
[네이버 부스트 캠프] AI-Tech - Lv2 week2(5)
학습기록 - 35
오늘 할 일
- Multi-Modal learning - Image Captioning
- 3D Understanding
1. 강의 복습 내용
Multi-Modal learning
-
Image Captioning
Pytorch Tutorial - Image Captioning
Image Caption은 아래의 이미지처럼 attention 된 이미지를 통해 sentence를 추출하는 것

Encoder 부분
이미지를 pre-trained된 모델에 넣어 classification 이전까지 (linear, pool layer 제외) 사용class Encoder(nn.Module): """ Encoder. """ def __init__(self, encoded_image_size=14): super(Encoder, self).__init__() self.enc_image_size = encoded_image_size resnet = torchvision.models.resnet101(pretrained=True) # pretrained ImageNet ResNet-101 # Remove linear and pool layers (since we're not doing classification) modules = list(resnet.children())[:-2] self.resnet = nn.Sequential(*modules)Decoder 부분
Encoded Image를 RNN에 feeding
Attention Image와 word를 decoder에 넣어 다음 word 출력
Beam Search
가장 처음에 부분부터 word가 틀렸을 경우를 대비해서 Beam Search를 이용
decode step 마다 top3 sequence를 뽑는다. “end” 토큰이 나올 경우, 가장 높은 스코어 선택
3D Understanding
Applications - Medical applications, 3D print, AR/VR
If you are interested in more details about 3D, check this Bible. Multiple View Geometry in Computer Vision
3D data representation

- 3D dataset
-
ShapeNet
Large scale synthetic objects (51,300 3D models with 55 categories)
-
PartNet
Fine-grained dataset, useful for segmentation (573,585 part instances in 26,671 3D models)
-
SceneNet
5 million RGB-Depth synthetic indoor images
-
ScanNet
RGB-Depth dataset with 2.5 million views obtained from more than 1500 scans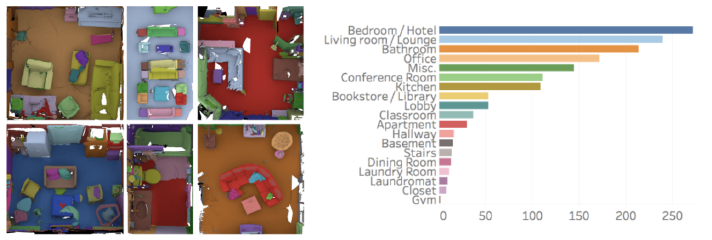
-
Outdoor 3D Scene datasets

-
- 3D recognition
-
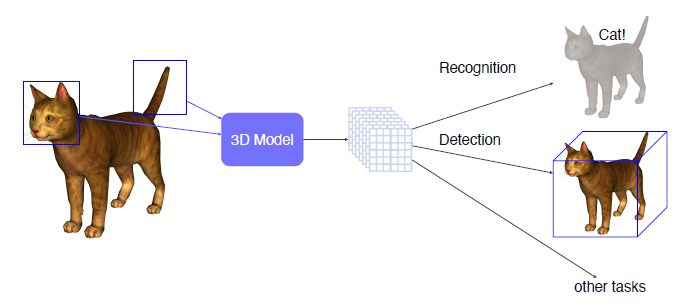
Various tasks for 3D data
-
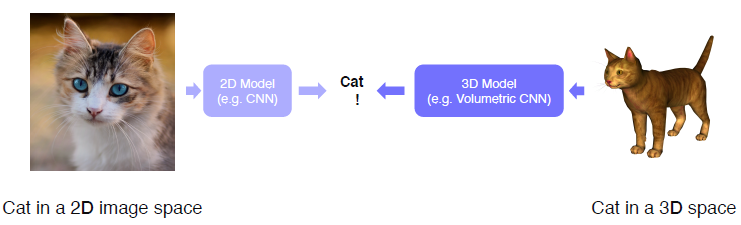
3D object recognition
2D Image에서 class 분류와 같이 3D Image에서도 같은 recognition을 진행
-
3D object detection

-
3D semantic Segmentation
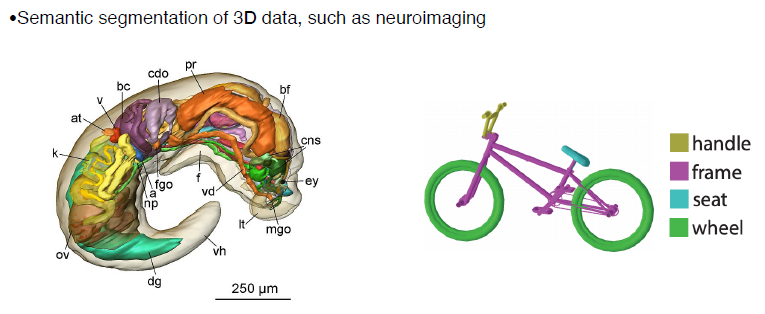
-
Conditional 3D generation
-
Mesh R-CNN (Mask R-CNN의 head를 Mesh 형태로 Modification)

-
“3D branch” is added to Mask R-CNN
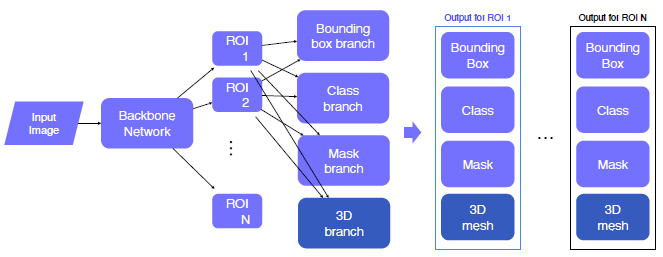
-
More Complex 3D reconstruction models
- Decomposing 3D object reconstruction into multiple sub-problems
-
Sub-problems: physically meaningful disentanglement (Surface normal, depth, silhouette, …)
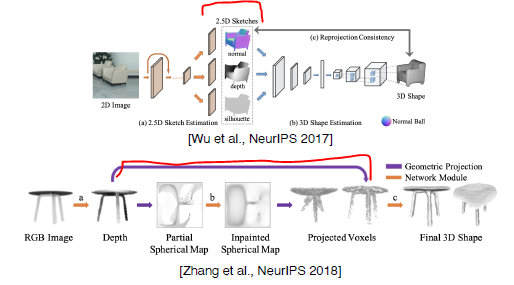
-
-
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
register_forward_hook (name, module, input, output)
3. 피어세션 정리
4. 학습 회고
- 생각보다 양이 많고 어려웠던 게 많았던 과정이다. 그런데 시각화가 아닌 sound 등을 함께 이용할 수 있는 multi-modal learning에 대해 흥미가 많이 생겼던 강의였다.