
[네이버 부스트 캠프] AI-Tech - Lv2 week5(3)
학습기록 - 46
오늘 할 일
- Advanced Object Detection 2
1. 강의 복습 내용
M2Det
Multi-level / Multi-scale Object Detection
-
Feature Pyramid 한계점
- Backbone으로부터 feature pyramid 구성
- Classification task 를 위해 설계된 backbone 은 object detection task를 수행하기에 충분하지 않음
- Backbone network는 single level layer 로 , single level 정보만 나타냄
-
일반적으로, low level feature는 간단한 외형을, high level feature 는 복잡한 외형을 나타내는데 적합
- 정리하자면, 기존의 FPN은 객체의 크기를 대응하기 위해서 Multi-scale feature pyramid를 이용했지만, 이 경우엔, 객체 외형(shape)의 복잡도에 대해서 충분히 대응할 수 없다는 단점을 갖고 있다.
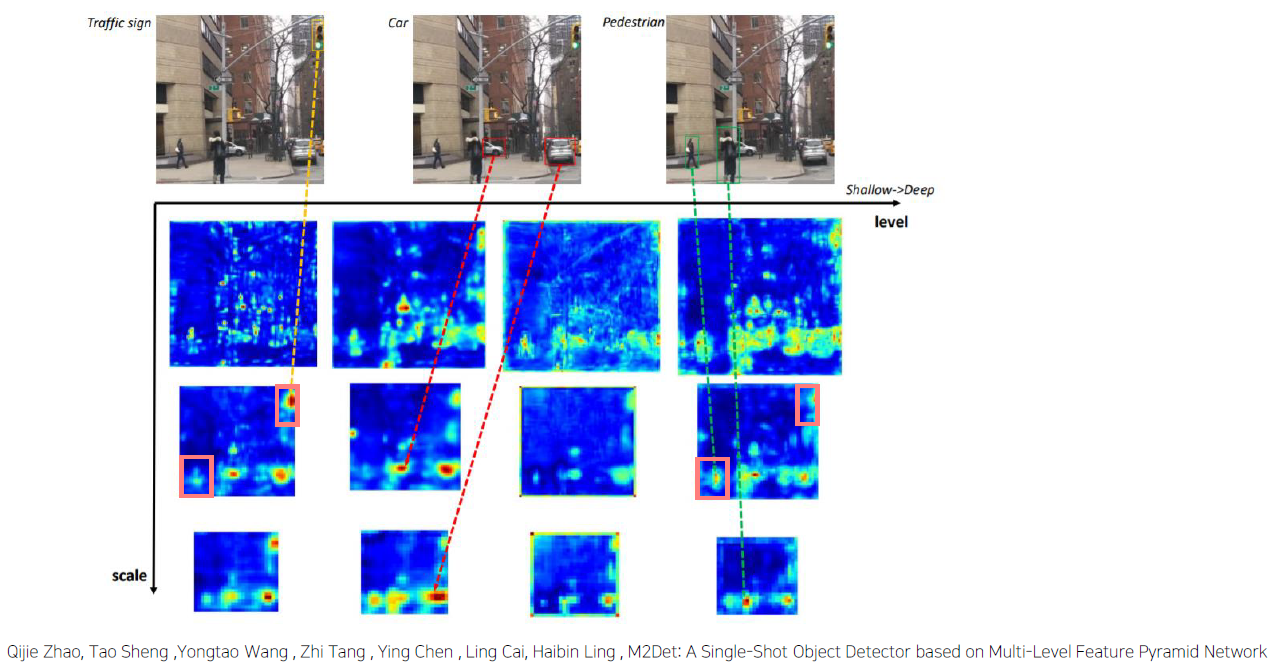
- Backbone으로부터 feature pyramid 구성
-
M2Det
- Multi-level, multi-scale feature pyramid 제안
-
SSD 에 합쳐서 M2Det 라는 one stage detector 제안
-
Overall Architecture
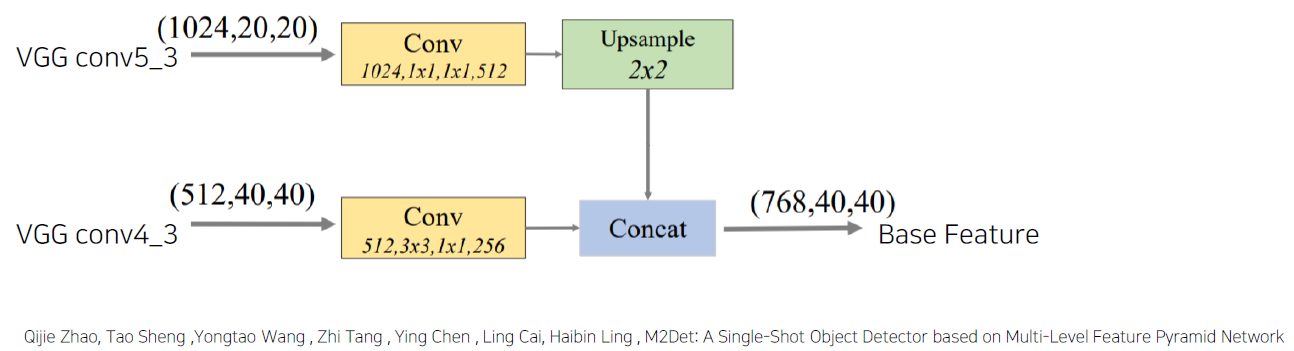
Backbone에서 서로 다른 두 개의 faeture map을 통합해서 base feature를 만든다.
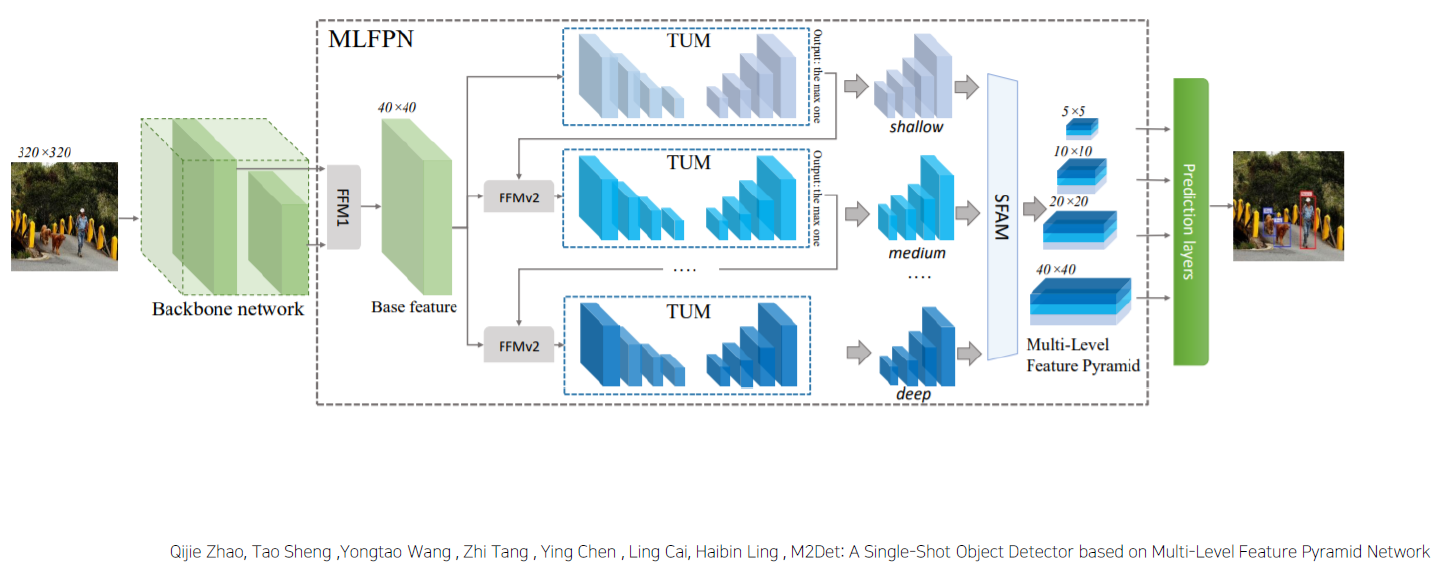
FFM : Feature Fusion Module
- FFMv1 : base feature 생성
-
Base feature : 서로 다른 scale의 2 feature map을 합쳐 semantic 정보가 풍부함.
Stage5 와 stage4를 적절하게 concat할 수 있도록 한다. 그러기 위해선 resolution을 맞춰야 한다. (512, 40, 40) 으로 concat
TUM : Thinned U-shape Module
- Encode-decoder 구조 (U-Net, Encoder & Decoder의 구조)
-
TUM을 통해서 나온 decoder를 feature map을 이용하는 데, 이 경우를 Multi-scaled feature map이라 한다.
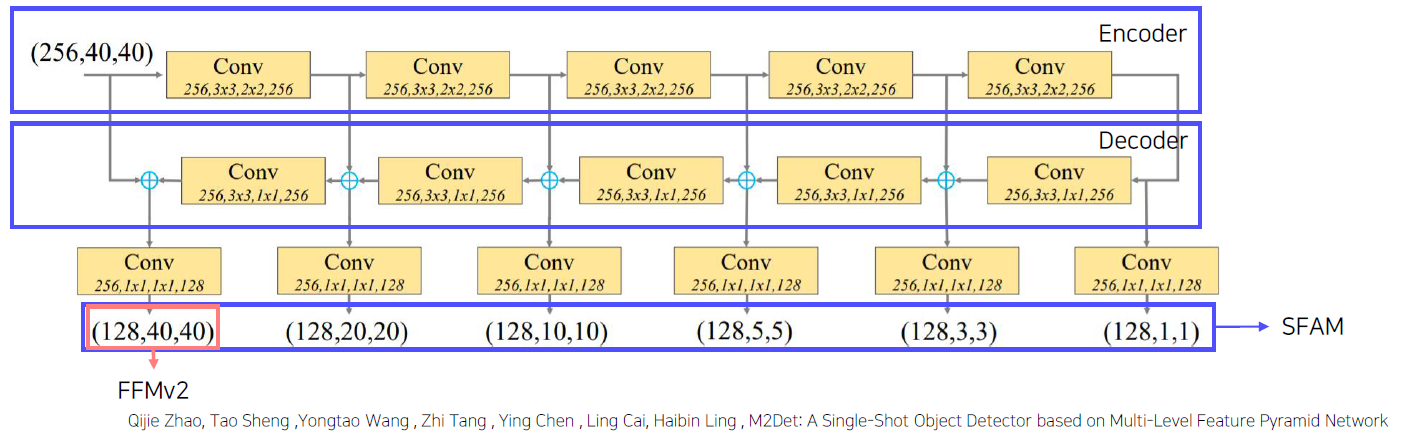
이 중 가장 큰 Scale을 갖는 feature map을 가져와서 base feature와 concat해주게 되는데, 이 때, FFMv2를 이용해서 다른 TUM을 통과한다.
이렇게 각 레벨 별로 Multi-scaled feature map들을 SFAM을 통해서 적절하게 concat 후, attention을 가해준 뒤, feature map을 만들어 ssd head를 통과해서 만들어 준다.
여기서 의문이 드는 점이 생길 수 있는 데, base feature을 통해서 나온 channel shape은 (768, 40, 40)으로 Input을 feature로 하는데 위의 TUM은 (256, 40, 40)으로 Input을 feature로 한다. 그 이유는 논문을 보면, 다음과 같이 맨 처음 TUM의 경우, 예외로 Input size를 설정해주는 듯 하다.

결론으로, 위와 같이 backbone에서 가져온 feature map을 multi-level로 뽑아내고 뽑아낸 feature map을 TUM을 통해서 다시 Multi scale feature map을 뽑아내서 SFAM을 통해 SSD Head로 가져가게 된다.
이를 통해, 복잡한, 단순한 외형의 물체를 다 식별할 수 있도록 만든다.SFAM : Scale-wise Feature Aggregation Module
- 동일한 scale을 가진 feature들끼리 연결 (scale-wise cocatenation)
-
각각 scale의 feature들은 multi-level 정보를 포함
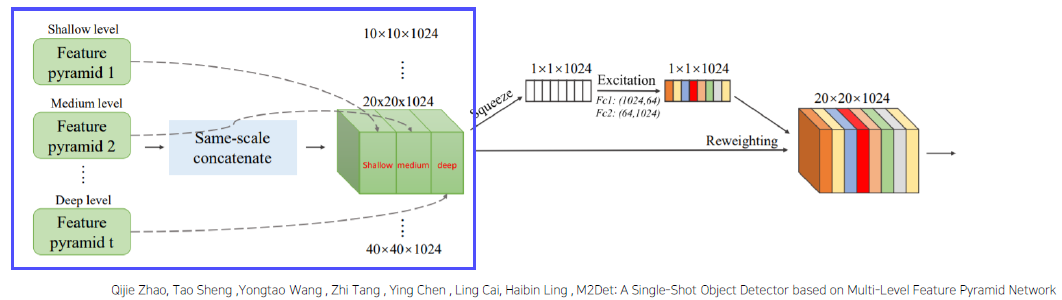
- Channel-wise attention 도입 (SE block) -> SSD를 넣어주기 전에 수행하는 과정
- 채널별 가중치를 계산하여 각각의 feature 를 강화시키거나 약화시킴
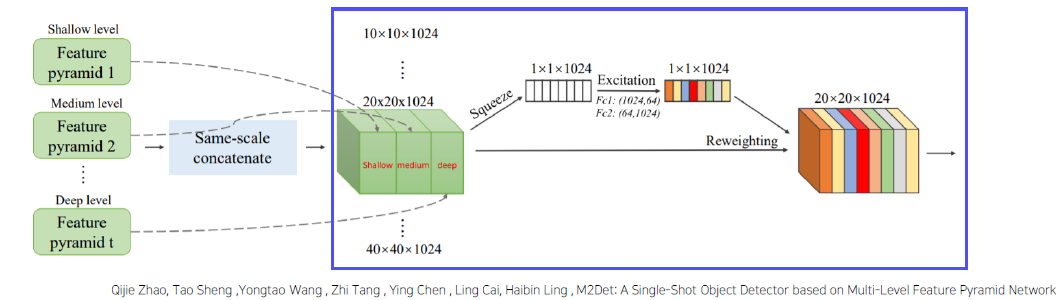
-
SSD head로 넣어서 통과

- 8개의 TUM 사용
- 출력 : 6개의 scale features
- Detection Stage
- 6개의 feature마다 2개의 convolution layer를 추가해서 regression, classification 수행
- 6개의 anchor box 사용
- Soft-NMS 사용
-
ConerNet
- Anchor Box의 단점
- Anchor Box의 수가 엄청나게 많음
- 하이퍼 파라미터를 고려해서 box 개수, 사이즈, 비율 설정
- Anchor Box가 없는 1 stage detector
- 좌측 상단, 우측 하단점을 이용하여 객체 검출
- 중심점을 잡게 되면 4 개의 면을 모두 고려해야하는 반면 corner 을 사용하면 2 개만 고려
-
Overall Architecture
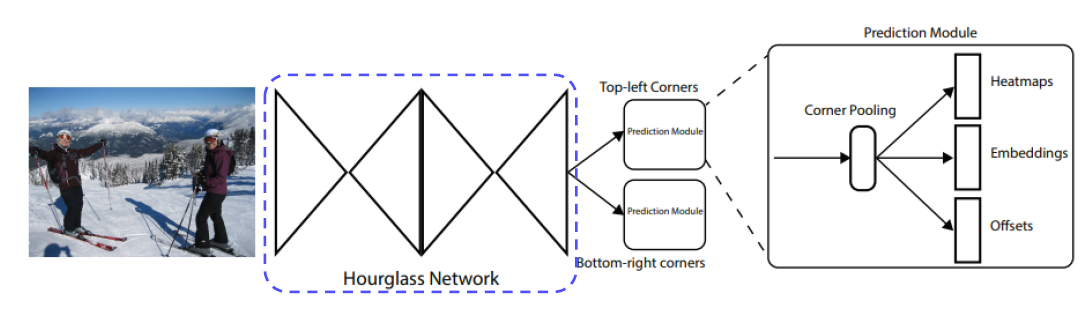
- Anchor Box의 단점
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
Sum of Loss in Model Training
여러 모델들의 loss를 모두 더해줘서 backward()를 하는 이유는? 해도 괜찮은건가? 각각의 loss를 구해서 backward()를 해줘야 하지 않는건가?
Sol
Document에서 보면, “ Autograd를 하면서 gradients를 계산하고 각 모델 Parameter들의 .grad attribute 안에 저장한다. “

“tensor a와 tensor b에 대해서 Q를 다음과 같이 가정했을 때, backward()를 수행한다면, 다음과 같이 편미분이 일어나고 autograd는 .grad attribute를 가지고 있는 각각의 tensor에 대해 따로 수행되고 저장된다.”

A Gentle Introduction to torch.autograd - PyTorch Tutorials 1.9.1+cu102 documentation
+++ 추가 설명,
위의 내용을 코드로 구현하면,
1) loss_1, loss_2에 대해서 backward를 진행했을 때,
```python
import torch
import torch.nn as nn
pred_y1 = torch.tensor([1.], requires_grad=True)
y1 = torch.tensor([5.], requires_grad=True)
pred_y2 = torch.tensor([2.], requires_grad=True)
y2 = torch.tensor([4.], requires_grad=True)
loss_1 = y1**2 - pred_y1**2
loss_2 = y2**3 - pred_y2**3
print(loss_1)
#tensor([24.], grad_fn=<SubBackward0>)
print(loss_2)
#tensor([56.], grad_fn=<SubBackward0>)
# loss_1에 대해서 backward을 했을 때,
loss_1.backward()
# 다음과 같이, backward를 실시한다면, 각 tensor안에 grad attribute안에
# loss_1에서 y1, pred_y1에 대한 편미분 값을 저장하게 된다.
print(pred_y1.grad)
#tensor([-2.])
print(y1.grad)
#tensor([10.])
loss_2.backward()
# loss_2에 대해 backward
print(pred_y2.grad)
#tensor([-12.])
print(y2.grad)
#tensor([48.])
# 각각 backward를 진행했을 때, 각 텐서의 grad 안에 미분 값을 저장하게 됩니다.
```
2) loss_1, loss_2에 대해서 backward를 진행했을 때,
```python
import torch
import torch.nn as nn
pred_y1 = torch.tensor([1.], requires_grad=True)
y1 = torch.tensor([5.], requires_grad=True)
pred_y2 = torch.tensor([2.], requires_grad=True)
y2 = torch.tensor([4.], requires_grad=True)
loss_1 = y1**2 - pred_y1**2
loss_2 = y2**3 - pred_y2**3
print(loss_1)
#tensor([24.], grad_fn=<SubBackward0>)
print(loss_2)
#tensor([56.], grad_fn=<SubBackward0>)
loss = loss_1 + loss_2
print(loss)
# tensor([80.], grad_fn=<AddBackward0>)
# loss = loss_1 + loss_2에 대해서 backward()를 했을 때,
loss.backward()
# 각 loss에서 진행했던 backward() 값과 동일하게 나옵니다.
print(pred_y1.grad)
#tensor([-2.])
print(y1.grad)
#tensor([10.])
print(pred_y2.grad)
#tensor([-12.])
print(y2.grad)
#tensor([48.])
# 즉, loss를 합해도 동일한 gradient를 가지게 됩니다.
```
여기까지 정리하면,
각 텐서를 가진 채로 연산을 수행할 때, requires_grad 에 따라서 grad attribute가 생성됩니다.
loss에 대해서 backward를 진행할 때, 각 텐서에 존재하는 grad라는 attribute안에 미분 값(변화도)이 저장됩니다.
그런데 loss는 tensor가 갖고 있는 모든 값을 더한 값인 scalar 형태로 output이 있어야 한다고 합니다.
왜 그런 것일까요?
위의 예시에서 tensor값을 vector로 늘렸을 때,
import torch
import torch.nn as nn
pred_y1 = torch.tensor([1., 2., 3.], requires_grad=True)
y1 = torch.tensor([5., 6., 7.], requires_grad=True)
loss_1 = y1**2 - pred_y1**2
print(loss_1)
#tensor([24., 32., 40.], grad_fn=<SubBackward0>)
loss_1.backward()
# RuntimeError: grad can be implicitly created only for scalar outputs
다음과 같이 loss_1은 Runtime Error가 나게 됩니다.
하지만, 아래와 같이 모든 값을 더해주고 backward()를 하게 된다면 각 vector에 gradient 값이 전달됩니다.
loss_1 = (y1**2 - pred_y1**2).sum()
loss_1.backward()
print(pred_y1.grad)
#tensor([-2., -4., -6.])
print(y1.grad)
#tensor([10., 12., 14.])
왜 그런 것일까요?
처음엔, loss_1을 sum하지 않아도 loss_1 = [ 24., 32., 40.] 에 대해 각각 미분이 적용되지 않을까? 라는 생각을 했습니다.
해답은 torch.autograd 는 Jacobian 연산을 위한 엔진이기 때문이었습니다. Jacobian product를 이용해서 각 해당 tensor 안에 값들에 대한 추적이 가능합니다. → 조금 더 자세하게 설명하고 싶은데.. Jacobian에 대한 이해가 머릿속으로 잘 그려지지 않네요..
Jacobian 관련 참고자료
How Pytorch Backward() function works - 링크