
[네이버 부스트 캠프] AI-Tech - Lv2 week5(1)
학습기록 - 44
오늘 할 일
- Advanced Object Detection 1
1. 강의 복습 내용
Cascade RCNN
-
Motivation
-
다음 표처럼 1) IoU threshold에 따라 다르게 학습되었을 때 결과가 다름, 2) Input IoU가 높을수록 높은 IoU threshold에서 학습된 model이 더 좋은 결과를 냄.
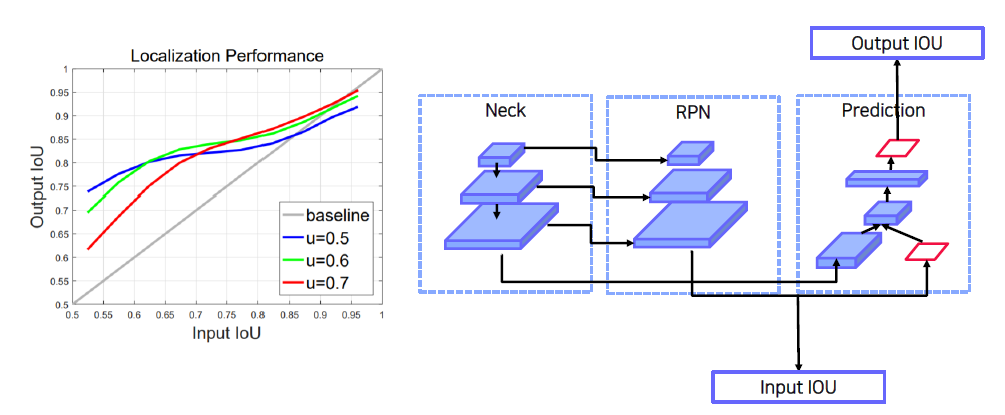
- IoU threshold에 따라 다르게 학습되었을 때 결과가 다름
- 아래 표는 “예측된 박스”에 Ground Truth와 비교를 했을 때, 그 기준을 IoU threshold라고 놓는다. Threshold를 넘어가면 True, 넘어가지 않는다면 False로 한다. (그렇다면, 0.5는 AP50으로 될 수 있다.) -> 여기서 IoU Threshold는 AP의 IoU를 뜻한다.
- 전반적인 AP의 경우, IoU threshold 0.5로 학습된 model이 성능이 가장 좋다.
-
그러나 AP의 IoU threshold가 높아질수록 IoU threshold가 0.6, 0.7로 학습된 model의 성능이 좋다.
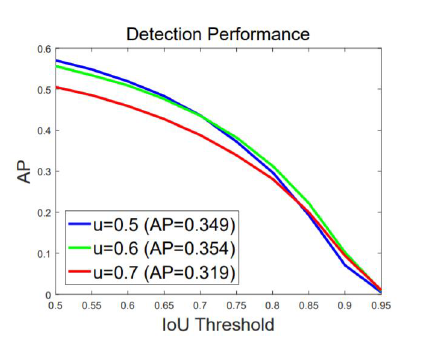
정리하자면,
- 학습되는 IoU에 따라 대응 가능한 IoU 박스가 다름
- High Quality detection을 수행하기 위해서는 IoU threshold를 높여 학습할
- 학습되는 IoU 에 따라 대응 가능한 IoU 박스가 다름
- 그래프와 같이 high quality detection 을 수행하기 위해선 IoU threshold 를 높여 학습할 필요가 있음. 단, 성능 하락 문제 존재
- 이를 해결하기 위해 Cascade RCNN을 제안 (순서를 가지고 학습하는 방법론)
-
-
Faster R-CNN
RPN, Head Network를 학습시키기 위한 데이터셋 구성 필요
Cascade RCNN은 IoU를 0.5, 0.6, 0.7 등을 기준으로 Head를 만들어 Detection 했을 때 어떻게 달라질까?에 기준을 둔다.
-
Method
Deformable Convolution Network (DCN)
-
Problems
Geometric Augmentation, Geometric invariant feature selection -
Methods
일반 convolution에서 offset을 더 추가하여 학습시키면서 위치를 유동적으로 변화할 수 있게 한다. 이를 이용해 모양이 다른 객체를 볼 수 있게 만들어주는 것.
Transformer
이전 포스팅 링크
AI-Tech-re - week2(4) - Transformer
- Overview
- NLP 에서 long range dependency 를 해결 이를 vision 에도 적용
- Vision Transformer (ViT)
- End to End Object Detection with Transformers (DETR)
- Swin Transformer
-
Transformer
Self Attention
Input에는 Deep learning이 이해할 수 있도록 vector로 embedding을 해야한다. (여러 다양한 방법들이 있다.)
Positional Encoding : Input의 순서를 담당하는 것이다.
Embedding한 Input과 Positional Encoding을 더해서 Attention Network를 수행한다.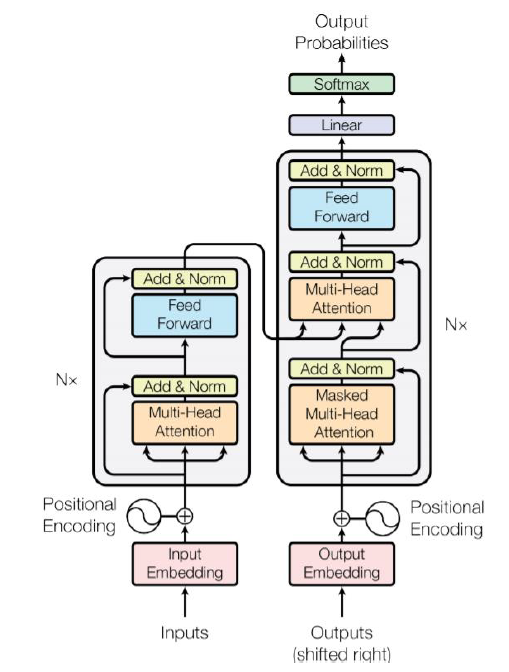
Attention Network 확대
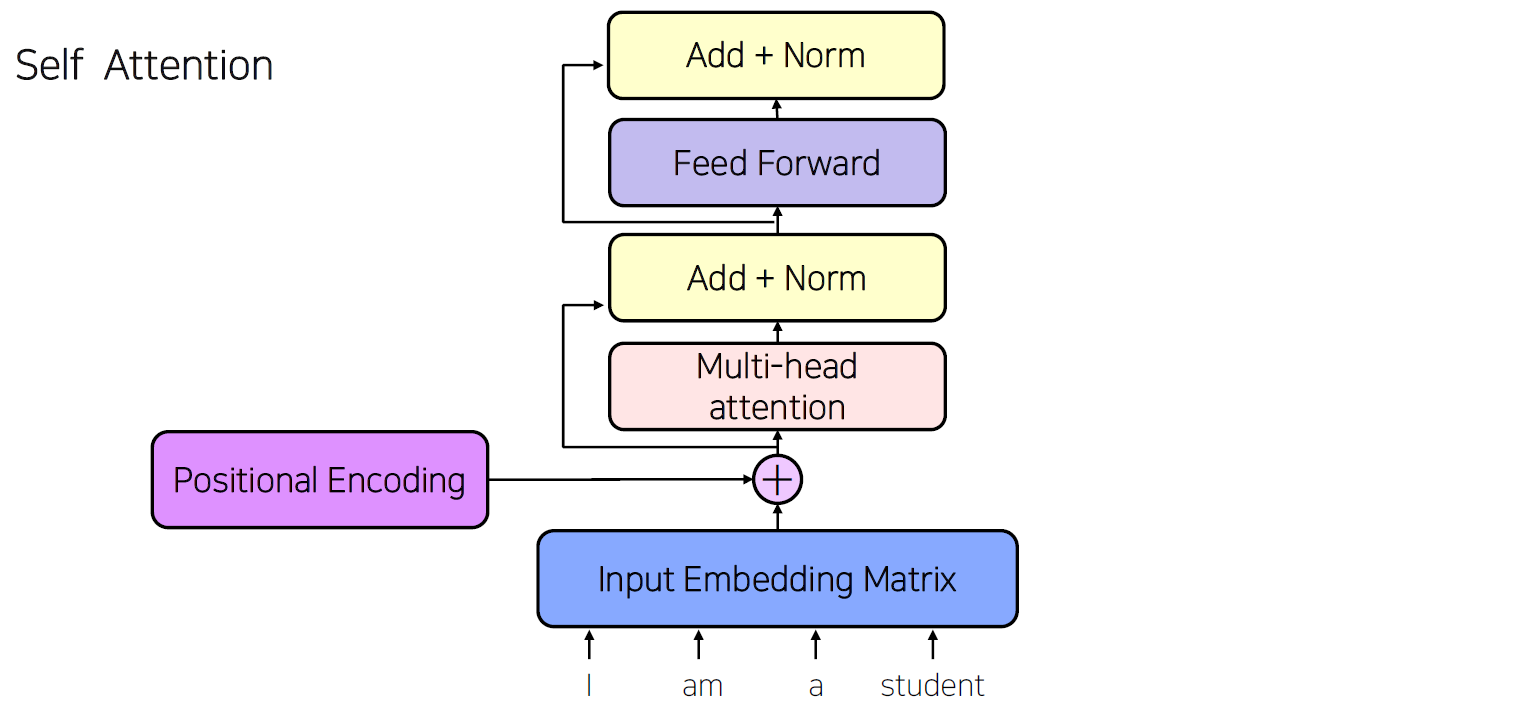

Multi head-Attention
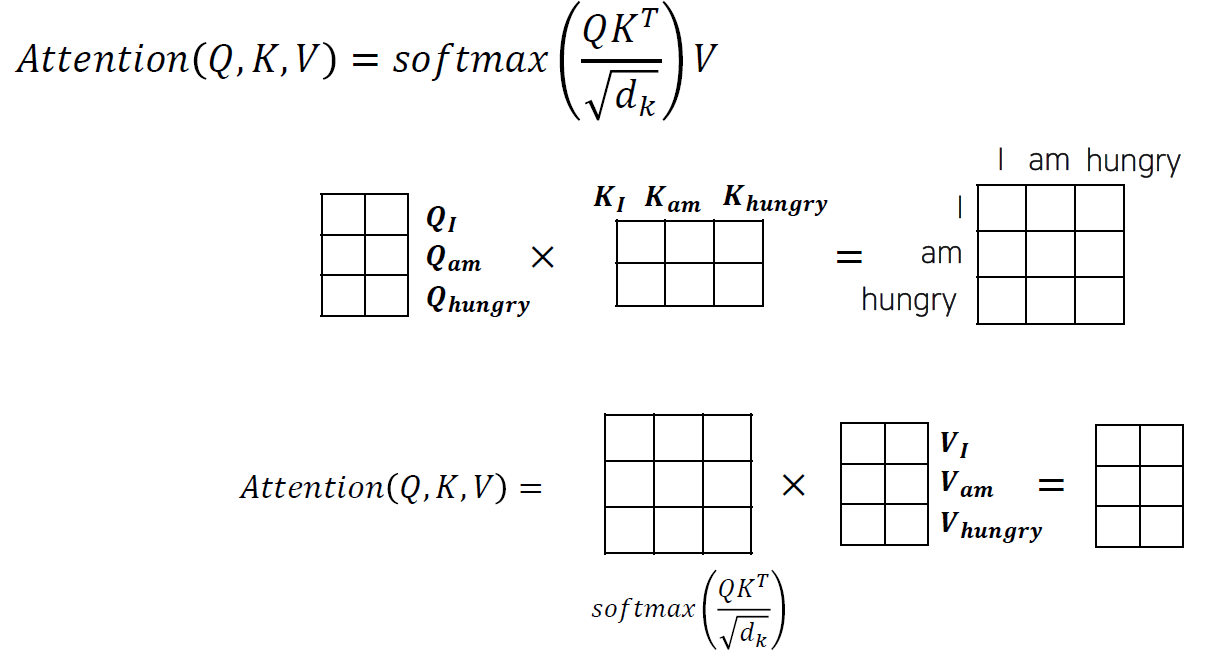
Sentence의 각 단어들은 Embedding 과정을 통해 Input은 다음과 같이 총 d개의 차원을 갖는 Input으로 바뀝니다.
이 Input은 각 3개의 연산을 통해서 3가지 vector로 만들 수 있습니다. (Query, key, Value)
각 vector는 Single-head이기 때문에 (h=1), convolution(d by d)연산 후 3byd 행렬로 나타낼 수 있습니다.
이 후, 우리는 각 단어들의 중요도를 계산하기 위해서 (Attention을 계산) Query와 Key를 Convolution 해서 새로운 Attention Map(3 by 3) 을 만듭니다.
그 이후, dimension 크기로 Normalization을 진행합니다. 이를 하는 이유는 dimension이 커지면 커질 수록 map의 요소 크기가 증가하기 때문입니다. (convolution 특징)Attetion map은 Key값과의 연산을 통해 각 단어마다 중요도를 가지고 있는 vector map을 생성하게 됩니다.
우리는 앞서서 dimension을 head로 나눠서 3가지 vector (W,Q,K)를 만들었습니다. 이 때, dimension을 head의 길이만큼으로 나눈 값을 conv 연산을 했었는 데 이 말은 즉, 지금까지 계산 과정이 h번 진행했다고 생각하면 됩니다.
진행된 head(단어 개수) vector들을 concat하고 d by d matrix를 수행하게 됩니다. (Multi-head Attention)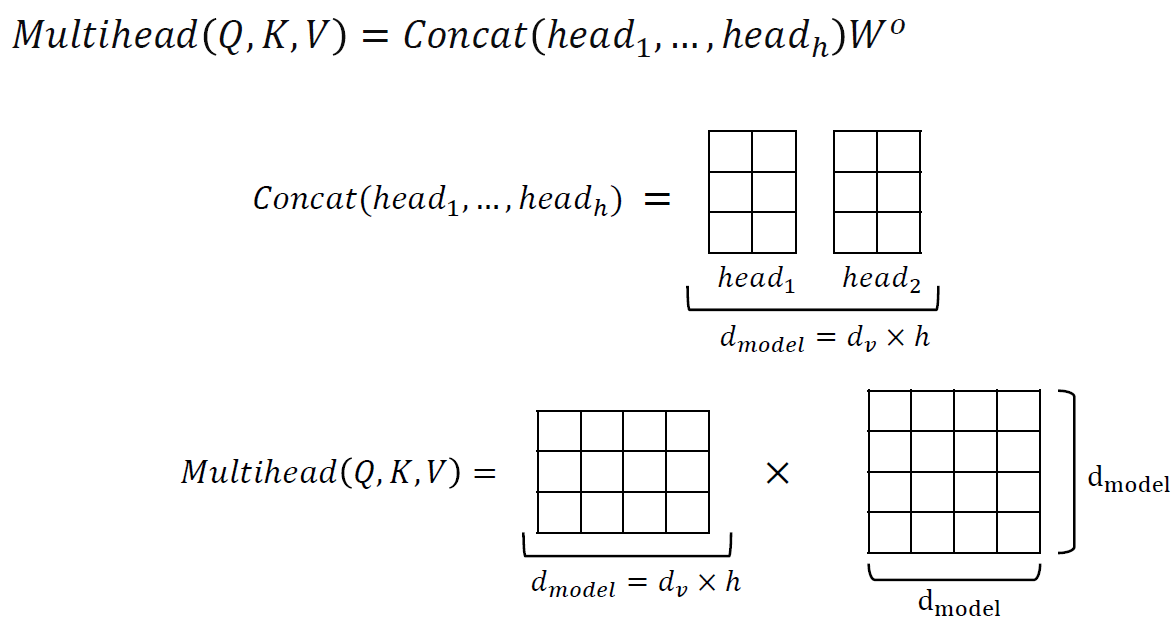
-
ViT (Vision Transformer)
앞서 말한, Transformer를 Image 데이터에 적용하는 방법이 “Vision Transformer (ViT)” 입니다.
ViT는 해당 논문에서 나온 내용입니다. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale논문에서는 transformer를 image patch의 sequence에 적용하여 classification을 수행합니다. Transformer는 Sequence를 이용해서 Input이 병렬 처리로 한번에 학습이 가능하고, 계산 효율(computational Efficiency), 확장성(scalability)에 이라는 특징이 있어서, model의 파라미터 크기 증가시킬 수 있습니다.
transforemr는 Computer Vision에서 적용하기에 Inductive Bias를 갖고 있습니다. Inductive bias는, 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용하는 추가적인 가정을 의미합니다.
이게 무슨 뜻이냐면,
CNN 같은 경우, Locality에 대한 가정을 가지고 있습니다. 따라서 Global한 영역에서 Locality에 대한 처리가 어렵기 때문에, Receptive Field를 늘리기 위한 연구 등을 진행합니다.
RNN 같은 경우, 시계열 데이터에서 가장 가까운 단어에 대한 영향을 통해 학습이 잘될 수 있다는 가정을 갖고 있습니다. 따라서, 긴 sequence 데이터에선 먼 단어에 대한 연관성을 더 가져오기 위한 연구를 하고 있습니다.
Transformer 같은 경우, Positional Embedding이나 Self-Attention 메커니즘을 통해 모든 정보는 활용하지만 추가적인 가정(Inductive Bias)가 부족하다는 점이 있습니다. 따라서 어떤 목적으로 개선하기 보다는 많은 양의 데이터를 요구한다는 것입니다.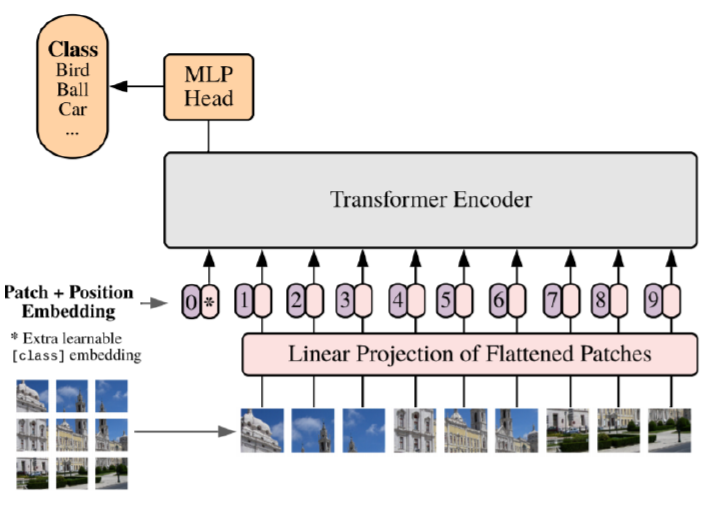
1) Flatten 3D to 2D (Patch 단위로 나누기)
-> Image를 word형태로 바꾸는 과정 2) Learnable 한 embedding 처리
3) Add class embedding, position embedding
4) Transformer
5) Predict먼저, 3D Image를 2D 형태로 바꿔줘야 합니다. 여기서 Image를 픽셀별로 word로 본다면, sentence의 길이가 많이 길어질 수 있습니다. 따라서, 아래의 그림과 같이 “Patch”를 이용합니다.
여기서 Image의 channel은 3이므로, patch로 쪼갠 후 flatten을 시켜준다면 다음과 같이
4의 word를 가지고, 8x8x3의 dimension을 가지는 vector map을 만들 수 있습니다.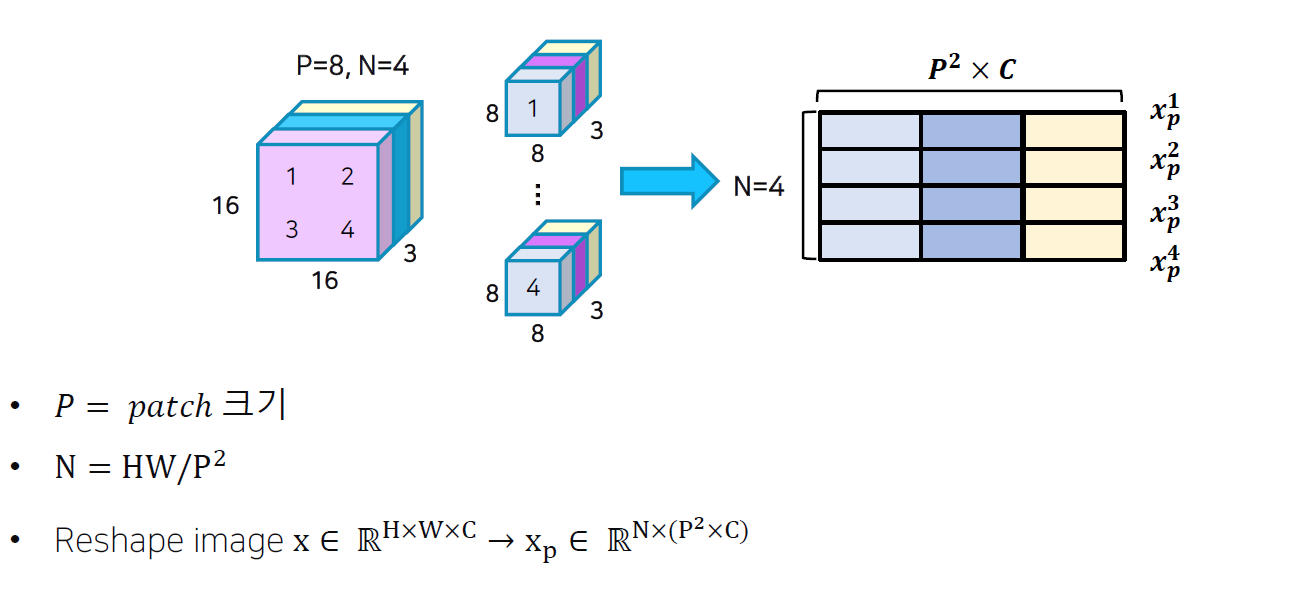
위의 연산을 통해 나온 Image 조각의 vector map을 embedding vector에 통과 시켜서 학습 가능한 만들어 줍니다.
Embedding 과정은 NLP의 transformer와 동일하게 이용됩니다.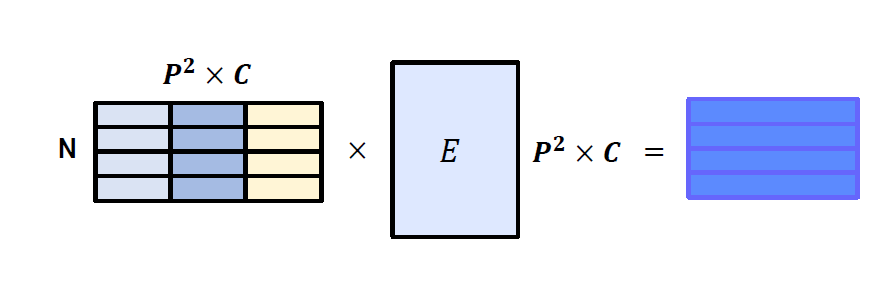
Class embedding (CLS 토큰 값)을 추가해서, 총 Input의 길이를 늘려줍니다.
추가하는 이유는 하나의 이미지에 대해서 classification을 수행할 수 있게끔 처리해주기 위함입니다.
이후 Position Embedding을 추가해서, 이미지의 위치에 따라 학습할 수 있게 합니다.
전체적인 Architecture를 살펴보면, 거의 기존 Transformer와 거의 유사하다는 것을 볼 수 있습니다.
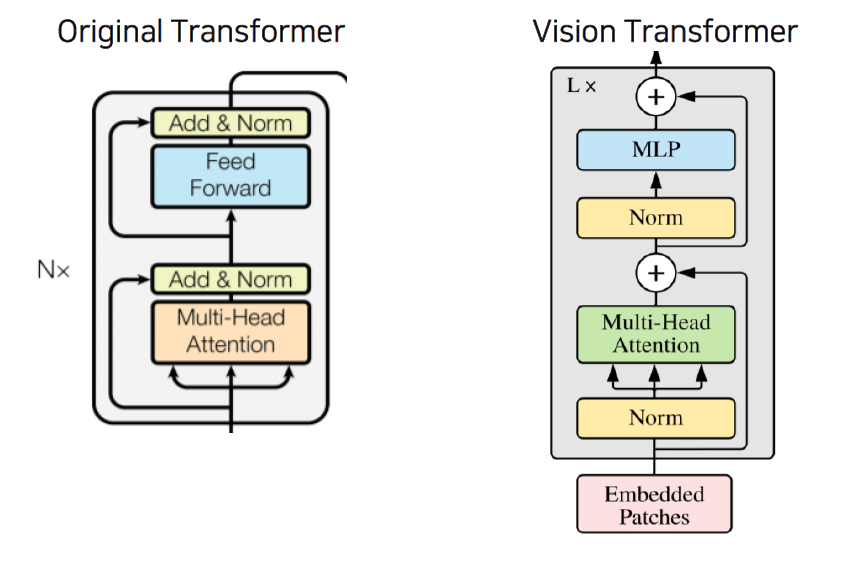
다시 위의 이미지로 돌아가서 보면, 가장 왼쪽에 CLS토큰에서 Transformer Encoder를 통해 나온 Output 값 (첫번째 output) 을 MLP head를 통해 Classification을 수행합니다.
-
Hybrid Achitecture
이미지를 CNN으로 feature map 생성해서 1dim으로 flatten 시키고 Patch별로 position embedding을 붙여서 transformer에 넣는다. -
ViT의 문제점
- ViT 의 실험부분을 보면 굉장히 많은 양의 Data 를 학습하여야 성능이 나옴, Convolution을 완전히 벗어났습니다.
- Transformer 특성상 computational cost 큼 (Detection 같은 경우, Resolution 존재)
- 일반적인 backbone으로 사용하기 어려움 (CNN과 같이 중간 단계의 layer를 이용해서 FPN 생성 불가)
-
-
End-to-End Object Detection with Transformer
-
Swin Transformer
- ViT의 문제점
- 굉장히 많은량의 Data 를 학습하여야 성능이 나옴
- Transformer 특성상 computational cost 큼
- 일반적인 backbone 으로 사용하기 어려움
- 해결법
- CNN 과 유사한 구조로 설계
- Window라는 개념을 이용해서 Cost를 줄임
- ViT의 문제점
EfficientDet
-
Model scaling 모델의 크기가 클수록 성능이 더 좋아진다. 모델을 쌓을 때, 잘 쌓을 수 있는 부분이 존재할 것이다.
Model scaling에는 다음과 같은 방법들이 존재한다.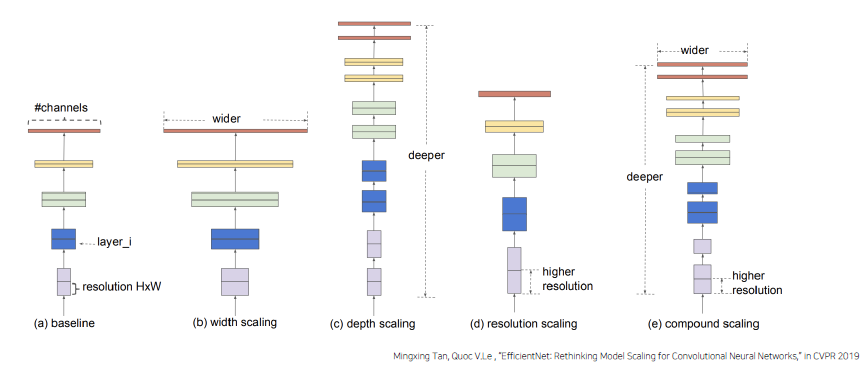
더 높은 정확도와 효율성을 가지면서 ConvNet의 크기를 키우는 방법 (scale up) 은 없을까?
EfficientNet
- Background
- 파라미터 수가 점점 많아지는 모델
- ConvNet은 점점 더 커짐에 따라 더 정확해지고 있다.
- 점점 빠르고 작은 모델에 대한 요구 증가
- 효율성과 정확도의 trade-off를 통해 모델 사이즈를 줄이는 것이 일반적(MobileNets, SqueezeNets)
- 하지만 , 큰 모델에 대해서는 어떻게 모델을 압축시킬지가 불분명함
- 따라서 이 논문은 아주 큰 SOTA ConvNet 의 efficiency 를 확보하는 것을 목표로 함 -> 모델 스케일링을 통해 이 목표를 달성
- Scale up
-
Width Scaling
-
Depth Scaling
-
Resolution Scaling
-
Compound Scaling (위 세가지 특징을 모두 통합)
-
-
Better Accuracy & Efficiency
d, w, r : Scale Factor
Better Accuracy, Better Efficiency를 보장하려면?

- Obsevation
-
네트워크의 폭, 깊이, 혹은 해상도를 키우면 정확도가 향상된다. 하지만 더 큰 모델에 대해서는 정확도 향상 정도가 감소한다.
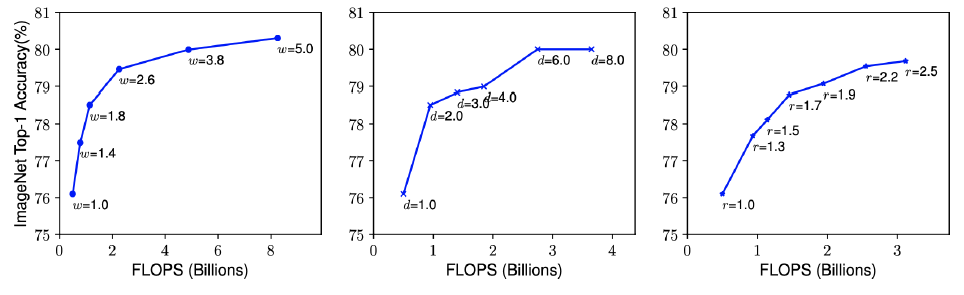
-
더 나은 정확도와 효율성을 위해서는, ConvNet 스케일링 과정에서 네트워크의 폭 , 깊이 , 해상도의 균형을 잘 맞춰주는 것이 중요하다.
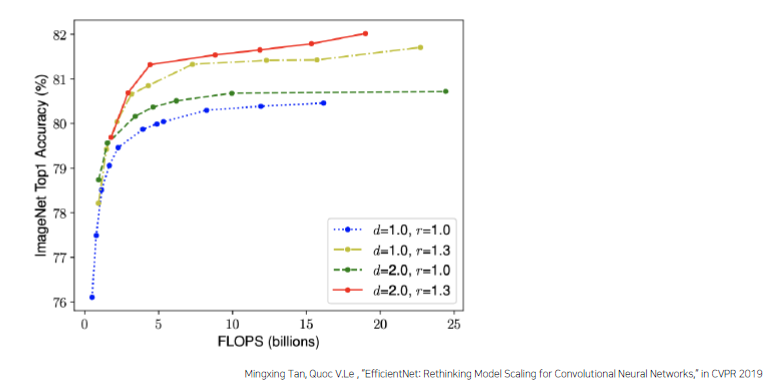
-
- Compound Scaling Method
- Obsevation
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
3. 피어세션 정리
4. 학습 회고
- 가면 갈수록 복잡한 모델들이 너무 많아지는 것 같다. 이해가 잘 안되고 정리도 힘들어진다.
- Efficient Net 추후 다시 복습 + Cascade R-CNN, Transformer.. 다!