볼 수 있었다. 여기서 알 수 있었던 특징점
1) mIoU는 loss가 증가하는 데도,, 증가하는 현상을 볼 수 있었다. (이후, loss가 0.3을 넘는데 mIoU가 0.5를 넘어감)
2) Battery를 아예 못잡는다. 데이터 양도 너무 적긴하다. → 15, 16 epoch 이상부터 잡기시작
3) Aux classifier를 건들면 모델이 np.bin? 거기서 오류가 생긴다.
4) Validation Epoch이 15 이후로 계속 떨어지는 것을 볼 수 있다.
5) mIoU가 거의 0.5398 까지 올라갔다..LB : mIoU = 0.529 (10/19 기록)
time : 약 3시간
오잉? 그래도 잘되넹..
3. 피어세션 정리
피어세션
- swin 논문 리뷰 ( 안소정, 황주영 )
- 2강 리뷰
- Q.왜 float을 사용하면 어떤 데이터 처리가 진행되는 걸까?
- baseline으로 돌렸을 때, mIOU : 0.491
새로운 강의, 프로젝트 시작
4. 학습 회고
- 어질어질하다.. 어렵지만 그래도 이번엔 재밌을 것 같은 기분이다.