
[네이버 부스트 캠프] AI-Tech - Lv2 week2(6)
학습기록 - 36
오늘 할 일
- Instance/Panoptic Segmentation and Landmark Localization
- 코어타임 때 못했던 것 다시 복습
1. 강의 복습 내용
Instance segmentation
Instance segmentation = Semantic segmentation + distinguishing insatnces
-
Instance Segmenters
-
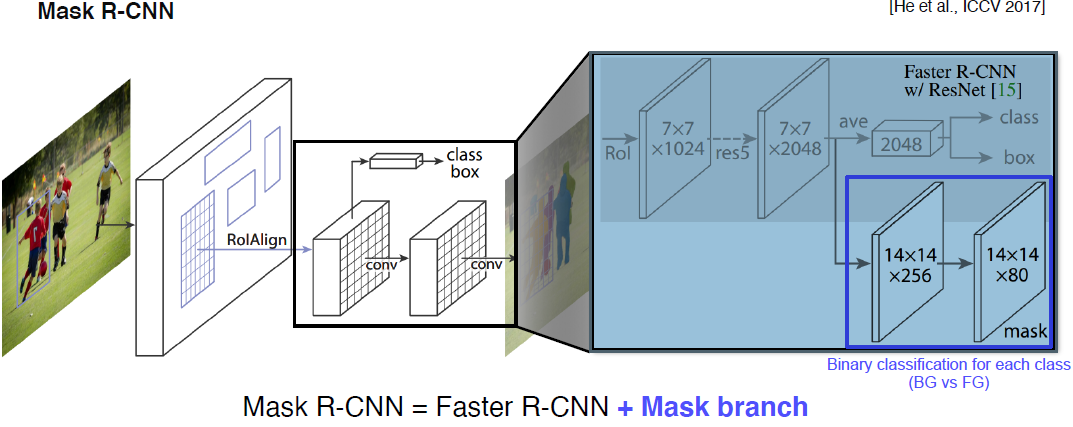
Mask R-CNN
기존 RoI pooling은 RoI Align 방식을 이용하는 데, 이전에 했던 방법은 ‘정수형’을 이용했지만 RoI Align 방식은 Interpolation을 이용하여 소수점까지 지원 가능
Mask R-CNN = Faster R-CNN + Mask branch
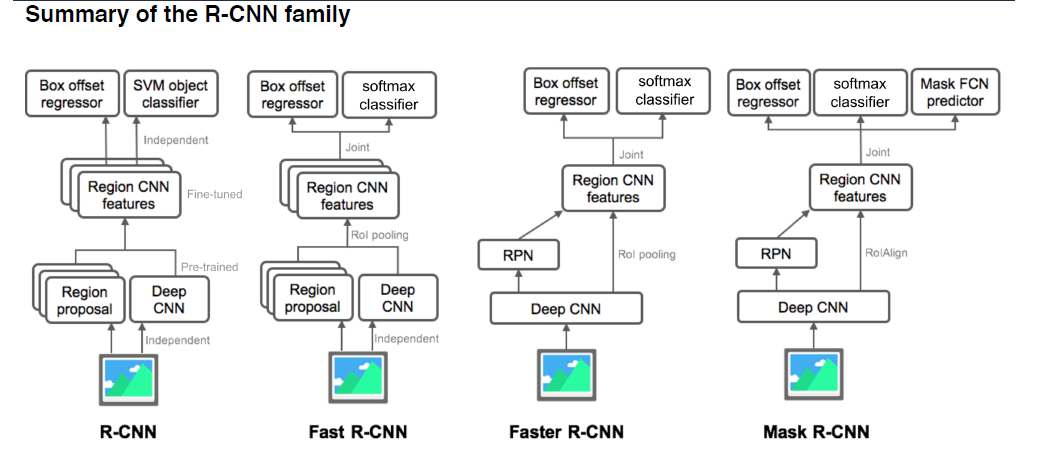
Summary of the R-CNN family
-
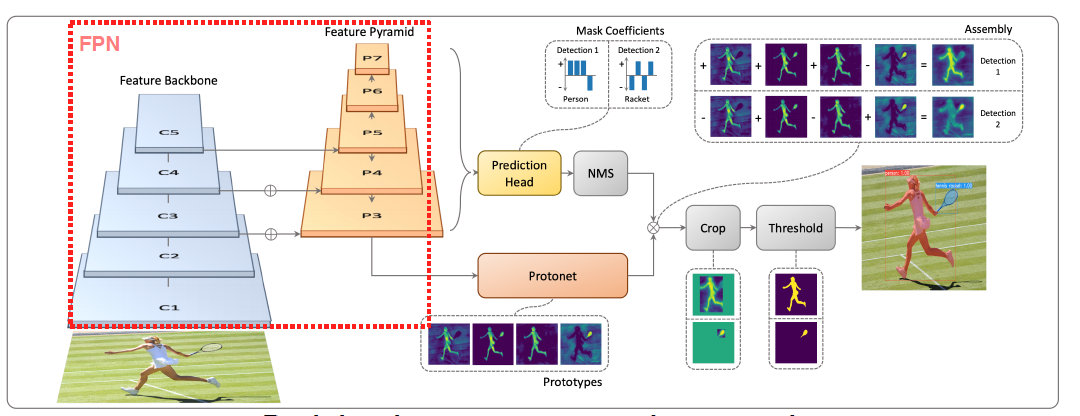
YOLACT
Single Stage 구조, Real time instance segmentation network
prototypes : Mask를 생성해낼 수 있는 component들을 생성해낸다.
prediction head : prototype을 잘 합성하기 위한 계수들을 생성
object마다 Mask를 생성하는 것이 아닌 prototype과 prediction head와의 선형 결합을 통해 조금 더 효율적인 마스크 생성이 키 포인트다.
-
YolactEdge
소형화된 모바일 시스템을 위해 좀 더 획기적이 방법을 이용
feature를 전달한 속도 개선
아직까지 한계점이 많다.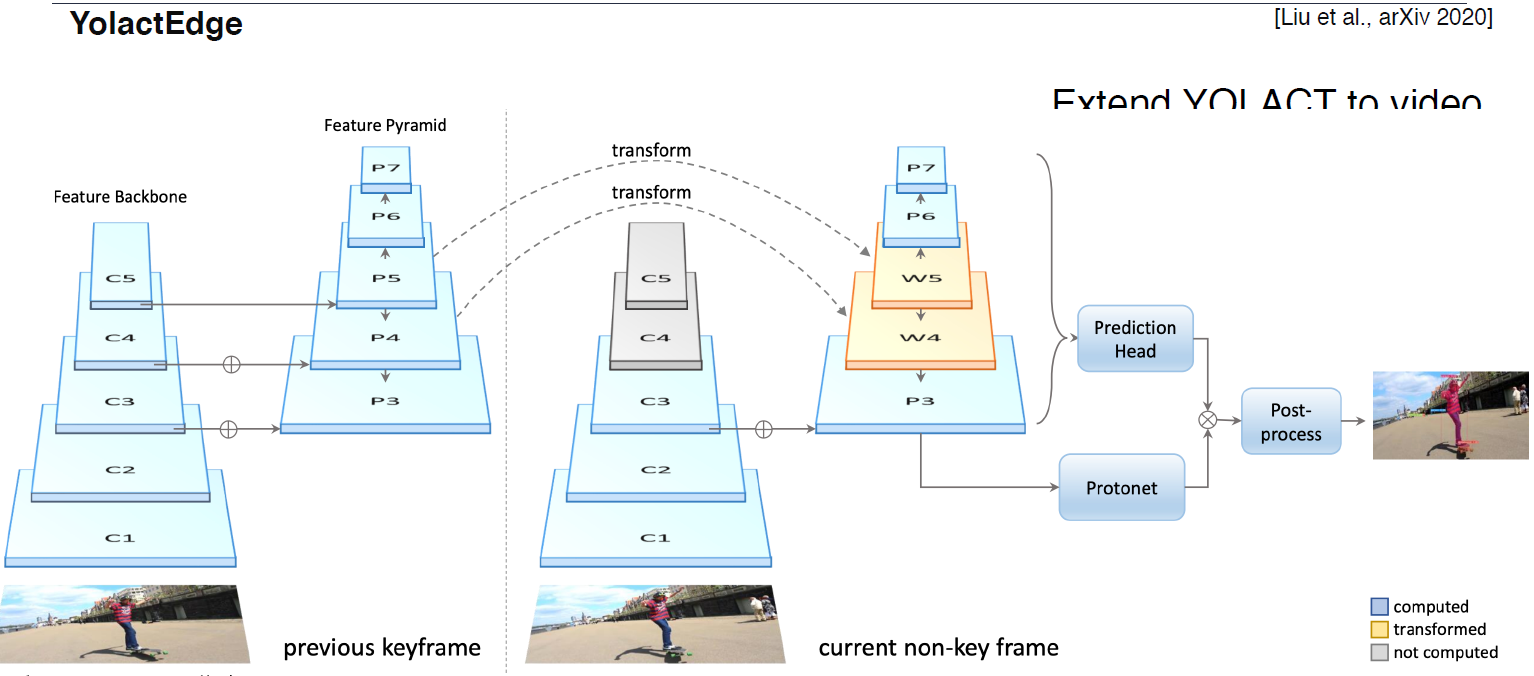
-
-
Panoptic segmentation
배경 정보 및 물체들의 instances까지 고려한다.

-
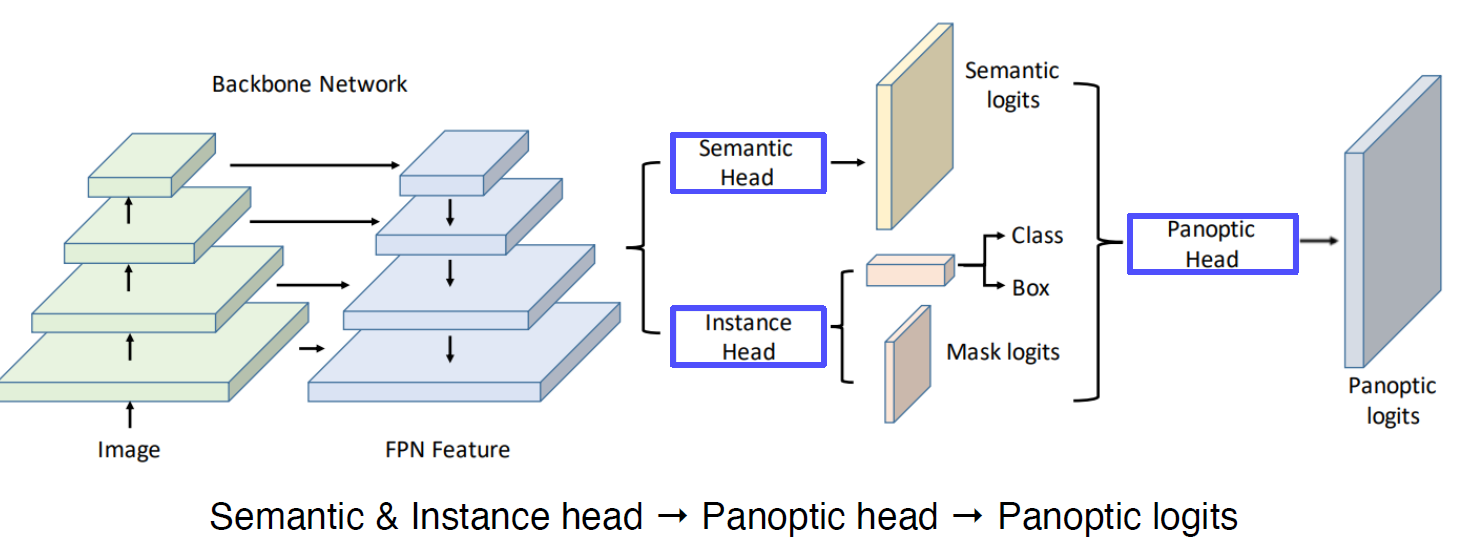
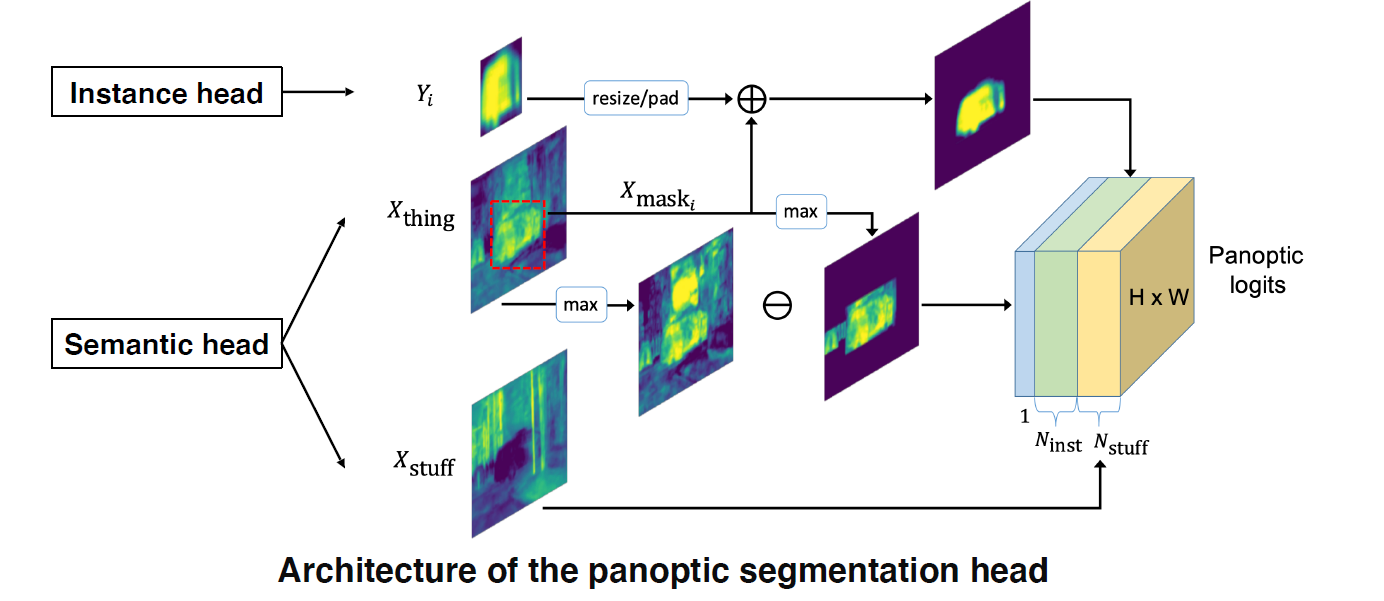
UPSNet
FPN 구조, Semantic Head, Instance Head, Panoptic logits
-
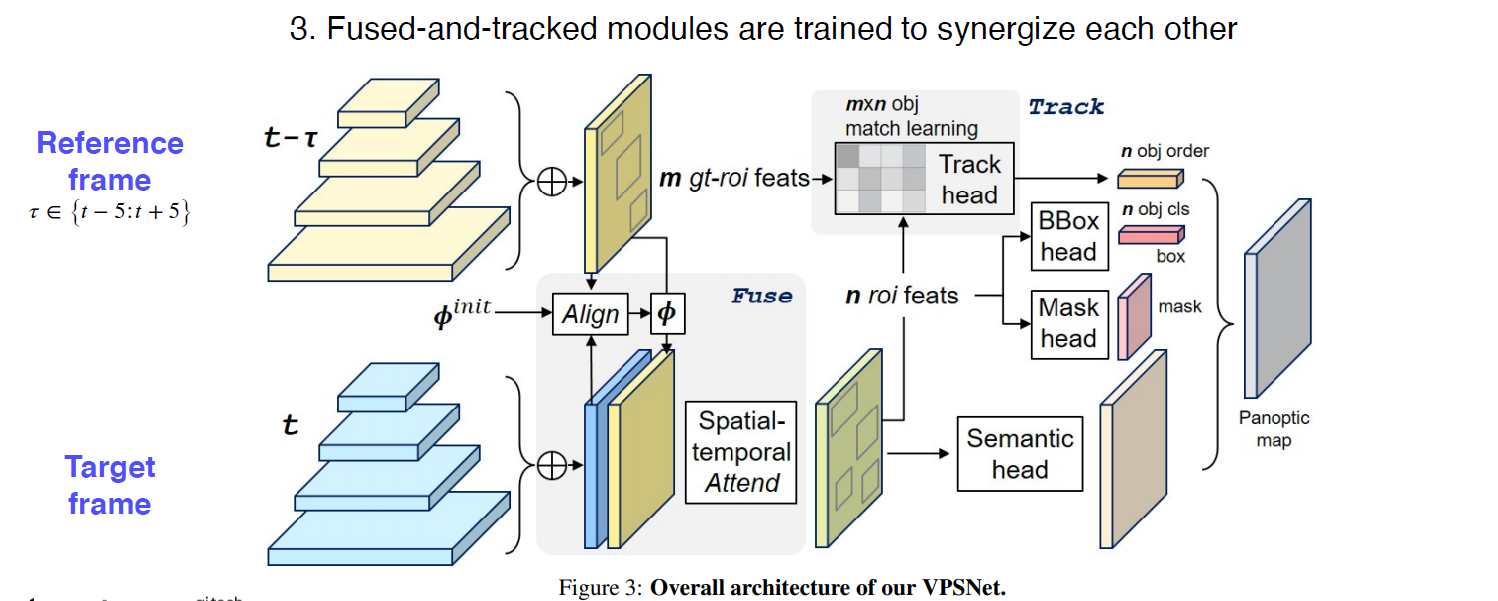
VPSNet (for video)
이전 시간 (타우) 대에 있던 feature에 대해 모션벡터에 따라서 warping을 해준다.
모션 벡터 : 한 영상에서 다음 영상에 대해 대응점에 대한 어디로 갔는 지에 대한 정보
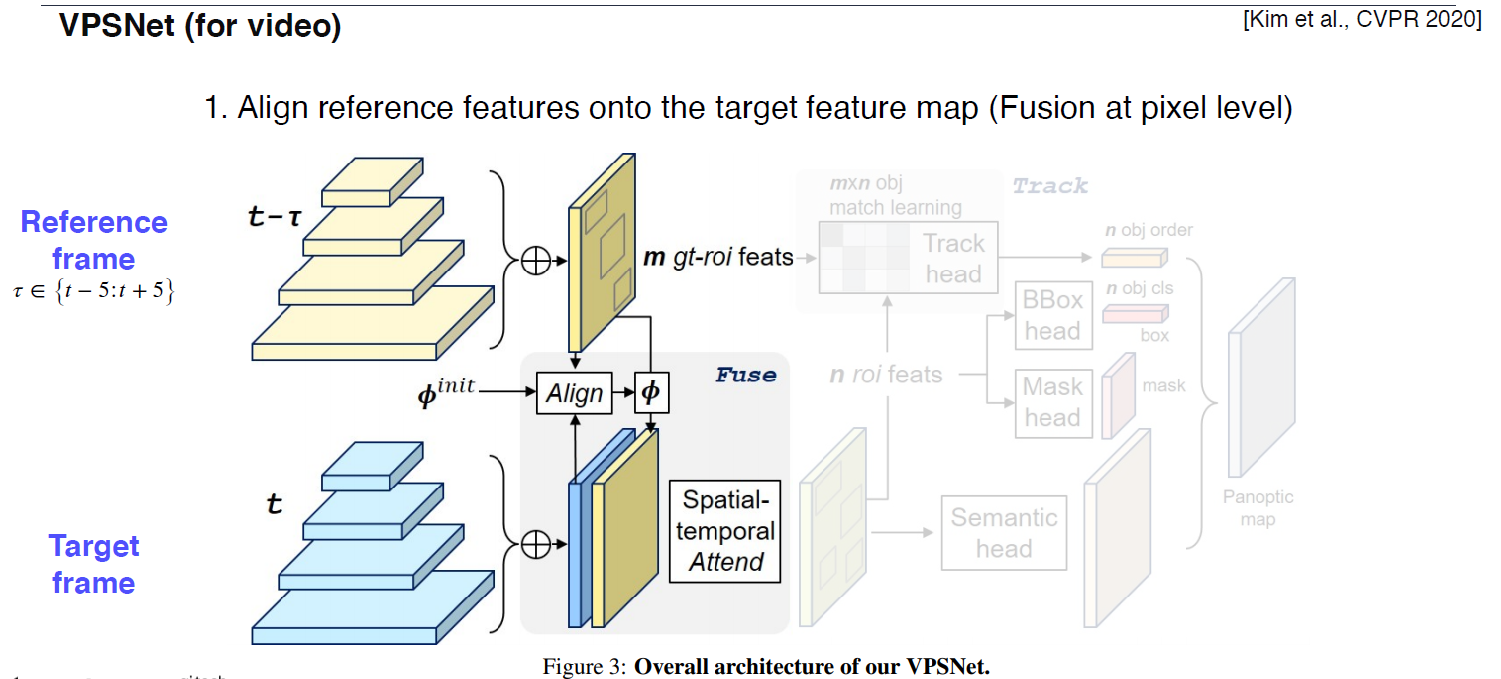
현재 프레임의 feature와 이전 프레임에서의 feature(+모션 벡터)를 합쳐서 쓴다.
기존의 roi와 현재 roi의 연관성을 tracking head를 통해서 파악한다.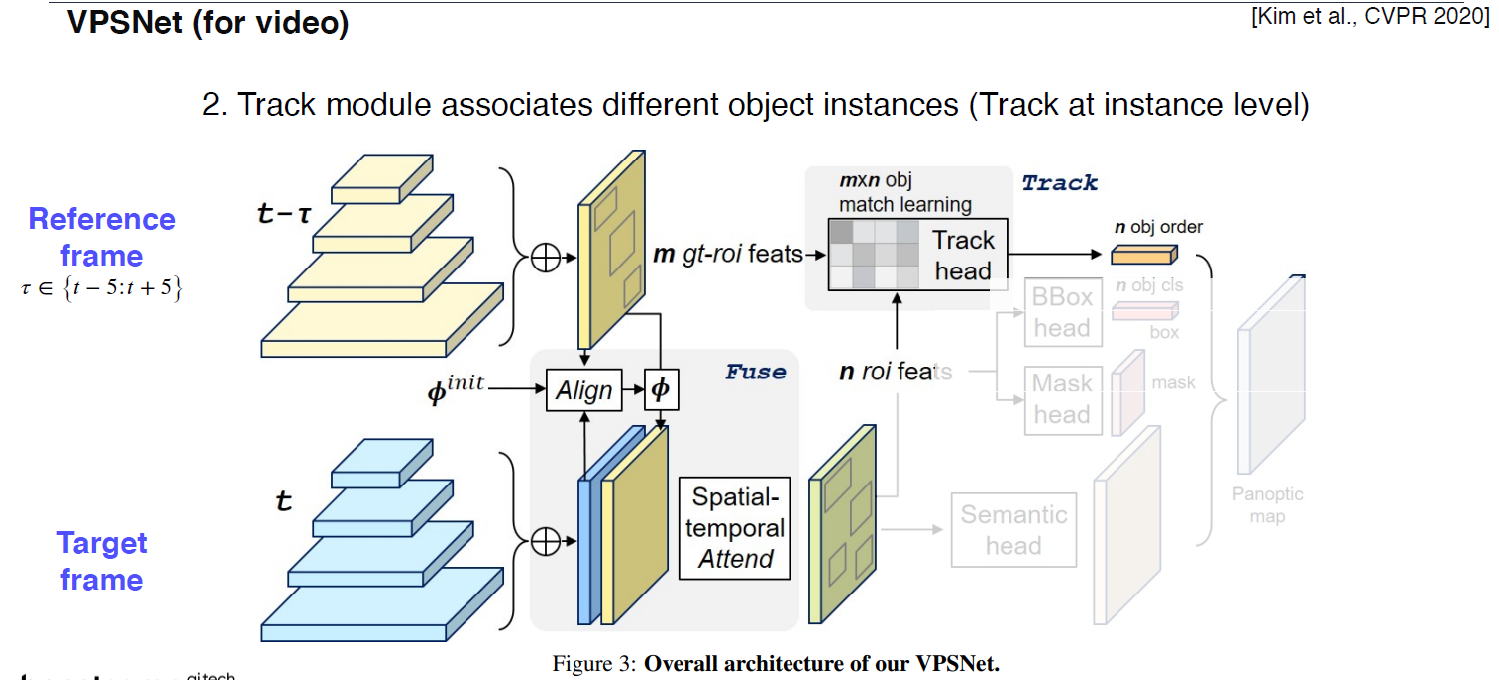
다음은 UPSNet과 동일하게 한다.
-
-
Landmark localization
얼굴, 사람 몸통의 특징 (landmark)를 추정하는 것

-
Coordinate regression vs heatmap classification
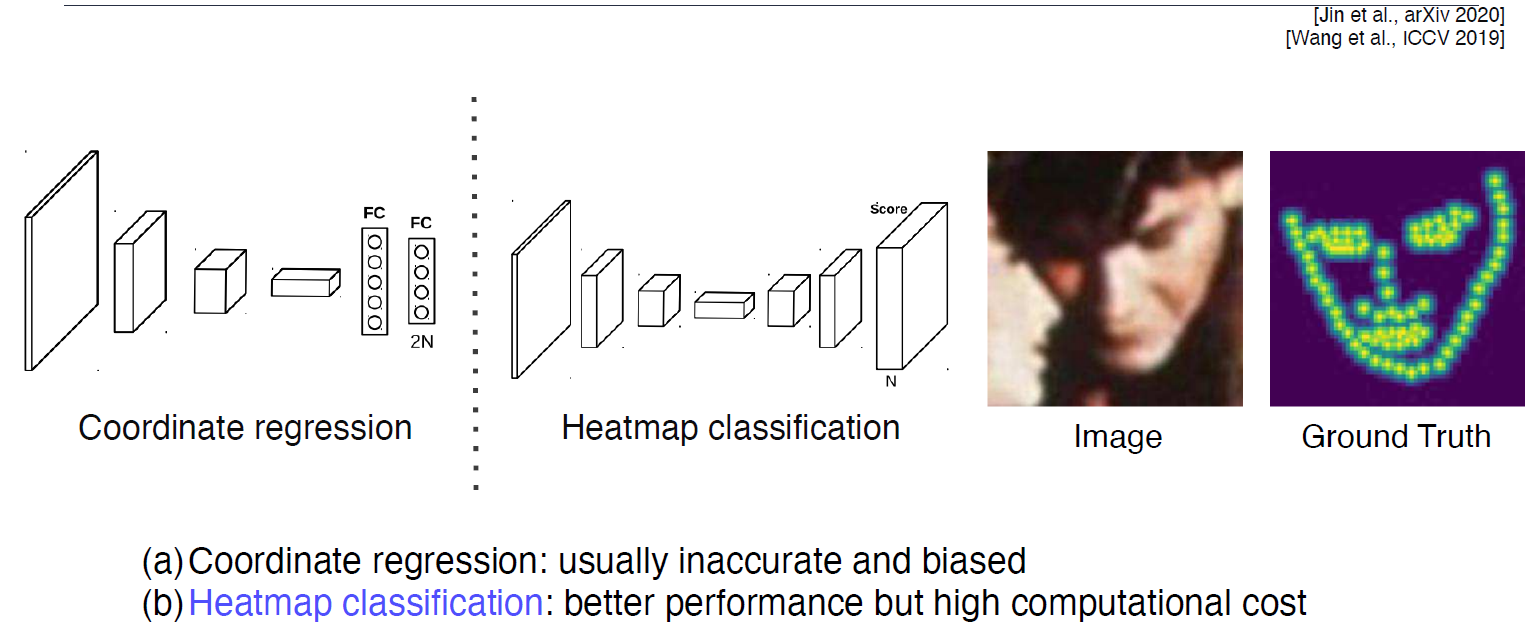
landmark가 주어졌을 때, Gaussian Heatmap으로 바꾸려면?, 그 반대는?
숙제를 이용해서 확인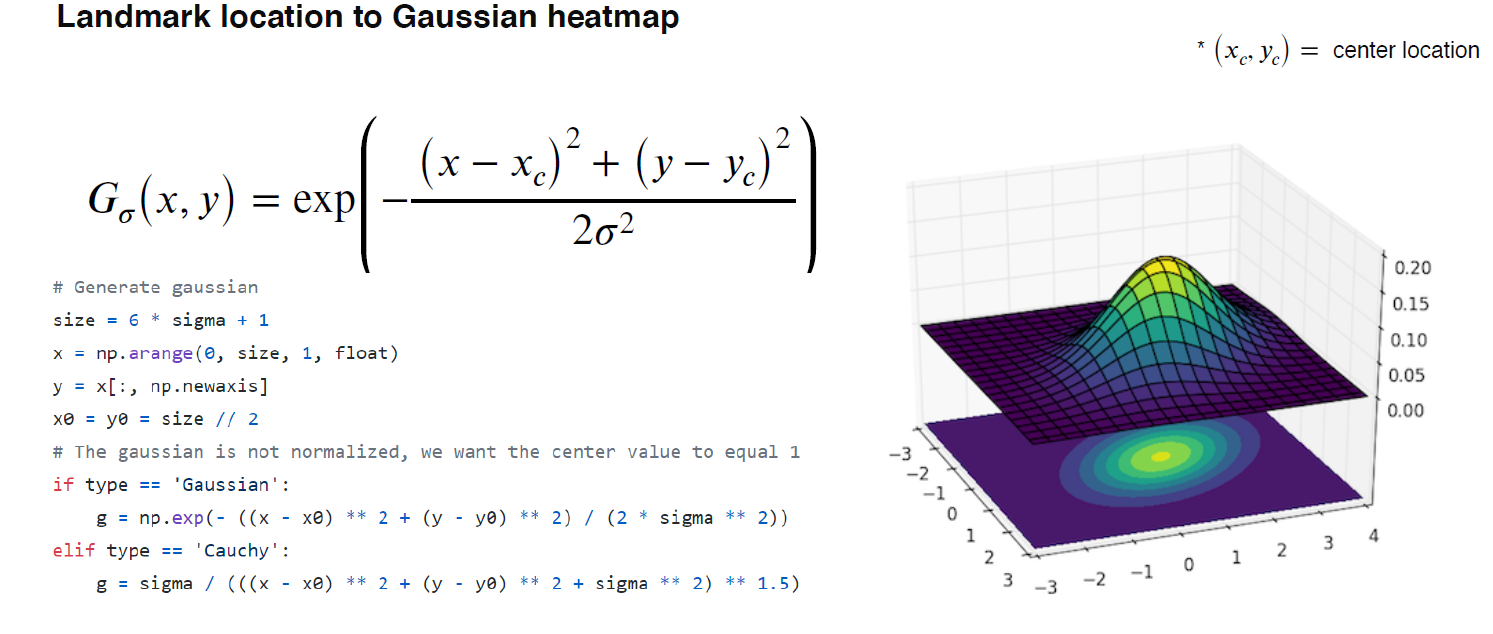
-
Hourglass network
landmark detection에 맞춘 구조, U-Net을 쌓은 구조와 같다. Stacked hourglass modules영상 전체를 작게 만들어서 receptive field를 크게 만든다.? 점점 더 구체화 시켜나가는 구조다.
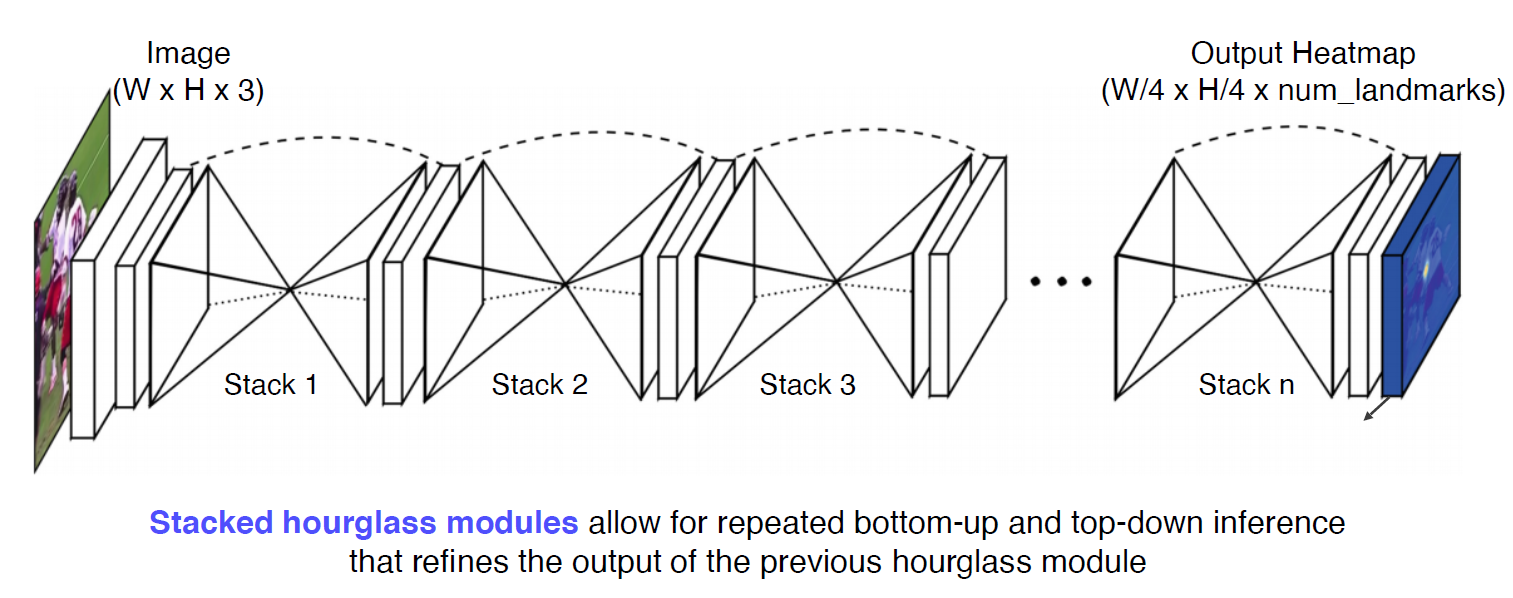
U-Net과 다른 점은?
‘+’로 되어있다. (U-net : concat) Convolution layer를 통해서 전달 (U-net : skip-connection)
거의 FPN(Feature Pyramid Network)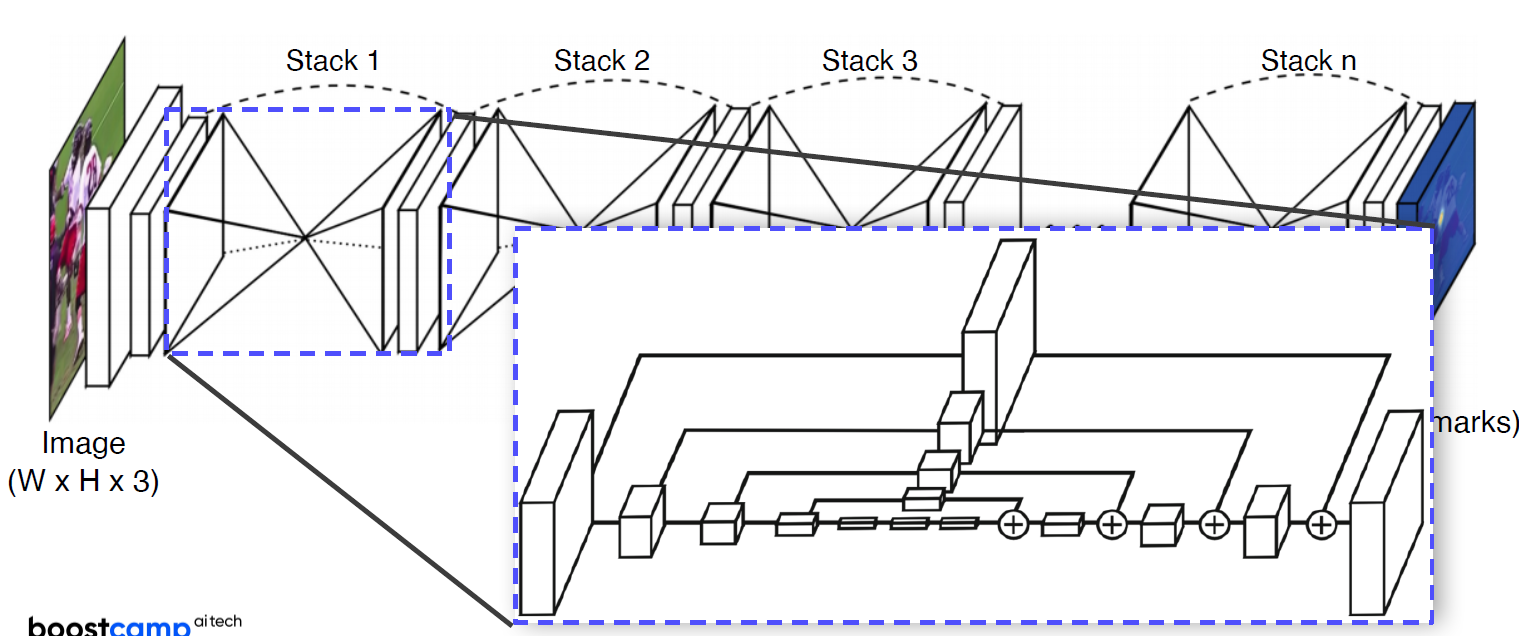
-
DensePose
-
landmark가 아닌 신체 전체를 파악 (UV-map 표현법)

-
UV-map은 3D 이미지를 2D 좌표로 평면화 시킨다. 3D 이미지에 color를 넣기 위해서 고안된 것인데, 여기서 좌표의 특성을 넣은 것
DensePose는 UV-map을 이용해서 RGB 이미지 상의 인간의 모든 픽셀을 3D 표면에 매핑하는 것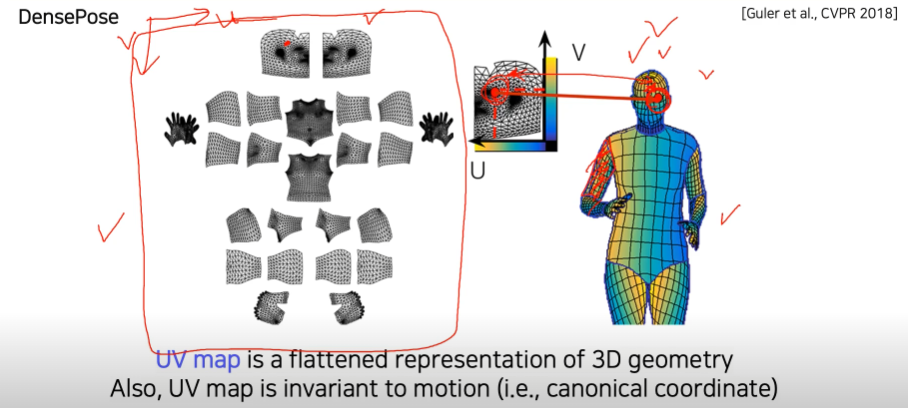
-
구조
Fast R-CNN 구조에서 Mask branch를 UV map구조로 나타낸 것을 볼 수 있다.
데이터 표현, 데이터셋을 제공하는 논문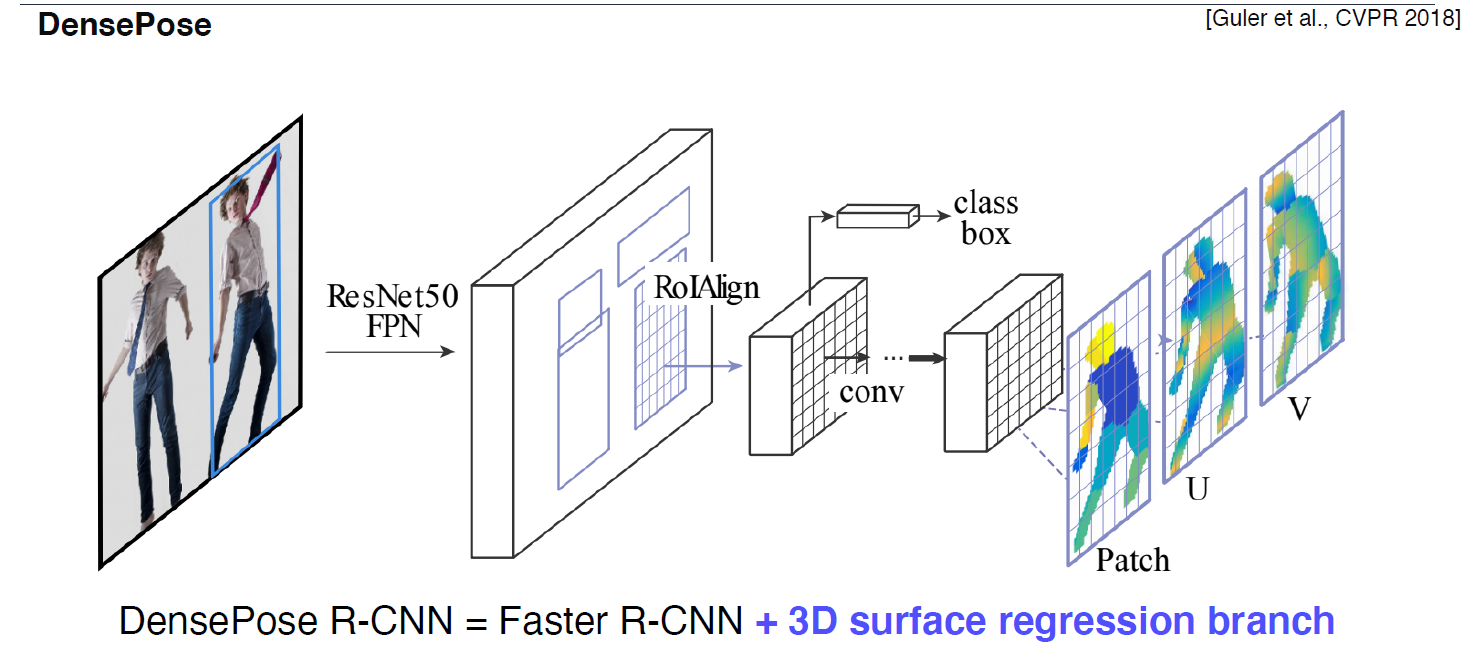
-
Retina Face
다양한 task를 한 번에 푸는 것, 얼굴에 대해 조금씩 다른 테스트에 대한 gradient를 통해서 적은 데이터로 강인한 학습 효과를 보여준다.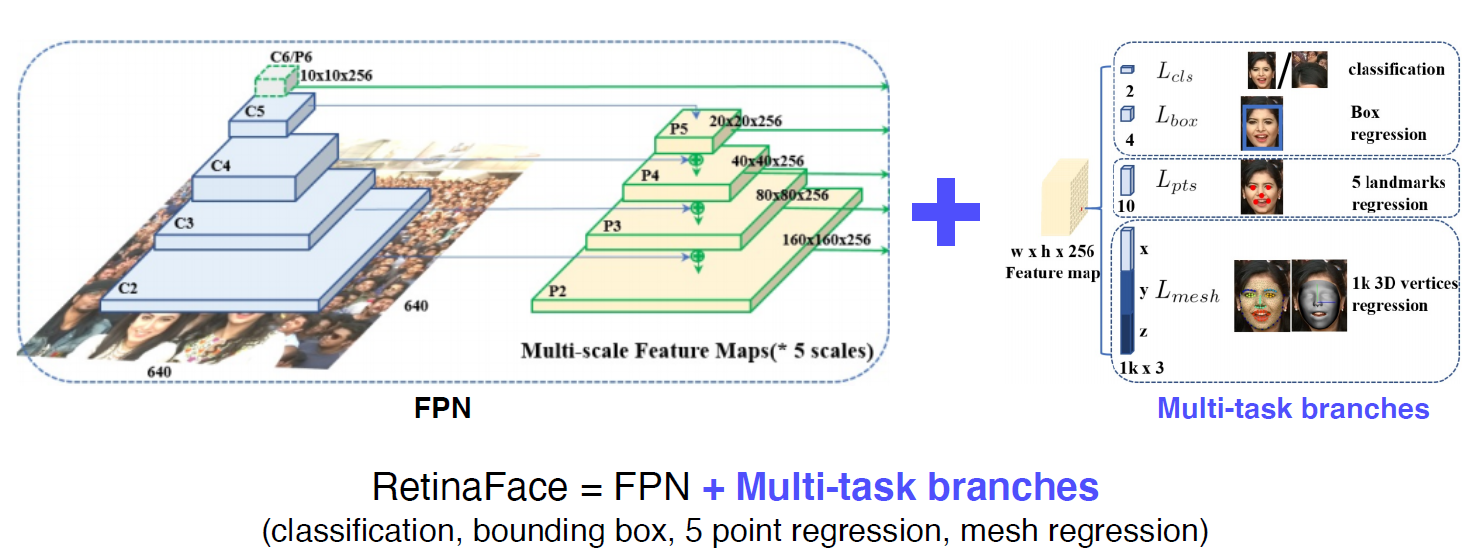
결국, Target task를 어떻게 가져가냐에 따라 응용이 될 수 있다. 큰 디자인 패턴의 하나 !
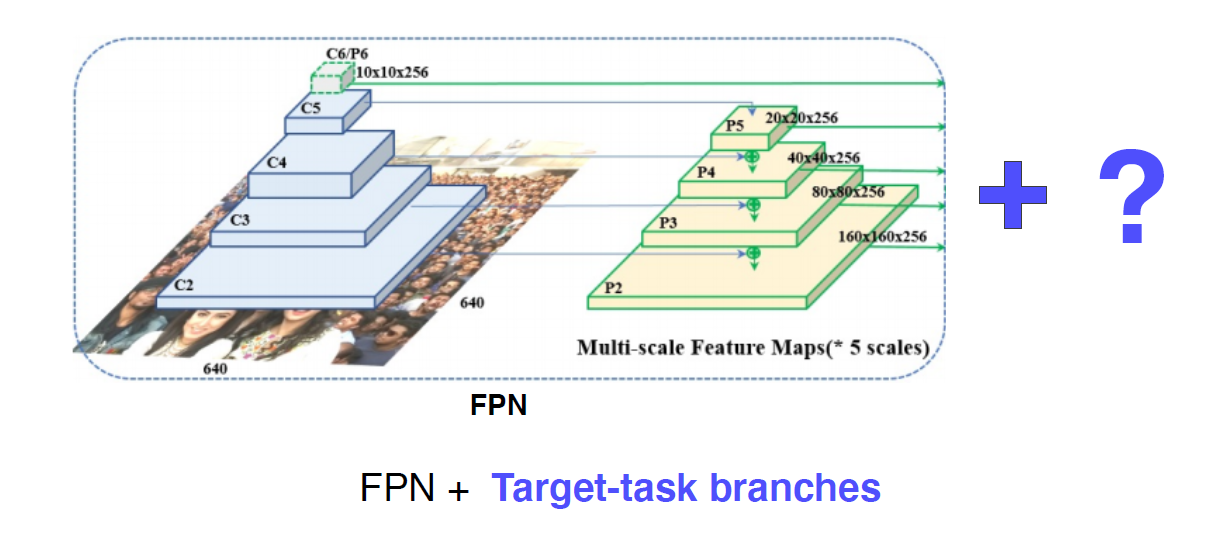
-
-
-
Detecting objects as keypoints
bounding box가 아닌 keypoint를 이용한 detection-
Cornernet
bounding box = {top-left, bottom-right} corners
heatmaps -> Embeddings을 통해 corner들의 pair를 찾아서 bounding box의 구조를 만들어준다.
single stage 구조, 성능이 살짝 떨어짐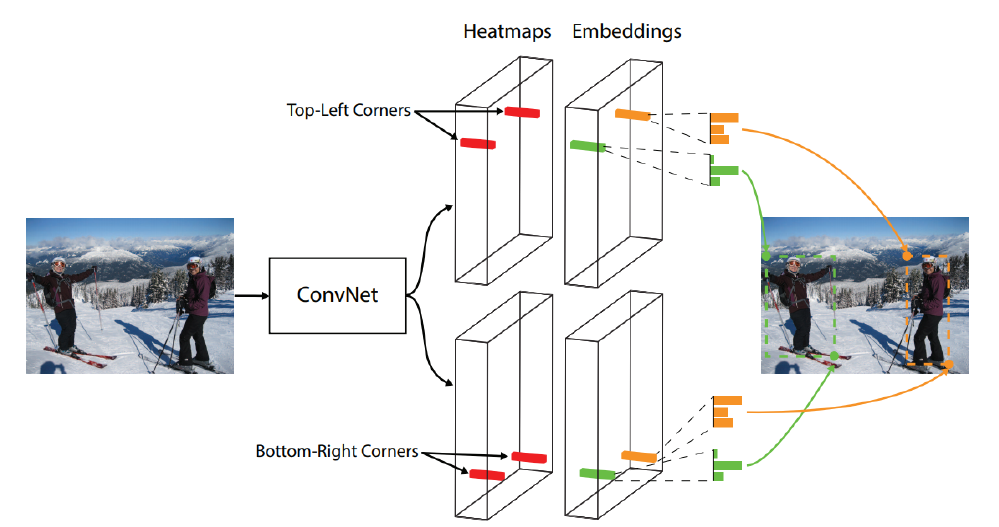
-
CenterNet
+Center Point를 추가한 것
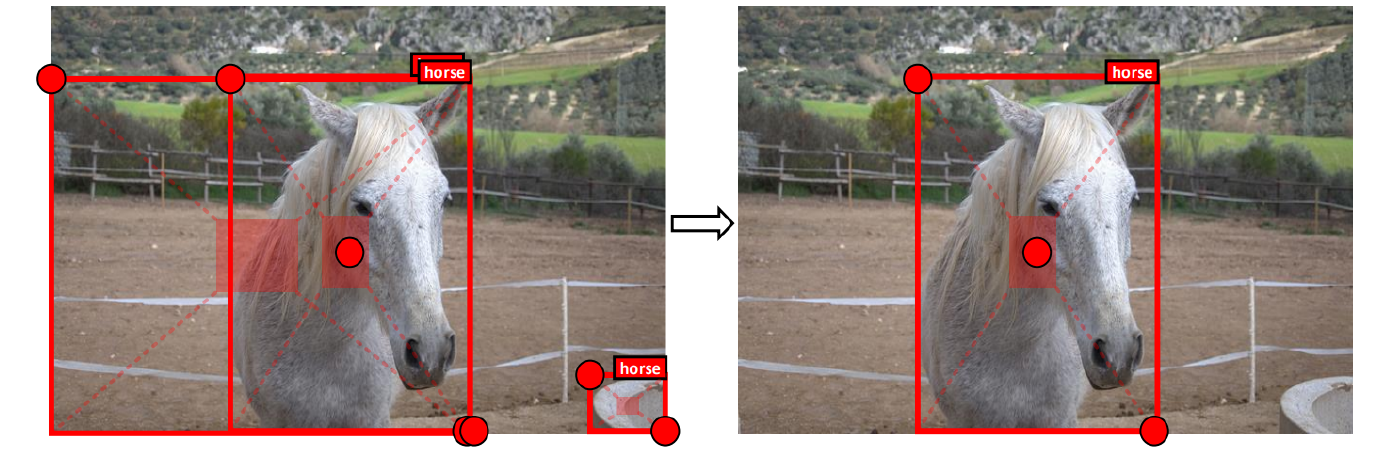
+width, height

성능 결과,
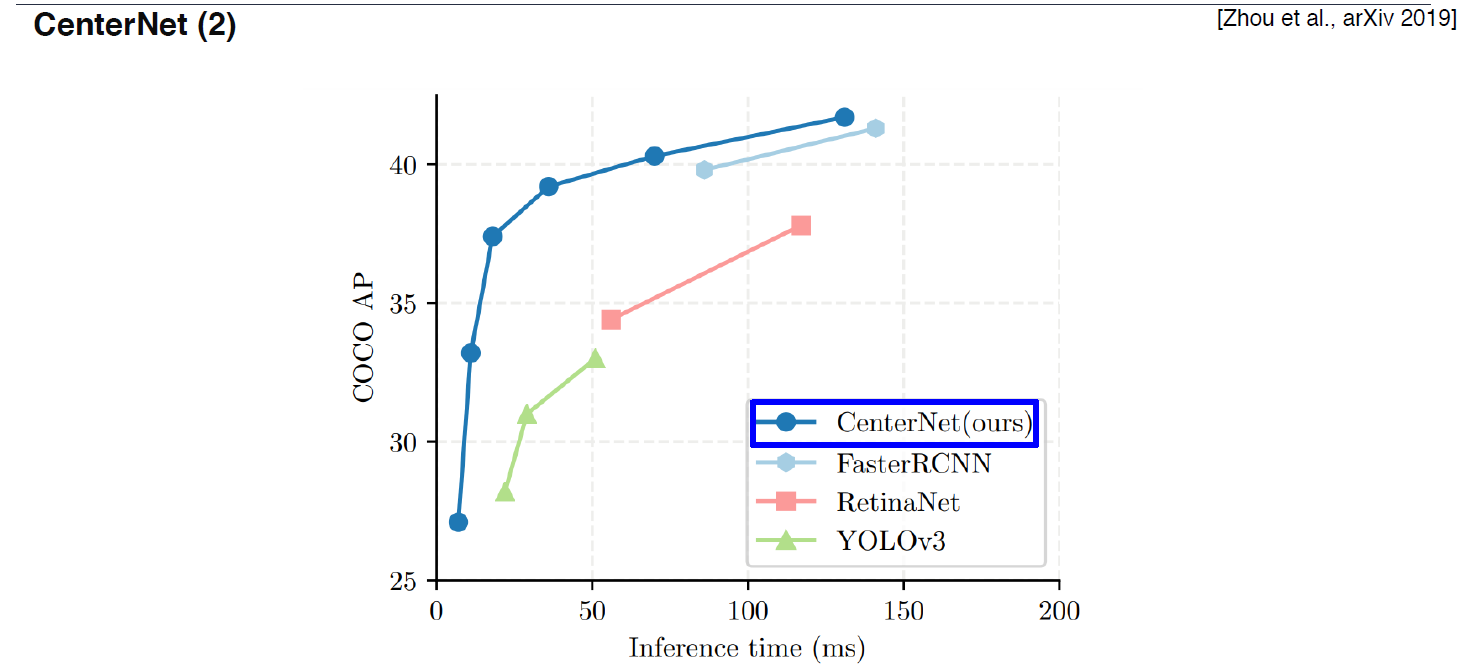
-
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
3. 피어세션 정리
4. 학습 회고
- 이전 코어타임 때 제대로 학습을 하지 못했기 때문에 연휴를 이용해서 다시 공부 해본다!