
[네이버 부스트 캠프] AI-Tech - Lv2 week4(1)
학습기록 - 39
오늘 할 일
- Object Detection
- 2 stage Detectors
1. 강의 복습 내용
Object Detection
-
Task
Semantic Segmentation + Object Detection -> Instance Segmentation
Real World에서의 Object Detection 예시
-
History of Object Detection
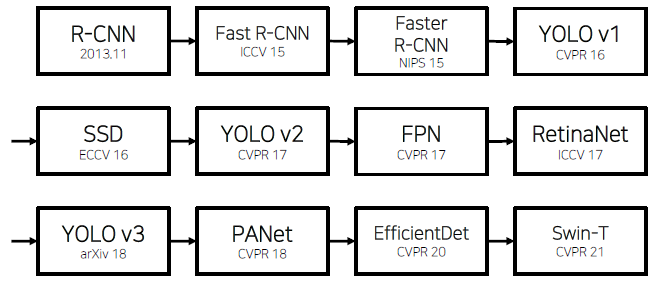
-
Evaluation
성능 : mAP , 속도 : FPS, Flops-
mAP (mean average precision) : 각 클래스당 AP의 평균
PR Curve
모든 예측에 대해서 confidence를 기준으로 내림차순 정렬했을 때, 각 row별로 Recall, Precision을 구해서 그래프로 나타냈을 때,
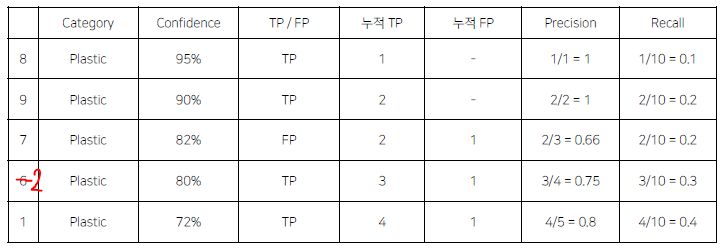
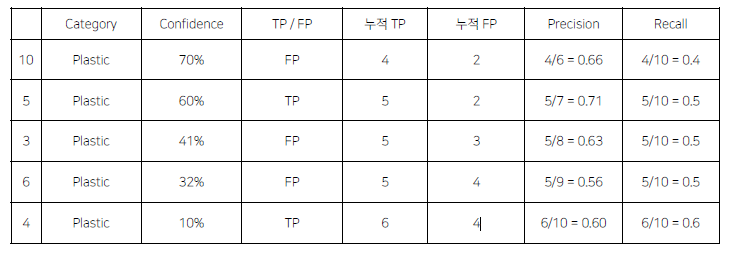
PR Curve
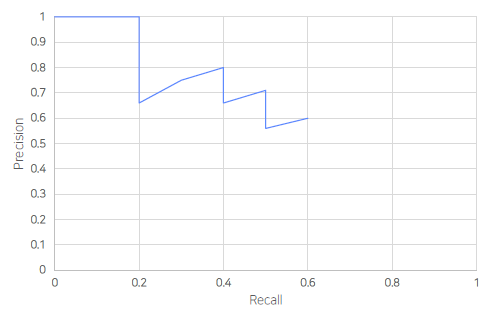
AP (면적)
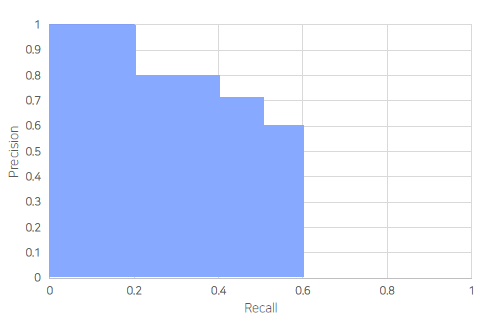
여기서 mAP는 class별로 위와 같이 AP를 구해서 Sum을 하고 class의 수로 나눴을 때, mAP라고 한다.
$mAP= \frac{1}{n} \sum_{k=1}^{k=n} AP_{k}$
$AP_{k}=$ the AP of class k
$\mathrm{n}=$ the number of classesIOU (Intersection Over Union)
박스의 교차 비율에 따라 TP, FP를 결정한다.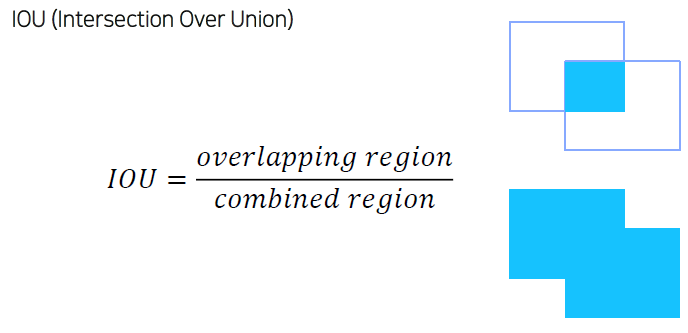
mAP50, mAP60, mAP70, … : mAP와 IOU의 비율을 얼마나할 것인지 정하는 것
-
FPS, FLOPs
FPS (Frame Per Second) : 초당 프레임이 생성되는 횟수, 높을수록 빠르다는 것을 의미한다.FLOPs (Floating Point Operations) :
Model이 얼마나 빠르게 동작하는 지 측정하는 metric
연산량 횟수 (곱하기, 더하기, 빼기 등)
아래의 그림을 보면 한 셀당 곱하기, 더하기 연산을 통해 총 얼마나 연산을 하는지 횟수를 알아볼 수 있다.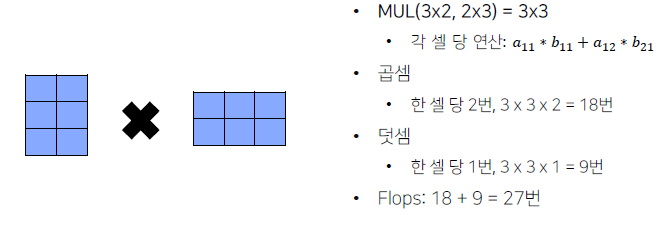
Convolution Layer의 경우, FLOPs는 다음과 같다.
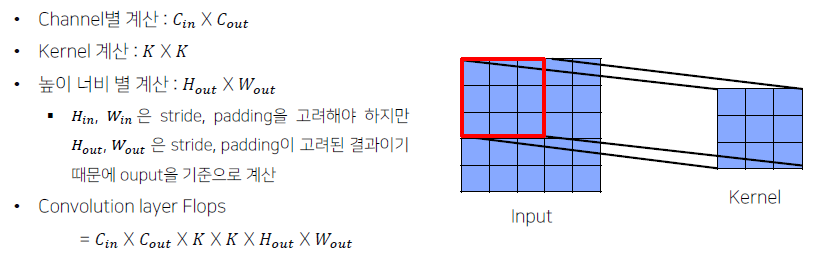
-
-
Library
-
MMDetection : Pytorch 기반의 Object Detection을 위한 오픈 소스
-
Detectron2 : Detectron 2 는 페이스북 AI 리서치의 라이브러리로 pytorch 기반의 Object detection 과 segmentation 의 알고리즘을 제공
-
YOLOv5 : coco 데이터셋으로 사전 학습된 모델로 수천 시간의 연구와 개발에 걸쳐 발전된 Object Detection 모델
-
EfficientDet : EfficientNet을 응용해 만든 Object Detection 모델
-
-
Object Detection Domain 특성
- 통합된 Library의 부재
- 엔지니어링적인 측면 강함
- 어떤 모델이 풀고자 하는 문제에 적합한지 실험적인 증명이 필요
- Custom, tuning 하는 과정에서 개발 수준의 활용 필요
- 복잡한 파이프라인, 무거운 모델, 사진의 크기 (Resolution)
2 Stage Detectors
2 Stage Detectors
다음과 같이 이미지의 위치를 특정 짓고, 해당 객체가 무엇인지까지 알아내는 것
-
R-CNN
R-CNN은 큰 그림으로 봤을 때, 입력 이미지를 가져와서 후보 영역을 뽑아내고, 고정된 사이즈로 바꿔서, CNN에서 Semantic feature vector로부터 객체를 판단한다.

후보군을 뽑아내는 방법인 Sliding Window 방식은 무수히 많은 후보 영역이 나오게 되는 데 대부분은 배경이다. -> 비효율적
Selective Search 방식은 이미지의 특성 (색깔, 질감, shape 등)을 활용해서 이미지를 무수히 많은 작은 영역으로 나눈 후에 통합해서 후보 영역 추천 -> R-CNN에서 많이 활용된다.
-
Pipeline
입력 이미지에서 Selective Search를 통한 2000개의 RoI(Region of Interest) 추출
RoI(Region of Interest)의 크기 (모두 다른 크기)를 모두 동일한 사이즈로 변형 (Warping)
CNN의 마지막, FC layer의 입력 사이즈가 고정이기 때문이다.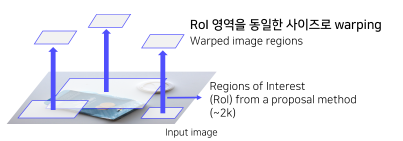
FC layer는 faltten을 이용해서 classifier하는 부분이기 때문에 layer는 고정되어 있다. 그런데 Selective Search를 통한 RoI는 각각이 다른 이미지이기 때문에 동일한 크기로 Warping을 해야한다.
warping된 ROI를 CNN에 넣어, feature를 추출한다.
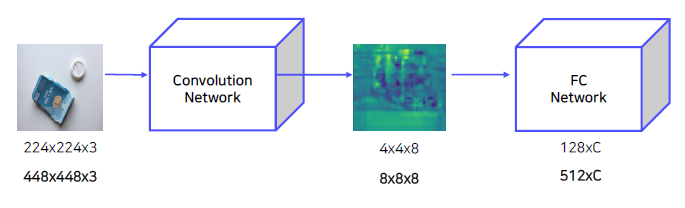
이 때, CNN은 Pretrained AlexNet 구조를 활용 (FC layer 추가 & 필요에 따라 Finetuning 진행)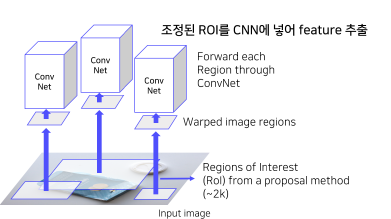
Feature를 SVM에 넣어 분류 진행
Input : 2000 X 4096 features
Output :
Class (C+1) + Confidence scores,
클래수 개수(C) + 배경 여부(1개)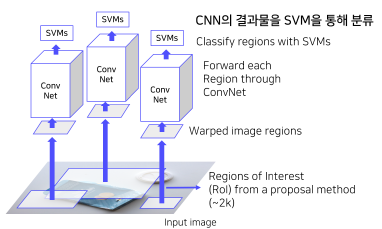
Selective Search를 통해 나온 위치를 box regression을 통해서 미세 조정을 해준다. Selective Search를 통해 나온 bounding box는 target 위치를 대충 그려주는 역할이었는데 bbox reg를 통해서 ground truth에 가깝게 미세조정을 해준다. (localization)
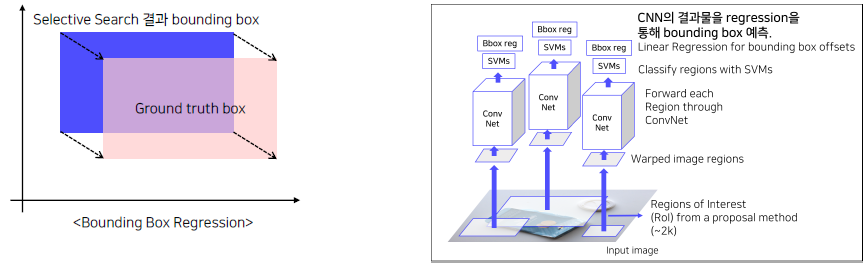
- Training
- AlexNet
- Domain Specific finetuning
- Dataset
- IoU > 0.5: positive samples
- IoU < 0.5: negative samples
- Positive samples 32, negative samples 96 (하나의 배치 구성)
- Linear SVM
- Dataset 구성
- Ground truth: positive samples
- IoU < 0.3: negative samples
- Positive samples 32, negative samples 96
- Hard negative mining
- Hard negative: False positive
- 배경으로 식별하기 어려운 샘플들을 강제로 다음 배치의 negative sample 로 mining 하는 방법
- 모델이 구별하기 어려운 데이터 셋을 강제로 다음 배치에 넣어서 더 학습을 잘할 수 있도록 한다. region의 quality를 높게 하기 위해서 mining을 진행한다.
- Dataset 구성
- Bbox regressor
- Dataset 구성
- IoU > 0.6: positive samples
- Loss function
- MSE Loss
- Dataset 구성
- AlexNet
-
Shortscomings
1) 2000개의 Region을 각각 CNN에 통과 -> 속도가 매우 느림
2) 강제 warping -> 성능 하락
3) CNN, SVM, bbox 따로 학습 4) End to End X1), 2) 의 단점을 보완하기 위해 SPP(Spatial Pyramid Pooling) 이용
-
-
SPP Net
R-CNN의 한계점 보완
warping을 하지 않고 고정된 size의 feature vector로 전환 해준다.
Overall Architecture
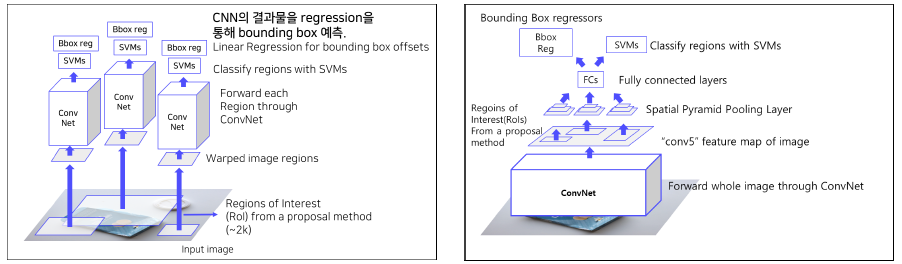
1) R-CNN의 경우, 2000개의 Region을 뽑아내는 과정이 Input Image에서 다 뽑아낸다. SPP Net의 경우, Conv Net을 거친 후에 conv5의 feature map에서 뽑아낸다.
2) Warping VS Spatial Pyramid pooling layer
-
Spatial Pyramid Pooling
(질문) 같은 feature map에 대해서 RoI를 1by1, 4by4, 16by16 각각으로 쌓는 뜻인가?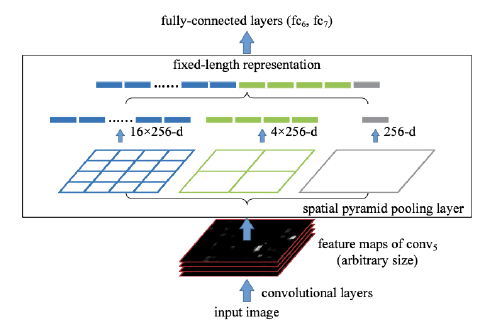
1), 2) 의 단점을 없앤다. 하지만 3), 4) 의 단점은 아직 존재
-
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
detectron2를 이용해서 모델 돌리기… 진짜 어려운디..?
3. 피어세션 정리
4. 학습 회고
- P-stage 시작이다. 엄청 어려울 수도 있고 멘탈이 많이 흔들릴 수도 있다. 잘 잡고 해결해보자. 여기서는 끈기와 인내심이 많이 요구될 것 같다. 공부도 빼먹지 않고 많이 하자.