
[네이버 부스트 캠프] AI-Tech - Lv2 week3(2)
학습기록 - 38 (특강)
오늘 할 일
- 특강
1. 강의 복습 내용
ML Engineer
-
Full stack ML engineer
- ML Engineer 란?
Machine learning (Deep learning) 기술을 이해하고, 연구하고, Product를 만드는 Engineer
전통적인 기술의 경우 Research 영역과 Engineering 영역이 구분 되지만, Deep learning의 경우 발전 속도로 인해 경계가 모호
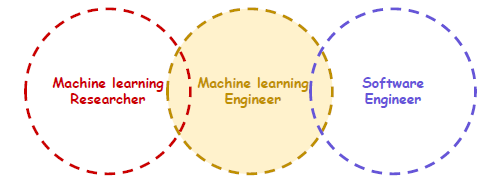
- Full Stack?
Client/Server software를 개발할 수 있는 사람 (Web)
코딩을 잘하고, 창의적이고, 다양한 조직의 사람과 협업이 가능, 새로운 기술을 배우는 것을 좋아하는 사람.
시간만 있다면 혼자 만들 수 있는 사람!
- Full stack + ML?
Deep Learning research 를 이해 + ML Product 로 만들 수 있는 Engineer
ML Service?
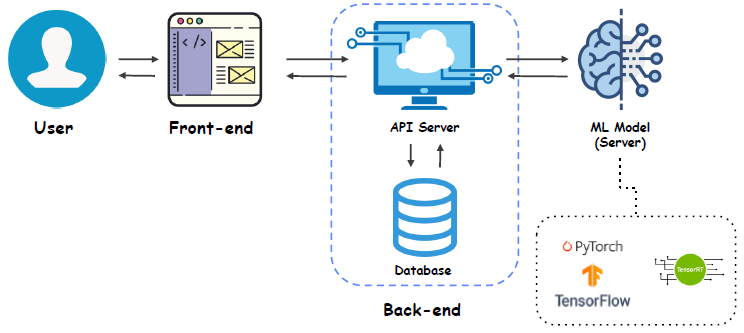
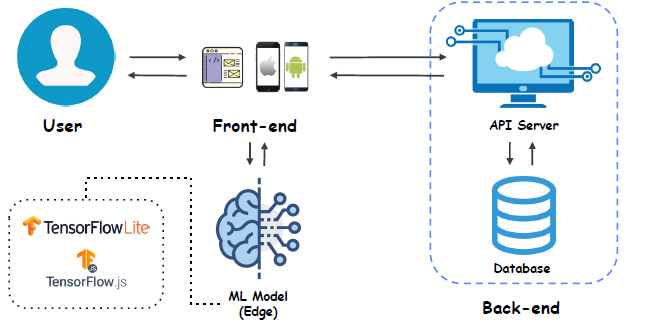
Edge device service
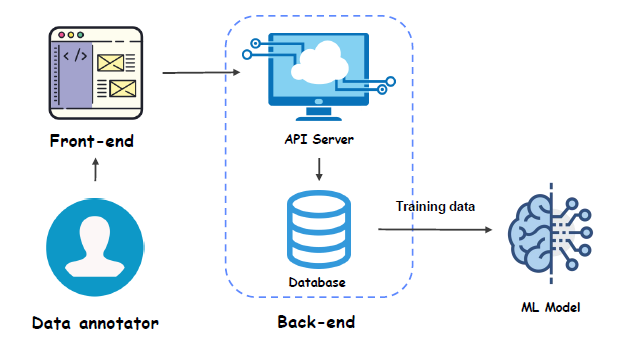
Data collection
- ML Engineer 란?
-
장단점?
-
장점?
재밌다!, 빠른 프로토 타이핑 (스스로 만들어 테스트), 기술간 시너지, 팀 플레이, 성장이 다각화 (연구자 + 개발자 + 기획자 -> 성장의 밑거름) -
단점?
깊이가 없어질 수도 있다. (CS, ML 분야에 대한 연구 활발), 시간이 많이 들어간다,
-
-
ML Product
-
과정
요구사항 전달 -> 데이터 수집 -> ML 모델 개발 -> 실 서버 배포-
요구사항 전달
고객의 요구사항을 수집
B2B, B2C / 요구사항 + 제약사항 정리 / ML Problem 회귀 (머신러닝으로 풀릴지?) -
데이터 수집
Raw 데이터 수집 (Bias, 저작권 x)
Annotation Tool 기획 및 개발 (labeling)
Annotation Guide 작성 및 운용 -
ML 모델 개발
기존 연구 Research 및 내재화
실 데이터 적용 실험 + 평가 및 피드백
모델 차원 경량화 작업 (Distillation, Network surgery) -
실 서버 배포
엔지니어링 경량화 작업
연구용 코드 수정 작업 (연구용 코드 x 배포용 코드 o)
모델 버전 관리 및 배포 자동화
-
-
-
ML Team
실 생활 문제를 ML 문제로 Formulation
Raw Data 수집
Annotation tool 개발
Data version 관리 및 loader 개발
Model 개발 및 논문 작성
Evaluation tool 혹은 Demo 개발
모델 실 서버 배포 -
Roadmap
-
시작이 가장 어렵다!
익숙한 언어 + 적은 기능 + 가장 쉬운 Framework로 시작, 필요에 의해 원론 공부! -
처음부터 ‘잘’ 만드려고 하지말고, ‘빨리’ 완성해보자. 어설프더라도 만들어보자!
-
새로운 것에 대한 두려움을 없애기 위해 반복적으로 접하자.
-
전문 분야를 정하자!
-
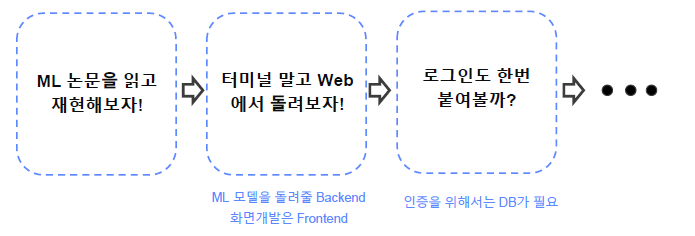
“만들고 싶은 것을 만드세요!” -> 하나의 논문을 구현하고, Demo page를 만들어보자. 터미널 말고 Web에서 돌려보자!
-
AI-Ethics
AI-Research Engineering
학교? 회사? -> 두 조직의 목표를 알자
회사 : AI로 기존 비즈니스를 더 잘하려는 회사 vs AI로 새로운 비즈니스를 창출하려는 회사
AI Engineer는 모델링 뿐만 아닌 다른 여러 업무들의 비중이 훨씬 많다. 현실에서는 다양한 역할이 있고, 여기에 100% 하나의 포지션을 수행하는 경우는 드물다. (다양한 pool이 있다.)
내가 어디에 강점을 가지고 어디에 엣지를 가질 지 판단
-
Understand yourself
- 비즈니스, 사람들의 실생활
-
AI competition 이용
-
최신 논문 재현
-
끈기있는 자세! 겸손함! 열정! 팀웍! 친절함! 내가 사장이 된다면 나를 뽑을 수 있을까?
-
팀에 기여할 수 있는 나만의 엣지를 키우자!
선택 그 자체보다 중요한 것은 나의 선택을 최고의 선택지로 만드는 것이다!
Language Modeling
주어진 문맥을 활용해 다음에 나타날 단어 예측하기
문장의 확률 이용해서 다음 단어를 예측

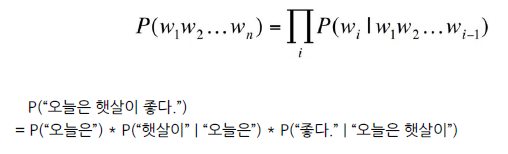
RNN의 방식을 이용
양방향 언어 모델링 (Bidirectional Language Modeling)
-> ELMO (Embeddings from Language Models)
-
ELMO Forward LM : 그 다음 단어를 예측하는 것(?)
Backward LM : 맨 뒤에서부터 이전에 단어를 예측하는 것(?)
이 둘의 Emdedding을 이용해서 예측 수행
-> 다양한 Task에 대해서 성능이 좋아졌다. 즉, 언어 모델이 단순한 다음 단어 예측이 아닌 여러 방향으로 쓰일 수 있다는 것을 알게됨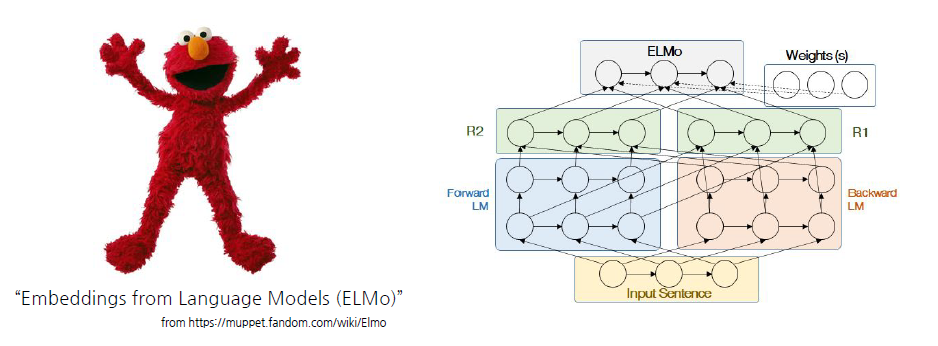
-
BERT (Bidirectional Encoder Representations from Transformers)
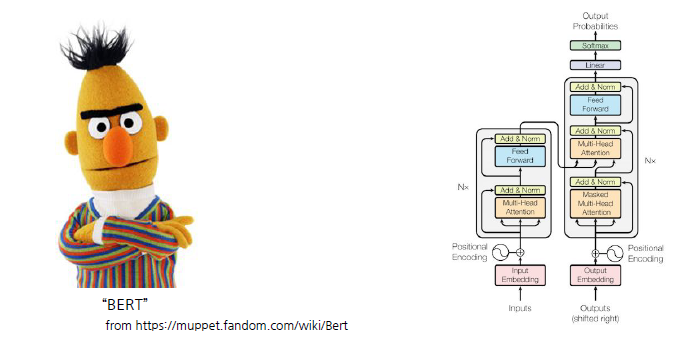
Pre-trained Model을 활용해서 Fine-tuning을 이용하면 어느 정도 잘된다. 다양한 데이터셋에서 기본적으로 성능이 잘 나오게 된다.
일반적으로 사람이 말하는 것에 있어서 잘 나온다는 것을 보여준다. -
GLUE 벤치마크
언어 모델 평가를 위한 영어 벤치마크 (공통된 평가체계, BERT에 의해서 굳어진 평가 데이터들을 의미)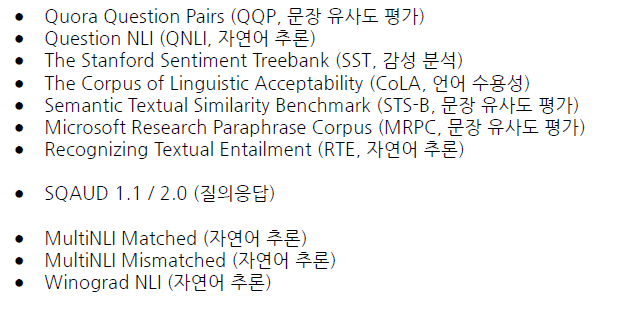
자연어 생성 모델의 평가에 활용됨
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
3. 피어세션 정리
4. 학습 회고
- 저작권, 환경, ethics, ML Engineer로써 다양한 포지션들