
[네이버 부스트 캠프] AI-Tech - Lv2 week4(2)
학습기록 - 40
오늘 할 일
- 2 Stage Detectors (Fast R-CNN ~)
1. 강의 복습 내용
-
Fast R-CNN
-
Overall Architecture

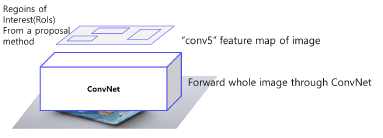
Image를 VGG Net에 Input으로 통과해서 feature map 추출 후, feature map 상에서 RoI를 계산 (RoI projection 이용)
RoI Projection
Selective Search를 이용해서 나온 RoI Image를 feature map의 크기에 맞게 투영시킨다.
RoI Pooling을 통해 일정한 크기의 feature 추출
고정된 vector를 얻기 위한 과정으로 SPP (Spatial Pyramid Pooling)을 그대로 사용한다.
Pyramid level: 1, Target grid size: 7X7 한 개만 이용
(질문) 아래 그림은 Target grid size가 8x8 인데? 3by2 grid로 mining?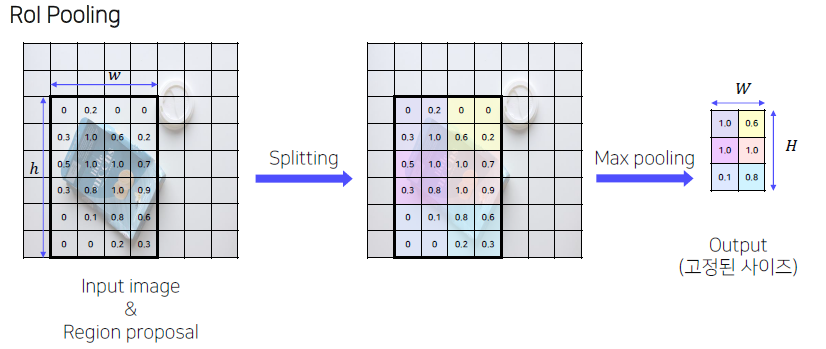
Fully Connected Layer 이후, Softmax Classifier과 Bounding Box Regressor 출력
클래스 개수 (C+1) : 클래스 (C) + 배경 (1)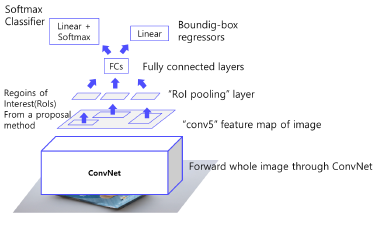
- Training
- Multi task loss 사용 (classification loss + bounding box regression)
- Loss function
- Classification : Cross Entropy, BB regressor : Smooth L1
- Dataset 구성
- IoU > 0.5 : positive samples
- 0.1 < IoU < 0.5 : negative samples
- Positive samples 25%, negative samples 75%
- Hierarchical sampling
- R-CNN 의 경우 이미지에 존재하는 RoI 를 전부 저장해 사용
- 한 배치에 서로 다른 이미지의 RoI 가 포함됨 (1번 이미지에서 RoI를 뽑을 때, 2000장, 2번 이미지에서 뽑을 때, 2000장, … -> Positive, Negative를 골라낸다.)
- Fast R CNN 의 경우 한 배치에 한 이미지의 RoI 만을 포함
- 한 배치 안에서 연산과 메모리를 공유할 수 있음
- Shortcomings
1), 2), 3) 해결, but, 4)는 애매해진다.
Fast R-CNN 같은 경우엔, Selective Search가 CPU에서 돌아가는 알고리즘이기 때문에, end-to-end라고 볼 수 없다.
-
-
Faster R-CNN
-
Pipeline
RPN(Region Proposal Network)를 이용해서 Selective Search 대체
Overall Architecture
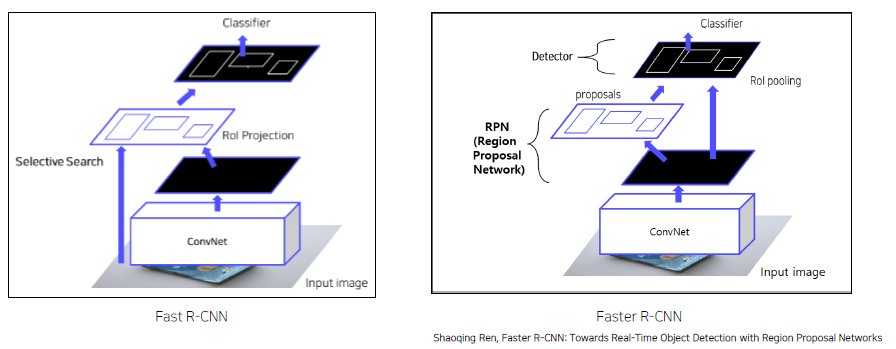
이미지를 CNN에 넣어 feature maps 추출 (CNN을 한 번만 사용)
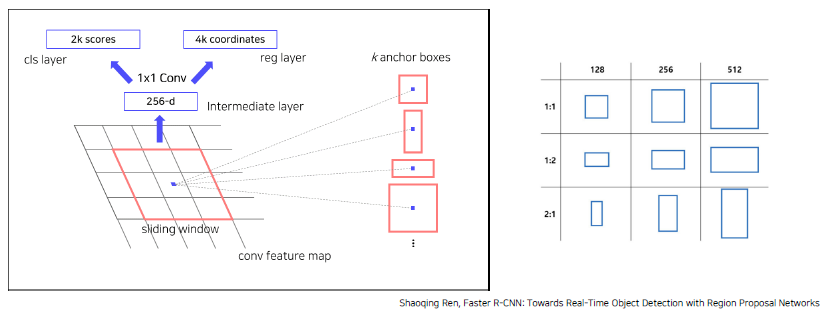
RPN을 통해 RoI 계산 (Anchor box 개념을 사용)Anchor box는 feature map이 vector형식으로 나왔을 때, 각 셀마다 여러 개의 크기를 가진 box를 두는 것을 의미한다.
하지만 각 셀 별로 모두 앵커 박스를 갖고 있다면, 그 역시 갯수가 많아지게 된다.
RPN은 앵커 박스가 객체를 포함하고 있는 지 예측하는 근거 (2k scores) 와 객체를 포함한다면, 앵커 박스의 bounding box를 미세 조정 (4k coordinates) 을 하는 역할
Faster R-CNN에서는 9개의 anchor box를 이용하게 된다. (3가지 scale, 3가지 비율)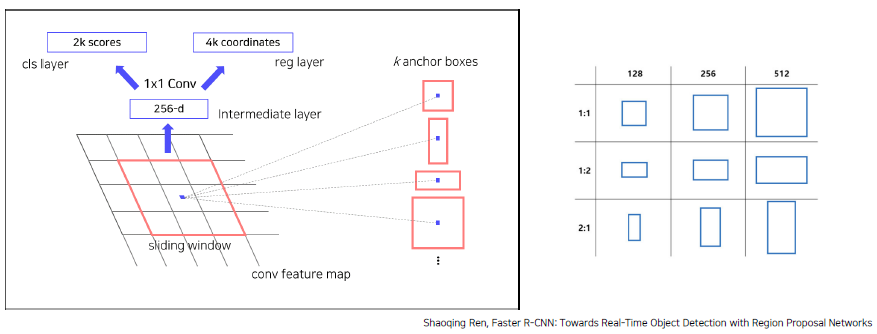
RPN에 대한 더 자세한 설명을 하자면,
CNN을 통해서 나온 Feature Map에서 3by3 conv를 통해서 Intermediate layer 생성
(질문) Intermediate layer를 생성한 이유는? 학습을 위해서 convolution을 적용한 것인가?
1by1 conv 수행해서 binary classification, bounding box regression 수행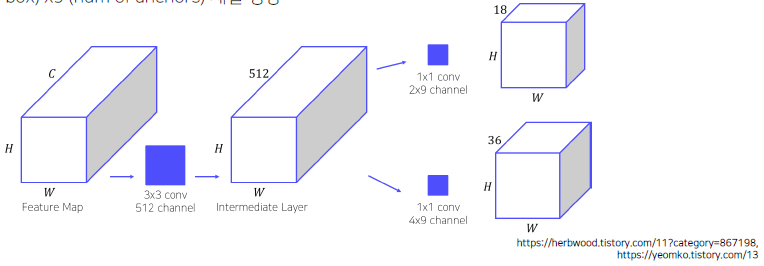
평면화를 해보면, 다음과 같이 나타낼 수 있다.
(질문) 각 셀마다 anchor box를 generator를 한다고 했는데 하는 이유는? 굳이 안해도 위에서처럼 1by1 conv layer를 통해서 만들 수 있지 않을까?
Cls prediction head를 통과한다면 score가 나올텐데, score를 통해서 Select Top N Boxes를 할 수 있다. Top Boxes를 대상으로 Coordinates를 적용할 수 있게 된다. (재조정)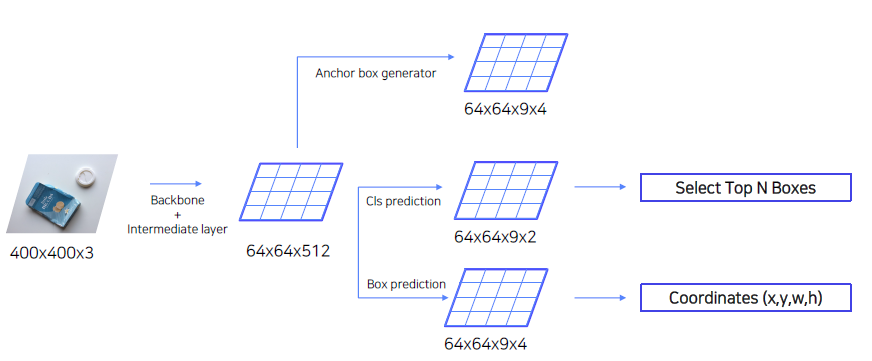
NMS (Non-Maximu Suppression)
- 유사한 RPN Proposal 제거에 사용
- Class score를 기준으로 Proposals 분류
- IoU가 0.7 이상인 proposals 영역들은 중복된 영역으로 판단한 뒤 제거
아래와 같이 box에 대한 class score를 나타낼 수 있다.
(질문) bb4는 score가 0인데 없애지 않고 bb1과 비교하는 것일까?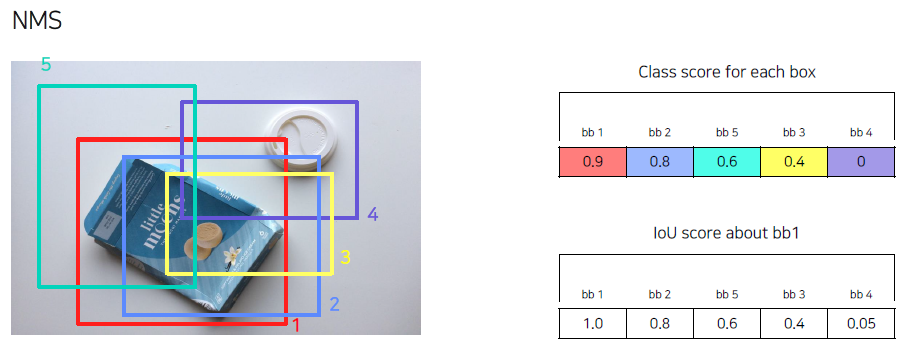
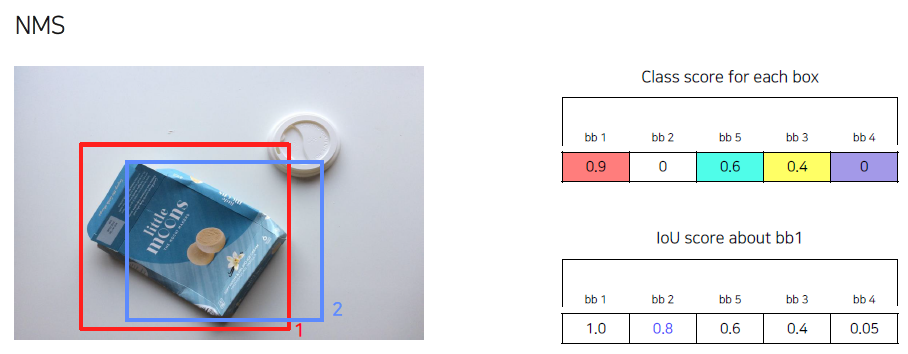
가장 class score가 높은 bb1에 대해서 나머지 bbox의 IoU를 나타내면, 다음과 같다. 여기서 IoU가 0.7이상 즉, 거의 비슷할 경우, 제거한다.
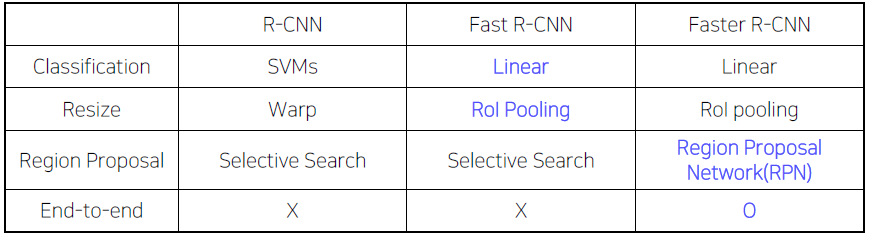
Fast R-CNN vs Faster R-CNN
두 모델의 차이점은 RoI Projection 이전에 RoI를 어떻게 뽑느냐에 따라 달라지는 것이다.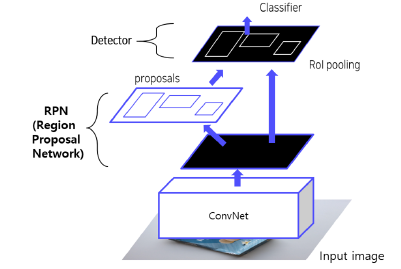
-
Training
- RPN 단계에서 classification 과 regressor 학습을 위해 앵커박스를 positive/negative samples 구분
- 데이터셋 구성
- IoU > 0.7 or highest IoU with GT: positive samples
- IoU < 0.3: negative samples
- Otherwise : 학습데이터로 사용 X
- Loss 함수 (Fast R-CNN과 동일)
Multi-task로 학습을 한다. (Lcls : CE Loss, Lreg : MSE)
pi*는 i번째 anchor box가 객체를 포함하고 있는 지에 대한 의미.
$L\left(\left{p_{i}\right},\left{t_{i}\right}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{}\right)$ $+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{} L_{r e g}\left(t_{i}, t_{i}^{*}\right)$
-
paper에서는 다음과 같이 Alternative training을 활용한다.
Step 1) Imagenet pretrained backbone load + RPN 학습
Step 2) Imagenet pretrained backbone load + RPN from step 1 + Fast RCNN 학습
Step 3) Step 2 finetuned backbone load & freeze + RPN 학습
Step 4) Step 2 finetuned backbone load & freeze + RPN from step 3 + Fast RCNN 학습하지만, 학습 과정이 매우 복잡해서, 최근에는 Approximatel Approximate Joint Training 활용
Results를 보면 다음과 같이 Selective Search에 비해서 성능과 속도가 개선된 것을 볼 수 있다.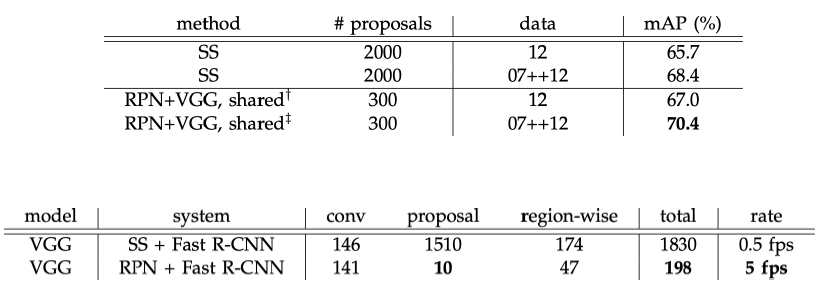
-
ShortComings
이전에 R-CNN, Fast R-CNN에서 가지고 있던 단점들 (1,2,3,4) 모두 없앨 수 있었다. 하지만 RPN, NMS를 하고 Fast R-CNN을 그대로 한다는 점에 있어서 Real-time이 매우 느리다는 한계점이 있다.
-
-
Summary
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
질문
(질문)
아래 그림은 Target grid size가 8x8 인데? 3by2 grid로 mining?
Sol. Paper에서는 Target Size가 7x7 size로 고정했을 뿐, Input size에 따라 RoI가 가변적일 수 있기에 Target Size 또한 바뀔 수 있습니다!
(질문)
-
Intermediate layer를 생성한 이유는? 학습을 위해서 convolution을 적용한 것인가?
Sol. Intermediate layer는 CNN의 중간 단계 (conv5) 모든 convolution 단계를 빠져나온 상태의 layer를 의미한다. (Intermediate : 중간의) -
각 셀마다 anchor box를 generator를 한다고 했는데 하는 이유는? 굳이 안해도 위에서처럼 1by1 conv layer를 통해서 만들 수 있지 않을까?
Sol. 9 개의 anchor box를 generate 하는 과정이고, generate된 9개의 박스에서 1 by 1 convolution 을 통해 score와 coordinates로 나눠지게 된다.
++ Generate는 HyperParameter에 의해 결정되어진다.
(질문) bb4는 score가 0인데 없애지 않고 bb1과 비교하는 것일까?
위에서 말하는 class score for each box는 객체를 검출했는 지에 대한 Bounding box의 생성 여부를 score로 나타낸 것이고, 이 Bounding box들 중에서 같은 객체를 가리키는 많은 정보를 가진 (IoU ≥ 0.7) bbox를 지우는 방식이다. 따라서 bb4는 우리가 알고자하는 객체의 연관성을 나타내기 때문에 삭제를 하지 않는 것이다.
추가로, RPN 단계에서 Dataset 구성 시에 IoU에 따라 sample을 다르게 지정한다. (강의자료-77P)

과제
3. 피어세션 정리
1,2강 강의정리 발표자: 김준영
📢질문
Q.Fast R-CNN - SPP Grid Size는 Input Image에 따라 가변적이어야 하나?
Q.Faster-R-CNN - Feature Map에서 Intermediate layer를 생성하는 이유? & Generate 하는 이유 ?
Q.RPN 이후, NMS에서 class score가 0인데도 비교하는 이유?
📢각자한거 공유
김준영 - special mission, (EDA)Draw_BB 공유 임성민 - special mission - 서버 기준 코드 사용 » coco데이터 사용하면 안됨 / CosineAnnealing 효용성 없음 / Adam과 loss 차이 크게 없음 SGD가 속도는 더 빠름 / EDA 관련 작성 김현수 - 베이직 코드 안소정 - 베이직 코드 김건 - 베이직 코드 황주영 - 베이직 코드
📢협업관련
- 각자 코드를 완성 할 수 있을 정도가 되는 것을 목표하되 각자 분야를 나눠서 구현한다. 비슷한 내용이라 나눠서 구현해도 금방 배울 수 있을거 같다. 서로 보완을 할 수 있을거 같다.
- 3가지 라이브러리에 대해 3팀을 나누어 진행해 공부하고 서로 리뷰해주며 공유하기.
faster_rcnn » 김현수, 안소정 detectron2 » 임성민, 황주영 mmdetection » 김준영, 김건