
[네이버 부스트 캠프] AI-Tech - Lv2 week4(4)
학습기록 - 42
오늘 할 일
- Neck
1. 강의 복습 내용
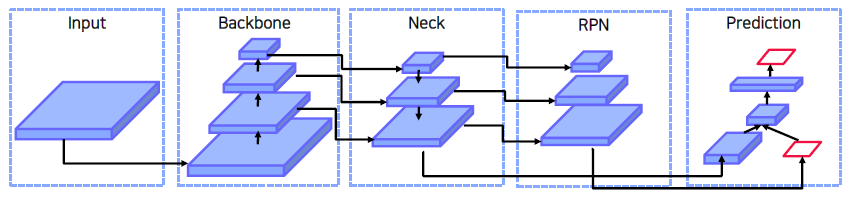
Neck
- Neck은 무엇인가?
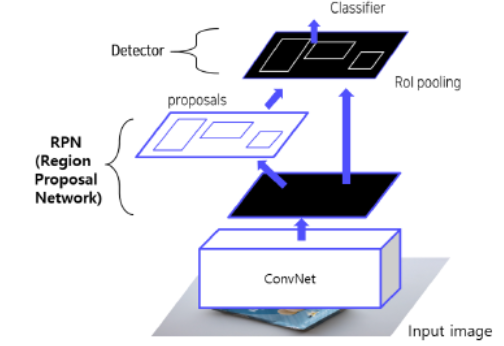
Background 먼저 이전에 다루었던 2-Stages Model은 다음과 같습니다. RoI ( feature map → RPN ) + Feature map → Prediction
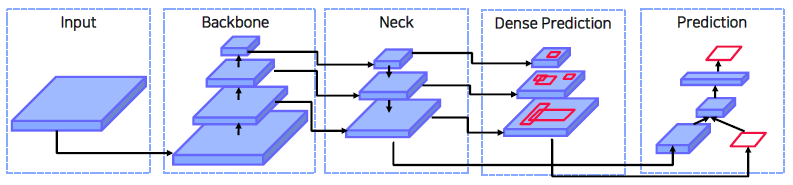
여기서 마지막 feature map만이 아닌 중간 feature map도 이용하자! → ‘Neck’
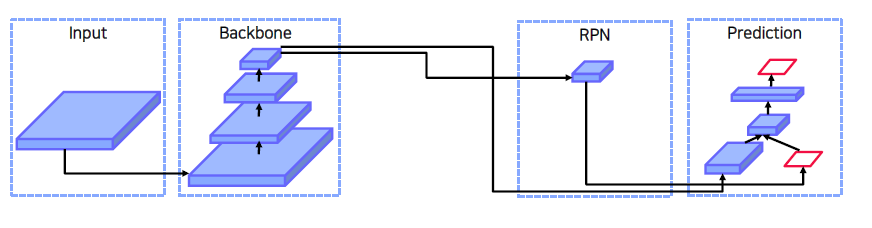
-
Neck은 왜 필요한가?
Image 안에는 다양한 크기의 객체들이 존재한다. 일반적으로 backbone의 모든 layer를 통과한 후엔 semantic한 정보를 가질 수 있는 데에 비해,
high-level의 feature-map은 작은 크기의 객체를, low-level의 feature map은 큰 크기의 객체를 잘 잡아낼 수 있다.
→ 다양한 객체를 탐지하기 위해서 neck이 필요하다. (현재까지도 작은 객체는 제대로 탐지하지 못하는 문제를 가지고 있다.)

High-level

Low-level
Neck이라는 모듈을 두지 않고 Region으로 뽑을 수 있지 않을까?
→ Highs level : Semantic 👍 local 👎
Low level : Semantic 👎 local 👍→ High level feature 와 Low level feature 의 교환이 필요하다.
- FPN (Feature Pyramid Network (FPN)
-
여러 시도들
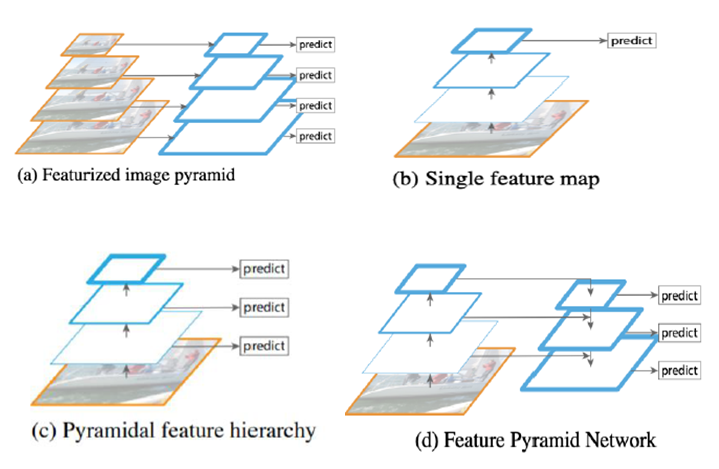
-
high-level → low-level로 semantic 정보 전달 (top-down path way 추가)
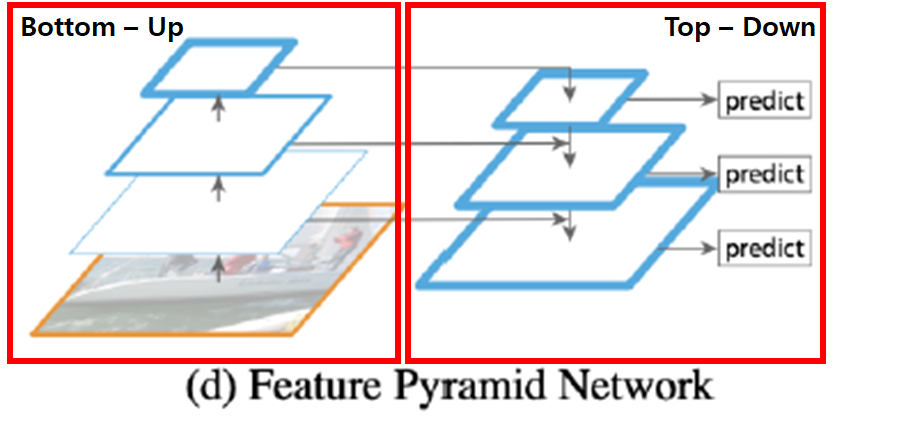
어떻게 하는 것일까?
-
Lateral connections
Bottom-Up에서 나온 feature map → 1x1 conv
Top - Down 의 feature map → 2x upsampling
위 둘의 합을 이용해서 서로의 정보를 얻는다.
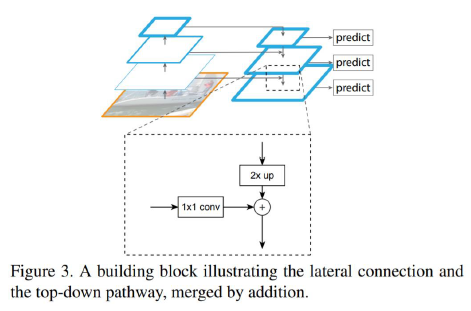
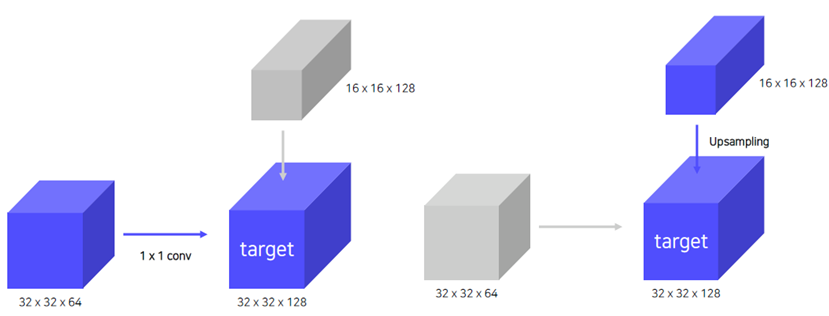
UpSampling 방법은 Nearest Neighbor Upsampling의 방법을 이용한다.
-
Pipeline
ResNet을 Backbone으로 했을 때 각 layer에서 생성되는 feature map에 1by1 convolution 한 feature map (local 정보), 2x upsampling (semantic 정보) 를 합한 후 (Lateral connections), → P5, P4, P3, P2가 나오게 됩니다.
Stage를 통해 나온 P5~P2를 RPN을 통과한 후, 각 Stage에서 RoI가 많이 나오게 되고, NMS를 통해 1000개의 RoI 추출한다. 하지만, 이전과는 다르게 RoI가 어떤 Stage에서 왔는지 mapping이 필요하다.
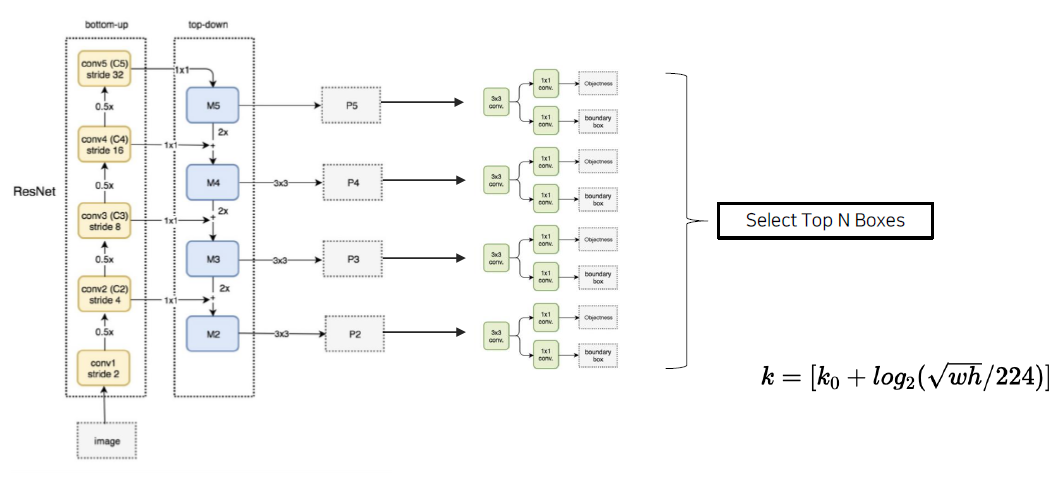
Mapping을 위해 아래와 같은 공식을 이용해서 최종 Stage를 계산하게 된다. (k_0 : stage의 개수) 최종 Stage 계산을 통해 해당 feature map에 대해 RoI Projection을 진행한다.
k가 클수록 높은 Stage에 있고, k가 작을수록 작은 Stage에 있게 된다.
\[k = [k_0 + log_2(\sqrt{w h}/224)]\] - Summary
- FPN은 여러 scale의 물체를 탐지하기 위해 설계했고, 이를 달성하기 위해서 여러 크기의 feature를 사용해야할 필요가 있습니다.
- 이를 위해, Bottom up (Backbone)에서 다양한 크기의 feature map을 추출,
- 다양한 크기의 feature map의 semantic을 교환하기 위해 top-down 방식 사용 ( 교환? )
-
small box 탐지에서 큰 효과를 보여준다.

- Code
-
Build laterals : 각 feature map 마다 다른 채널을 맞춰주는 단계
Build Top-down : channel을 맞춘 후 top-down 형식으로 feature map 교환
Build outputs : 최종 3x3 convolution을 통과하여 RPN으로 들어갈 feature 완성
# build laterals laterals = [lateral_conv(inputs[i]) for i, lateral_conv in enumera(self.laterals_conv)] # build top-down for i in range(3,0,-1): prev_shape = laterals[i-1].shape[2:] laterals[i-1] += F.interpolate(laterals[i], size=prev_shape) # build outputs outs = [self.fpn_convs[i](laterals[i]) for i in range(4)]
-
-
- PANet (Path Aggregation Network)
-
Problem in FPN : Bottom-up Path Augmentation
Bottom-up 과정에서 실제로 ResNet을 이용한다면, 정보 전달이 high-level까지 제대로 전달될 수 없다. 즉, low-level의 local 정보가 high-level 쪽에서는 사라질 수 있다.
따라서, low-level 정보를 최대한 보존하기 위해서 Bottom-up Path Augmentation 방식을 사용한다. ( 빨간색 점선은 기존 FPN, 초록색 점선은 PANet의 정보 흐름)
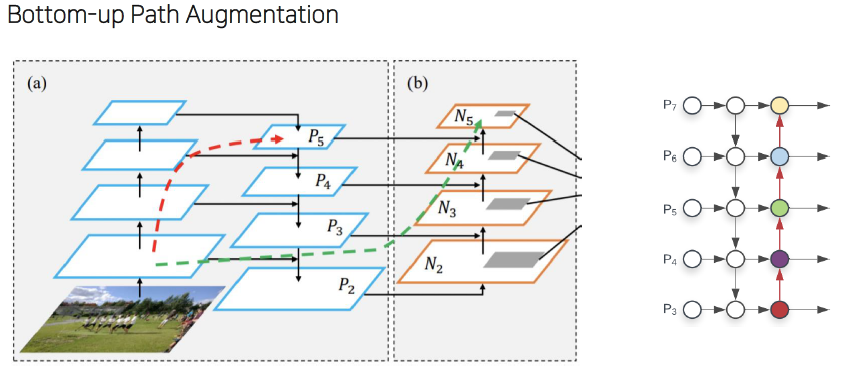
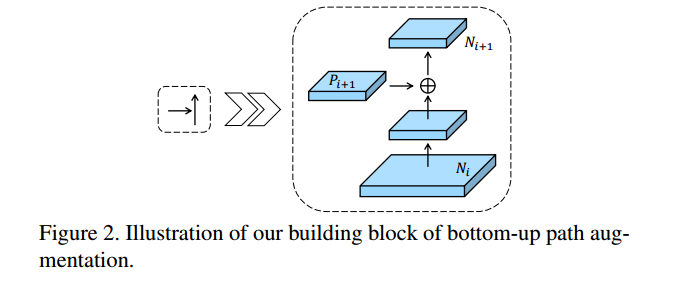
FPN이 생성한 {P2, P3, P4, P5}를 활용하여 {N2, N3, N4, N5}을 생성할 때는, 3x3 stride = 2인 conv layer를 거쳐서 down-sampling하고 P_(i+1)과 lateral connection을 통해 N_(i+1) feature map을 생성합니다.
-
Adaptive Feature Pooling
N2~N5는 각각 RPN을 거쳐서 RoI를 생성하게 됩니다. 그리고 RoI Align(RoI Pooling)을 통해서 일정한 크기의 vector가 생성됩니다.
왜?)
FPN 문제점1) : 이전에 말했던 공식을 이용해서 Stage를 찾게 된다면, 10px 차이에도 stage 선택에 차이가 나게 됩니다. (feature map의 차이)
\[k = [k_0 + log_2(\sqrt{w h}/224)]\]FPN 문제점2) : 모든 RoI를 뽑은 다음에 (1000개) Select N개를 해서 특정 Stage의 Feature map에 대해 RoI를 Projection 할 수 있게 만들었다.
위의 2개의 문제점을 해결하기 위해서 N2~N5의 모든 RoI를 뽑아내서 RoI Projections을 진행하고 RoI pooling을 한 이후에, fc1을 만들어서 max pooling 연산으로 하나로 결합합니다. 하나로 결합된 벡터에서 class와 box를 예측합니다.

(질문) RoI projection을 모든 곳에서 실행한다면, 엄청 많은 양의 box regression이 진행되는건가?
- code
- FPN : Top-down에 3x3 convolution layer 통과하는 것까지 동일
- Add bottom-up : FPN을 통과한 후, bottom-up path 를 더해줌
-
Build outputs : 이후 FPN과 마찬가지로 학습을 위해 3x3 convolution layer 통과
# build outputs inter_outs = [ self.fpn_convs[i](laterals[i]) for i in range(4) # part 2: add bottom-up path for i in range(3): inter_outs[i+1] += self.downsample_convs[i](inter_outs[i]) # build outputs outs = [] outs.append(inter_outs[0]) outs.extend([self.pafpn_convs[i-1](inter_outs[i]) for i in range(1,4)])
- code
-
- DetectoRS
- Motivation - Looking and thinking twice → 무언가를 반복적으로하면 좋은 성능이 나올까?
- Region proposal networks (RPN)
- Cascade R-CNN
-
RFP (Recursive Feature Pyramid)
FPN을 Recursive하게 진행한다!라고 생각하자. Neck (Top-bottom) 만이 학습을 하는 것이 아닌, Neck을 이용해서 다시 Backbone에 학습을 시킬 수 있도록 만든다.
(문제점) Full-loops(?)가 많이 생겨서 연산량이 많아진다. 학습 시간이 매우 오래 걸린다.
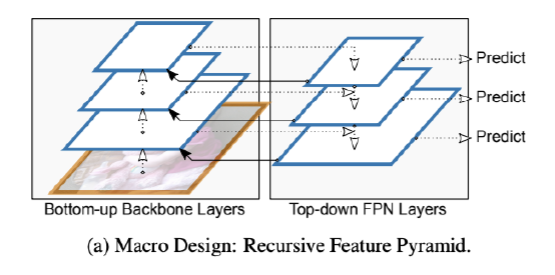
Pipeline은 다음과 같이 수행됩니다. 여기서 Neck에서 수행했던 정보를 다시 Backbone으로 넘겨줄 때, ASPP라는 과정을 이용해서 넘겨주게 됩니다.
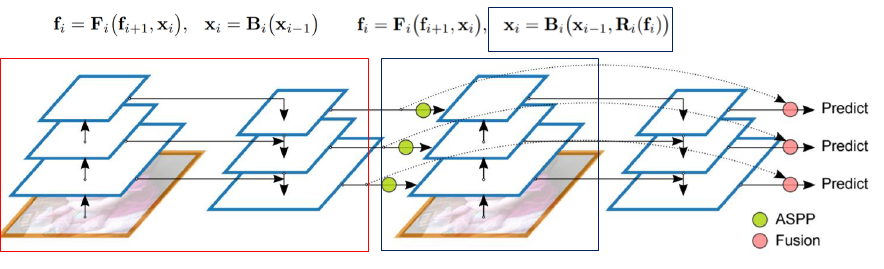
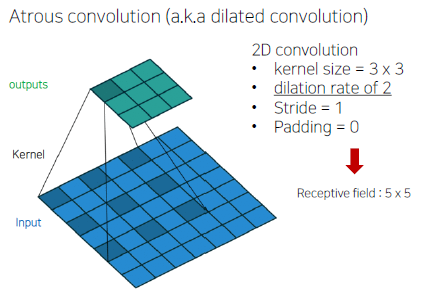
ASPP (Atros Spatial Pyramid Pooling) 란, Atros convolution을 진행해서 만든 여러 layer를 concat해서 만든 것이다. dilation rate를 여러 가지로 주면서 Recptive field를 늘려가며 Atros Convolution을 하게 된다.
Atros Convolution은 다음과 같이 dilation rate에 따라 kernel 사이에 칸을 두고 convolution을 한다. 이를 이용하면 Receptive field가 커지는 효과를 볼 수 있다.
(질문) Receptive field가 커지면 어떤 효과를 얻을 수 있을까?
- Motivation - Looking and thinking twice → 무언가를 반복적으로하면 좋은 성능이 나올까?
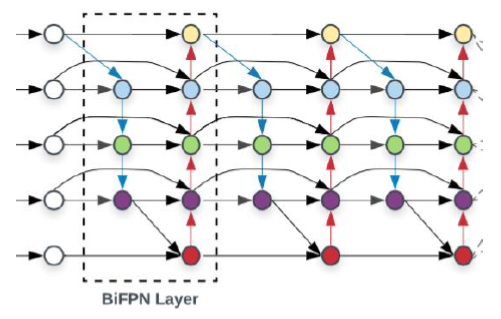
- BiFPN (Efficient Det)
-
Pipline
Top-down의 첫째 노드와 마지막 노드를 지워서 다음과 같이 만들어줍니다.
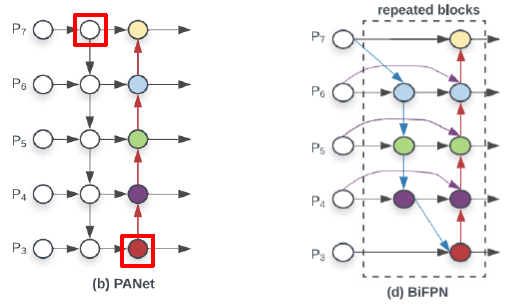
이 논문에서는 FPN의 Lateral connections에 문제를 제기했다. High level 에서 오는 Semantic 정보와 Low level 에서 오는 Local 정보를 단순히 ‘summation’ 한다는 것이 맞지 않다는 것이다.
-
Weighted Feature Fusion
-
Feature별로 가중치를 통해서 중요한 feature를 강조하여 성능을 상승시키자.
학습 또한 가능할 수 있도록 한다.
\[\begin{aligned}P_{6}^{t d} &=\operatorname{Conv}\left(\frac{w_{1} \cdot P_{6}^{i n}+w_{2} \cdot \operatorname{Resize}\left(P_{7}^{i n}\right)}{w_{1}+w_{2}+\epsilon}\right) \\P_{6}^{\text {out }} &=\operatorname{Conv}\left(\frac{w_{1}^{\prime} \cdot P_{6}^{i n}+w_{2}^{\prime} \cdot P_{6}^{t d}+w_{3}^{\prime} \cdot \operatorname{Resize}\left(P_{5}^{\text {out }}\right)}{w_{1}^{\prime}+w_{2}^{\prime}+w_{3}^{\prime}+\epsilon}\right)\end{aligned}\]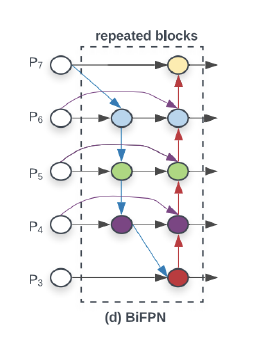
-
-
- NAS-FPN (Neural Architecture Search)
- Motivation
- 위에서 했던 다양한 구조를 더 효율적으로 찾아보자!
- 가장 적합한 FPN구조를 딥러닝을 통해 탐색해보자
-
Architecture
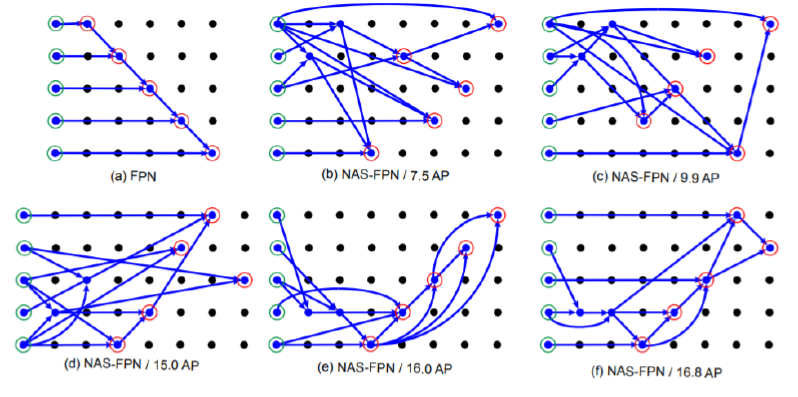
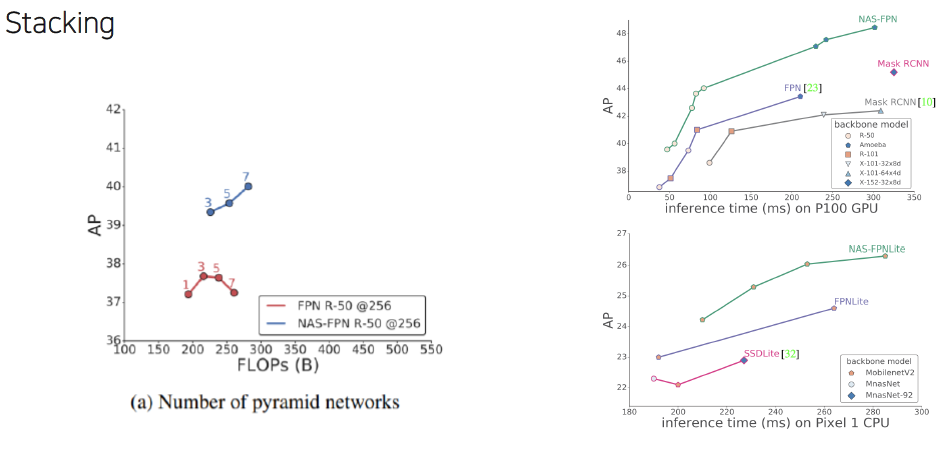
- 단점
- COCO dataset, ResNet 기준으로 찾은 architecture, 범용적이지 못함
- Parameter 많이 소모
- COCO dataset, ResNet 기준으로 찾은 architecture, 범용적이지 못함
- 관련 영상 & 논문
- Motivation
- Aug-FPN
- Motivation - Problems in FPN
- 서로 다른 level의 feature 간에 semantic 차이
- Highest feature map의 정보 손실 (위에서 오는 feature가 없고 단순 conv만 진행)
- 1개의 feature map에서 RoI 생성 (PANet에서 어느 정도 해결) (?)
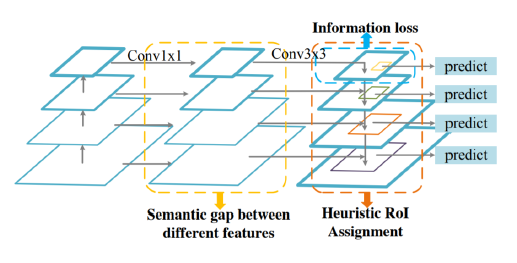
- 주요 구성
- Consistent Supervision
- Residual Feature Augmentation
- Soft RoI Selection
- Resiual Feature Augmentation
-
M6 feature (highest level feature를 추가)
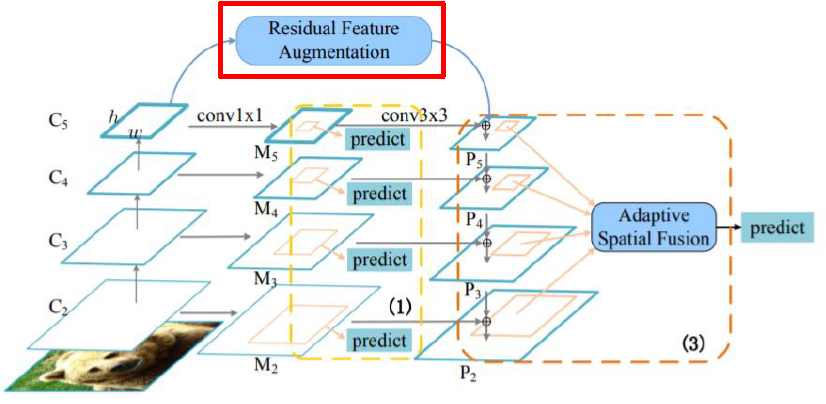
-
Adaptive Pooling을 통해서 Target feature의 size를 다양한 크기로 만들어준다. 그 후, Adaptive Spatial Fusion을 위해서 256 channels로 맞춰준다.
(질문) Adaptive Spatial Fusion이 한번 더 일어난다는 뜻인가?
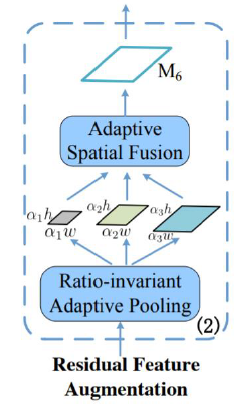
-
Adaptive Spatial Fusion은 Transformer와 유사한 과정으로 소개, 3개의 feature map을 upsample 후, concat하고 각 layer를 통해 N x (1 x h x w)를 만들어준다. 여기서 만들어진 값은 Spatil weight(붉은 박스)를 의미하고 여기에 N개의 feature를 곱해서 가중 summation을 한다.
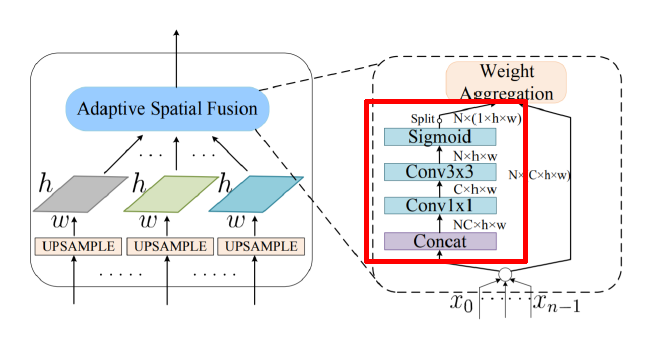
-
- Soft RoI Selection
- FPN 과 같이 하나의 feature map 에서 RoI 를 계산하는 경우 sub optimal
- 이를 해결하기 위해 PANet 에서 모든 feature map 을 이용했지만 , max pool 하여 정보 손실 가능성
-
이를 해결하기 위해 Soft RoI Selection 을 설계
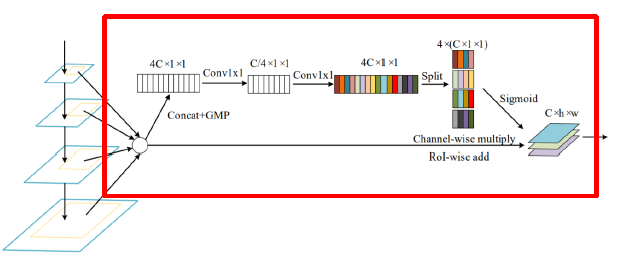
- PANet 의 max pooling을 학습 가능하도록 weight mutilply해준다.
- Motivation - Problems in FPN