
[네이버 부스트 캠프] AI-Tech - Lv2 week2(4)
학습기록 - 34
오늘 할 일
- Multi-modal Learning
1. 강의 복습 내용
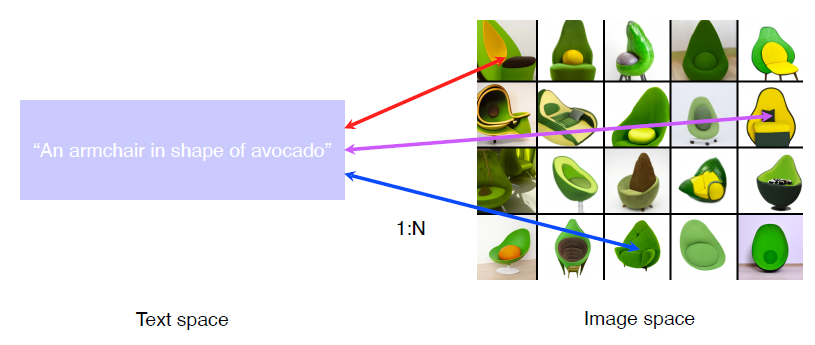
Multi-modal Learning
한 타입에 데이터가 아닌 다른 특성의 데이터도 함께 사용하는 것 (소리, 맛, 느낌..)
multi-modal learning
여러가지 감각 데이터를 ‘함께’ 사용하는 것. 사람은 일반적으로 multi-modal 형태로 사물을 인지한다. (<-> unimodal (한가지만 사용하는 것))
-
문제점
-
다른 데이터 구조

-
feature의 Unbalance matching
-
Specific data에 더 biased한 형태로 trainig
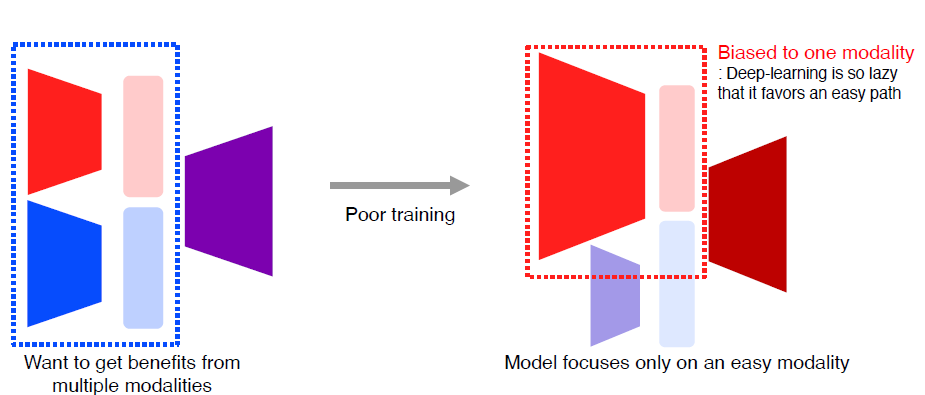
-
문제점이 있음에도 다양한 방법을 통해 유익한 정보를 얻을 수 있다.
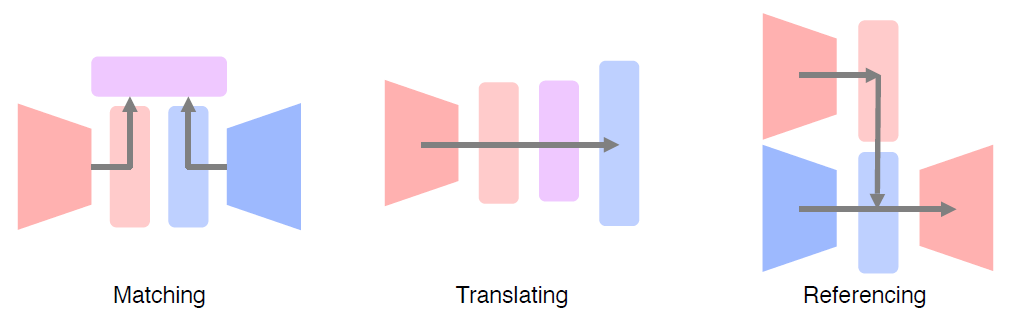
-
-
Text embedding
word embedding을 통해서 비슷한 의미의 ‘단어’들에 대해 일반화가 가능하다.
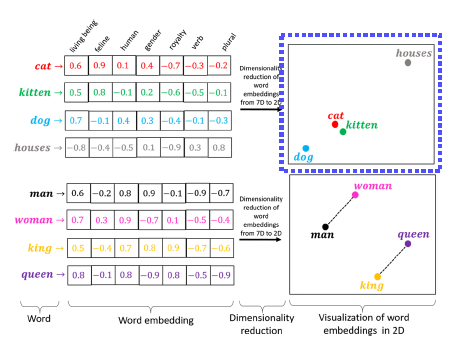
-
Skip-gram model
input layer -> hidden layer
input layer에 있는 vector는 어떤 단어들의 벡터이고 단어가 W에 의해 hidden layer로 된다. 어떤 단어에 대한 특징을 추출한다.
hidden layer -> output layer
단어 전 후의 어떤 단어가 오느냐에 따라 output layer의 feature 결정해서 학습한다.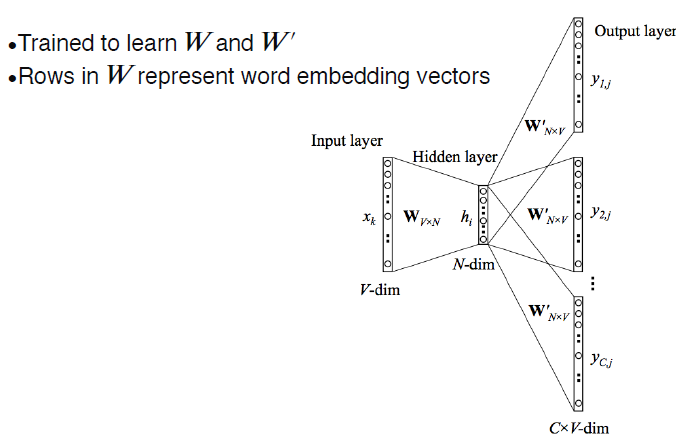
Skip-gram model은 neighboring N words에 대해서 학습해서 주변 단어들과의 ‘관계’에 대해 학습한다.
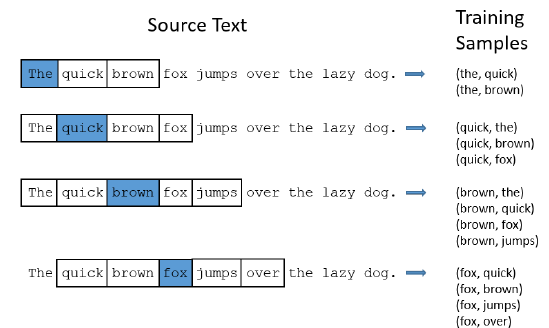
-
-
Joint embedding (Matching)
Image tagging
Image -> tag or tag -> Image
Joint embedding에서는 각 Data의 feature를 추출한 후, 같은 dimension으로 만든 output의 거리에 따른 상관성을 나타낸다.
이렇게 matching의 정도에 따라 밀고 (push) 당기는 (pull) 학습을 metric learning 이라고 한다.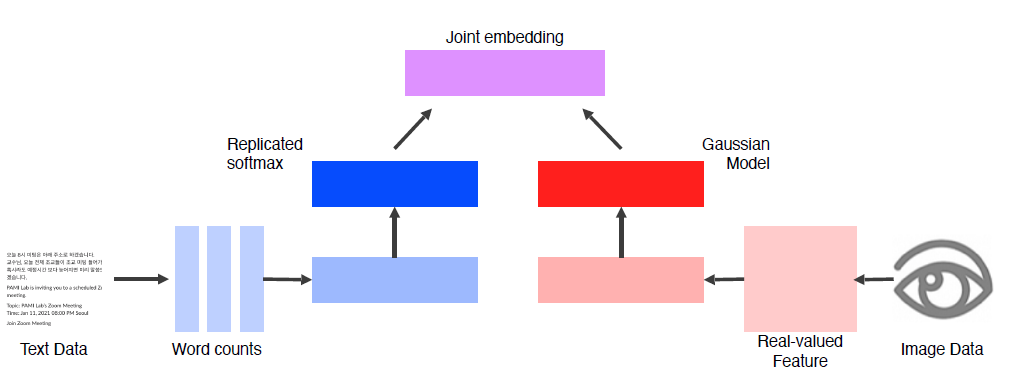
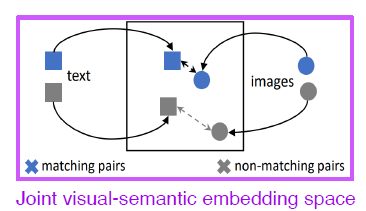
-
Image tagging - interesting property dog Image - ‘dog’ + ‘cat’ -> cat Image + dog Image’s background

-
Image tagging - food Image vs recipe text recipe과 Image의 joint를 통해 cosine simmilarity loss 와 semantic regularization loss를 만든다.
cosine simmilarity loss는 Image와 recipe의 상관성,
semantic regularization loss는 cosine simmilarity loss로 해결이 안되는 부분에 대해 가이드를 준다. (high-level semantic)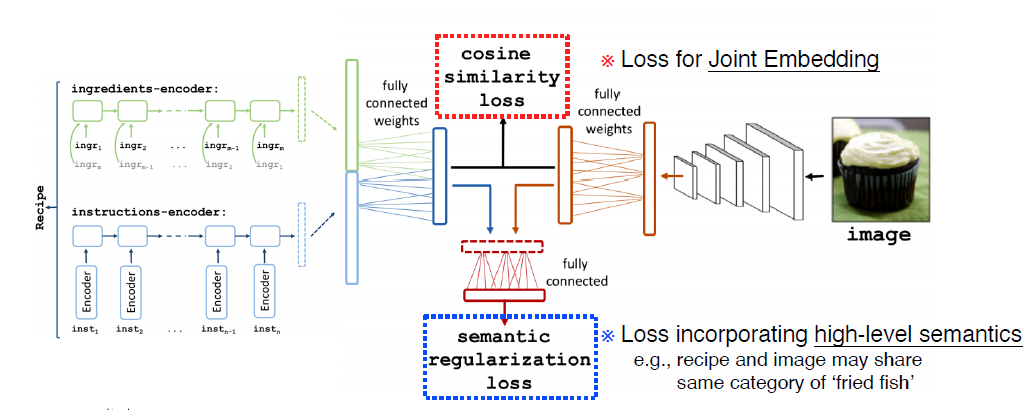
-
-
Cross modal translation (Translating)
-
Image captioning Image가 주어졌을 때, 이미지에 해당하는 문장 출력
-
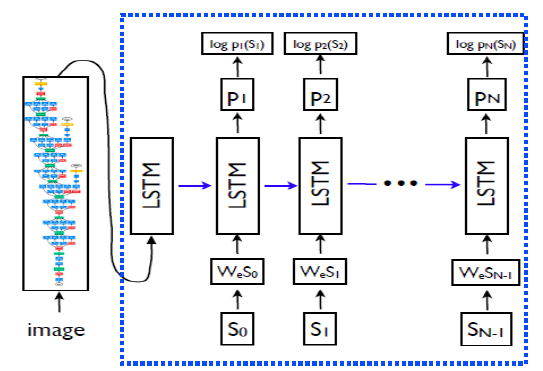
show and tell
Encoder : CNN model을 통해서 feature 추출
Decoder : Encoder에서 추출한 feature를 condition으로 하는 LSTM module내에 RNN을 통해 단어 추출 -> sentence
-
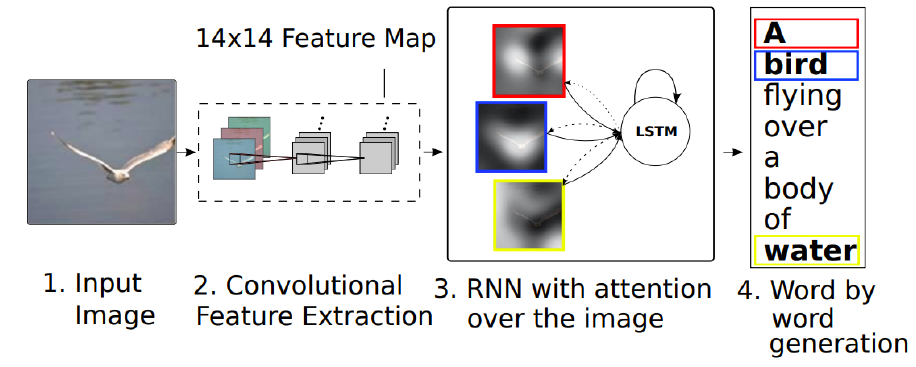
show, attend and tell Image 내에 특정 영역을 확인하고 알맞는 sentence 출력
Image에서 CNN을 통해서 convolutional feature 추출, RNN에서 attend 된 부분에 word generation
-
show, attend and tell (soft attention)
attention은 인간이 사물을 볼 때 보는 방법과 일치하다. 인간이 보는 방법과 비슷하게 하기 위해 Image의 특징적인 부분을 따서 주요 부분만 확인할 수 있도록 한다.Image를 CNN에 넣어 feature vector를 grid로 나타내고 각 feature에 대해서 RNN을 통과시켜서 어디를 reference를 줘야하는 지 heat map으로 나타내준다.
feature vector와 heat map에서 feature 들의 probablity를 weighted sum 해줘서 z로 나타낸다.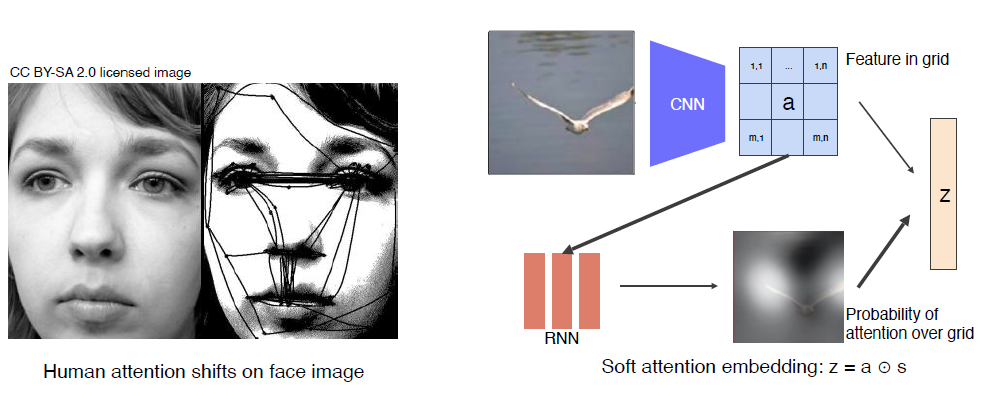
위의 내용을 더 자세한 과정으로 나타내면,
Image를 CNN으로 통과해서 feature vector를 나타내준다. 이것을 LSTM의 condition으로 넣어준다. (h0) LSTM에서 어디 부분은 attention 할 지 spatial attention을 weight로 출력 해준다. (s1)
이 weight를 이용해서 features 와 inner product를 해줍니다. (s1, features -> z1)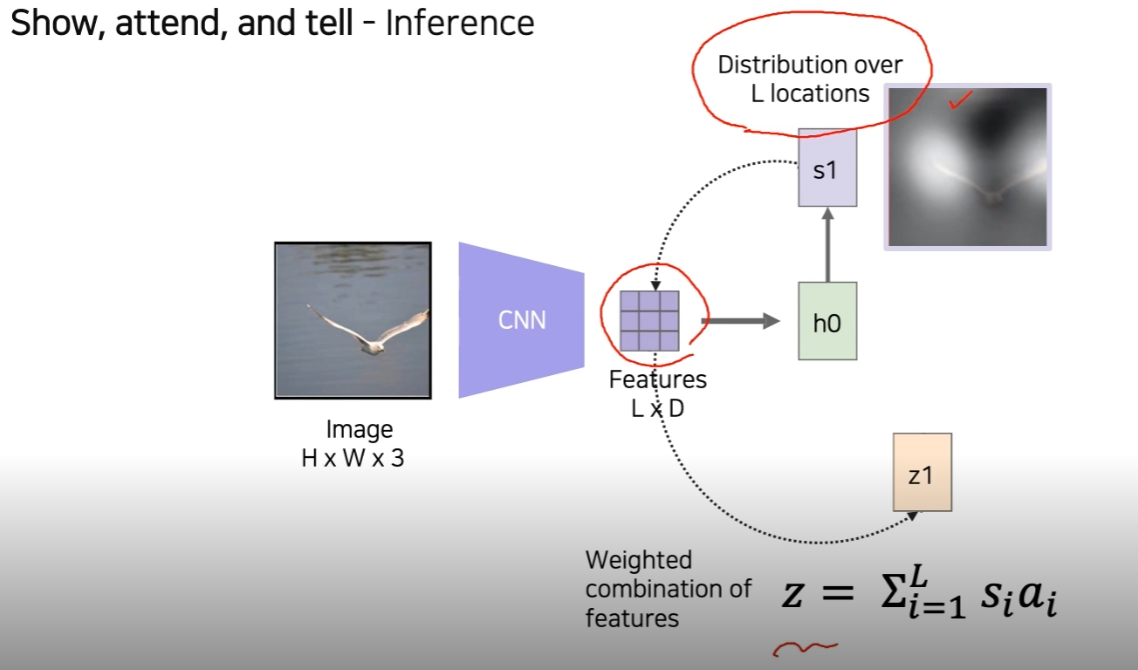
여기서 z1을 다음 RNN step (LSTM) 에 condition으로 넣어주게 되고, start word token을 넣어준다. (h1) h1에서 condition을 보고 어떤 단어로 시작해야할 지 고민을 하고 word를 추출 한다. (d1) 동시에, 어디를 reference 할 것인지 Image를 추출해준다.(s2)
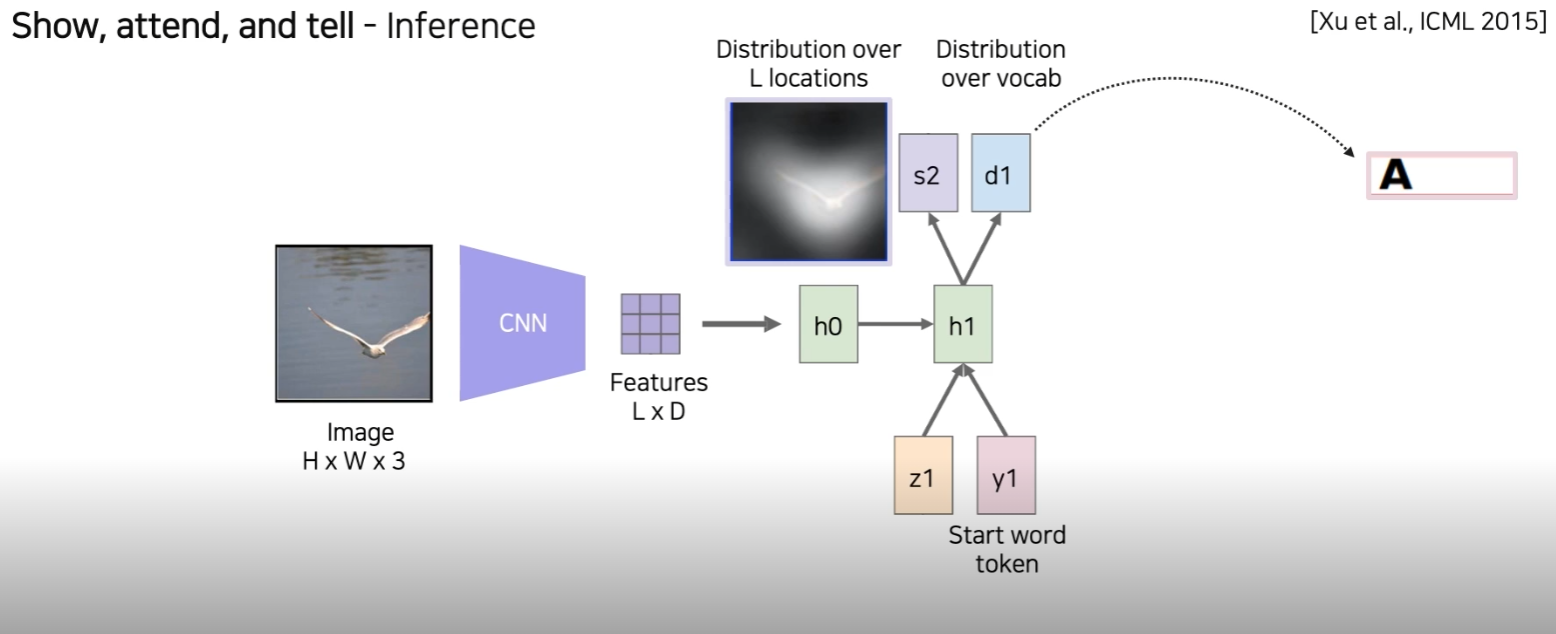
이전과 같은 방식으로 feature와 weight를 inner product해서 z2를 만들어주고, LSTM에 넣어준다.
이 때 token은 이전에 출력했던 단어를 넣어준다.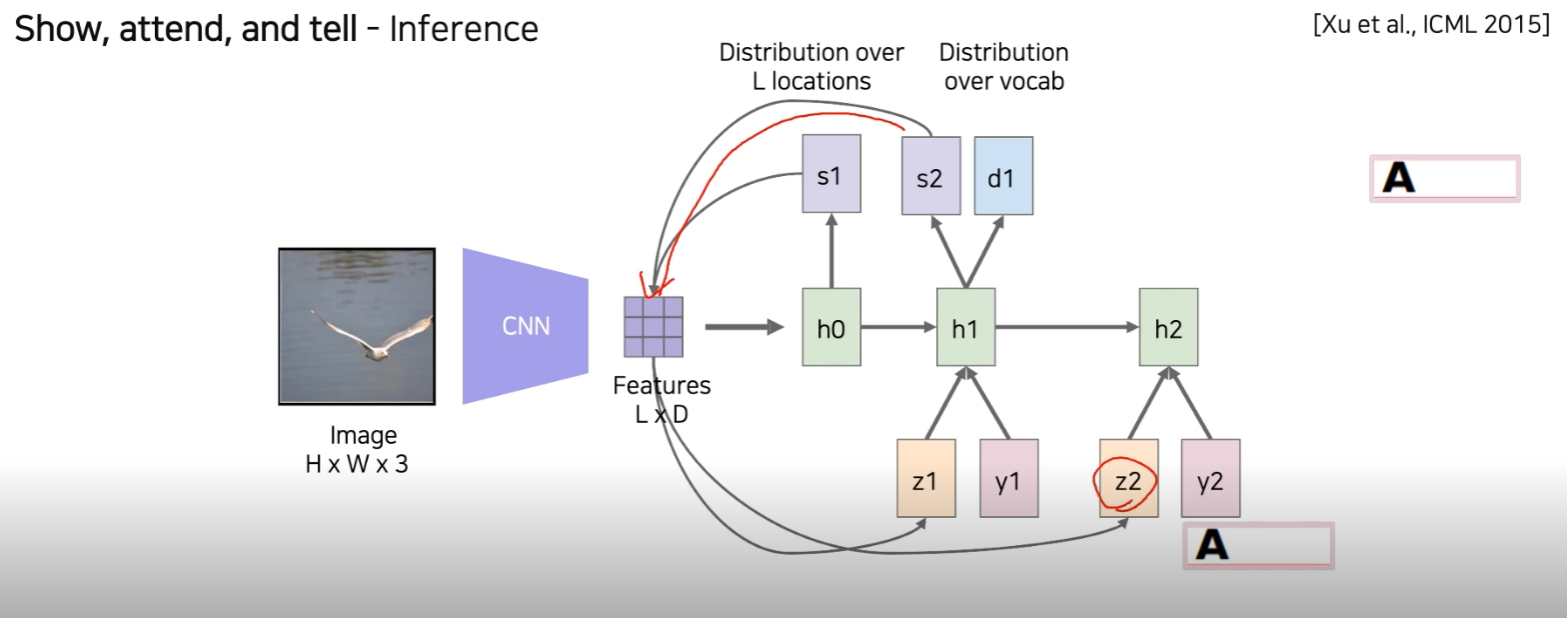
이전에 했던 방식을 반복하면 sentence를 만들어 낼 수 있다.
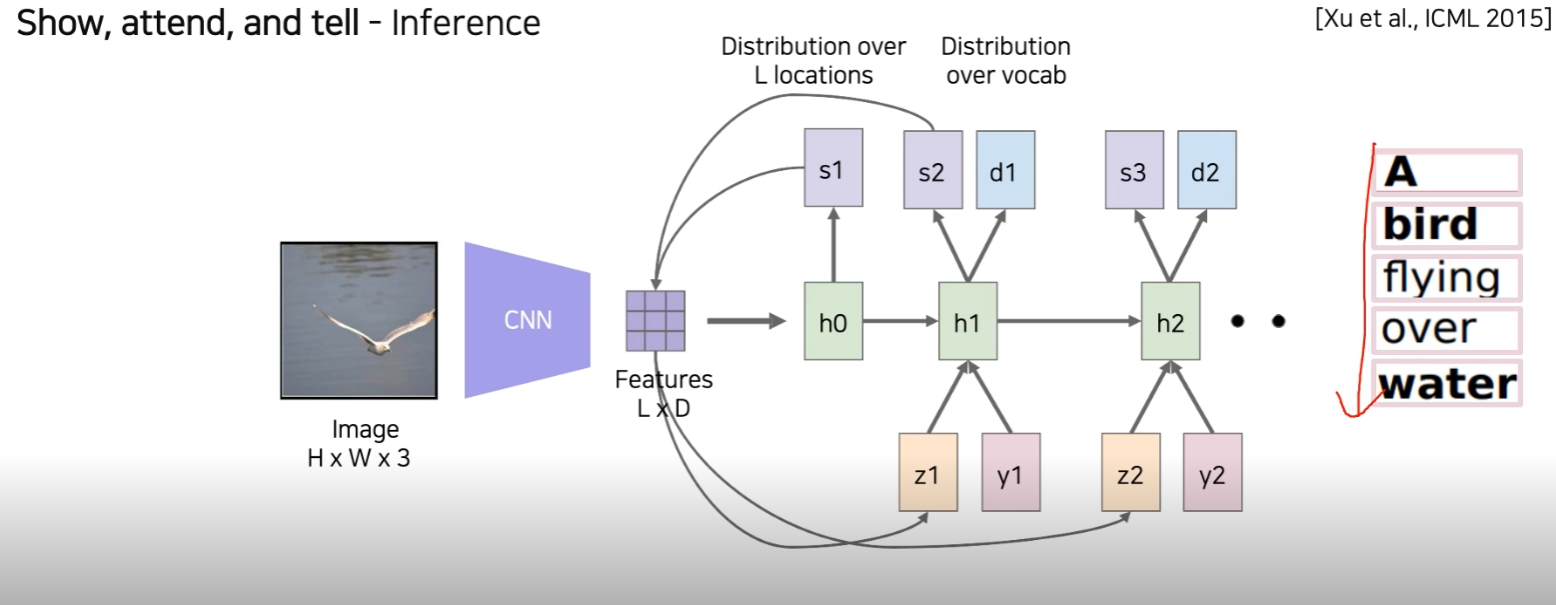
-
-
Text-to-Image 이번엔 아까했던 것과 반대로 text를 인식하고 Image를 output으로 하는 방법이다. Generative model (cGAN) 을 이용해서 학습을 진행한다.

먼저 sentence (condition) 를 pre-trained network에 넣어 fixed-dimensional vector를 만든다. 여기에 Gaussian Random Code vector를 붙여서 (z~N(0,1)) Network에 넣어 decoder에서 Image를 출력해준다.
이 때, Gaussian Random code는 결과가 더 diverse할 수 있도록 만들어주는 역할을 한다.여기서 출력된 Image를 low-dimensional로 만들어서 이전 sentence (condition) 을 넣어 True or False를 결정한다.
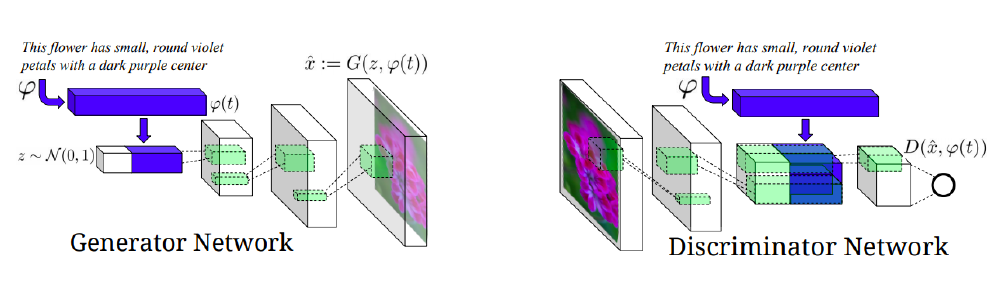
이전에 했던 cGAN의 architectur와 매우 비슷한 것을 볼 수 있다.
-
-
Cross modal reasoning (Referencing) 서로 참조를 하는 모델
-
Visual question answering - Multiple streams Image stream, Question stream에 대해서 각각 fixed dimension 출력
point-wise multiplication를 이용 (Joint-Embedding)
End-to-end training
-
-
Multi-modal tasks (2) - Visual data & Audio
-
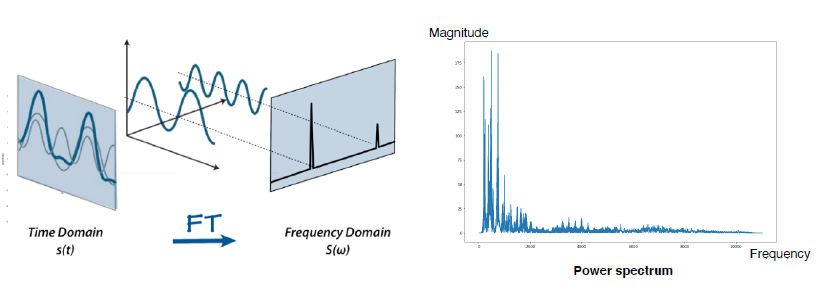
Sound representation - Fourier Transform
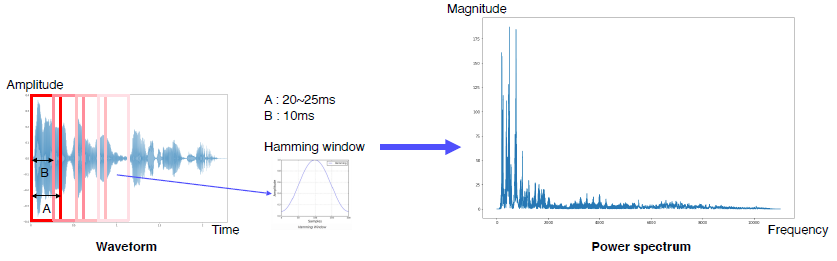
FT decomposes an input signal into constituent frequencies
Spectrogram: A stack of spectrums along the time axis
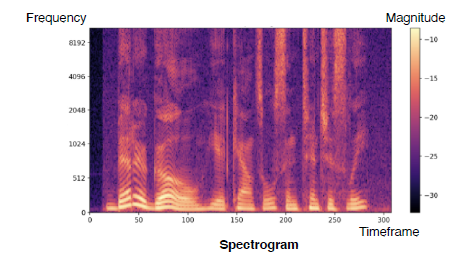
- Joint embedding
오디오에 따른 Image-
Sound Net
Train by teacher-student manner
Visual to Sound
Raw Waveform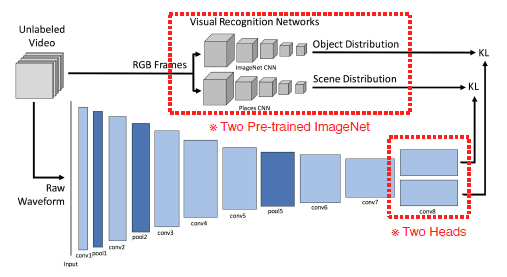
Target task가 있을 경우, pool5 feature 추출하고 classifier를 올려서 뽑아낸다.
conv8 이후 출력 값을 Object, Scene에 따라갈 것이기 때문에 pool5가 generalizable semantic info가 있을 것이라 예상

-
-
Cross modal translation (translate)
-
Speech2Face (oh et al, CVPR 2019) sound를 이용해서 얼굴 추출 teacher-student 방식으로 훈련, Test시에는 Speech2Face Model
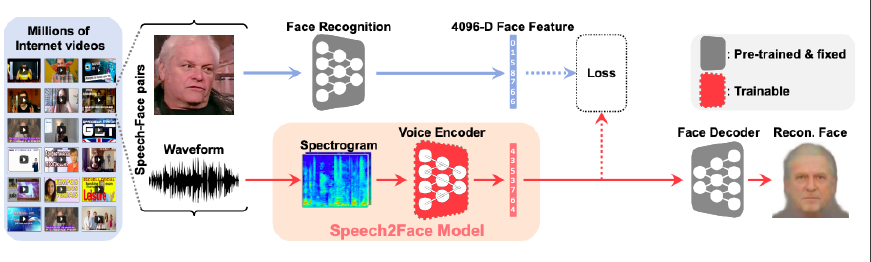
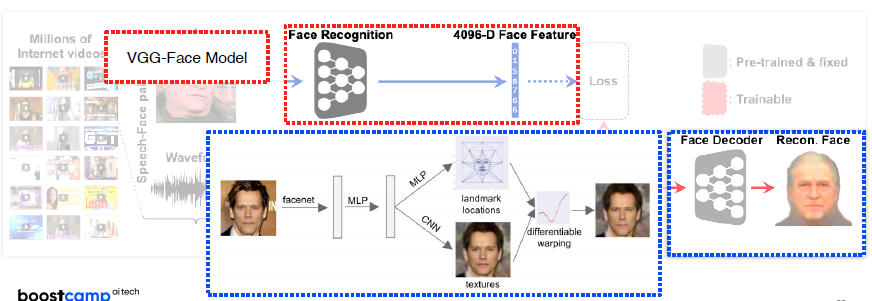
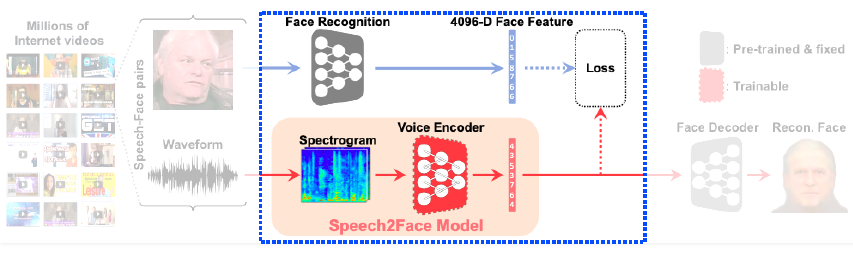
-
Image-to-speech synthesis - Module networks
Speech to Unit model을 이용해서 Unit 생성, Image를 이용해서 Speech 생성 시 이용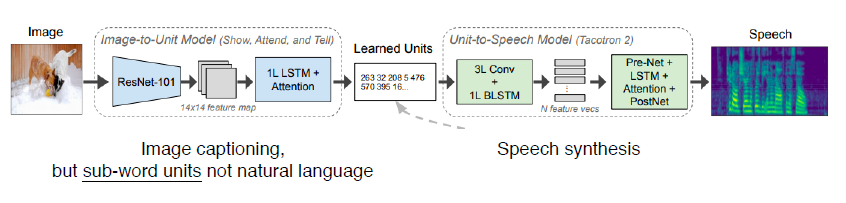
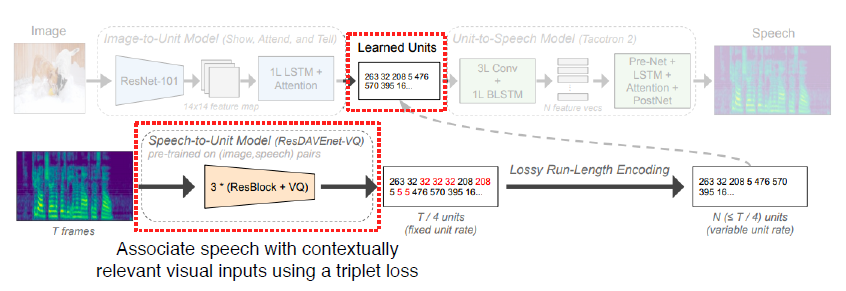
-
-
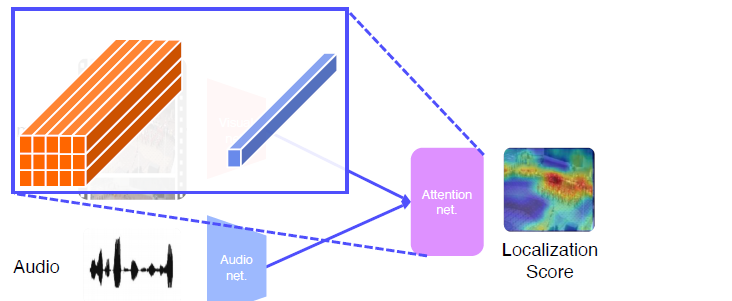
Sound source localization (Referencing)
Sound + localization
소리와 매칭 되는 Attention한 Image를 찾는다.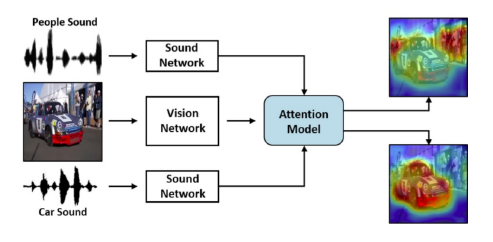
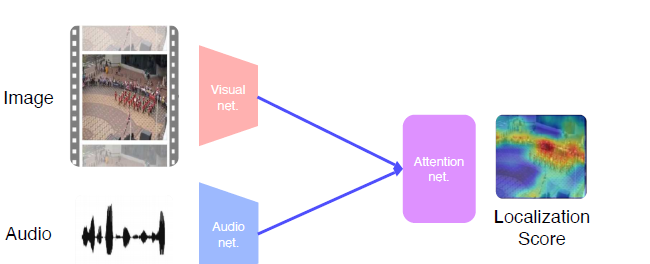
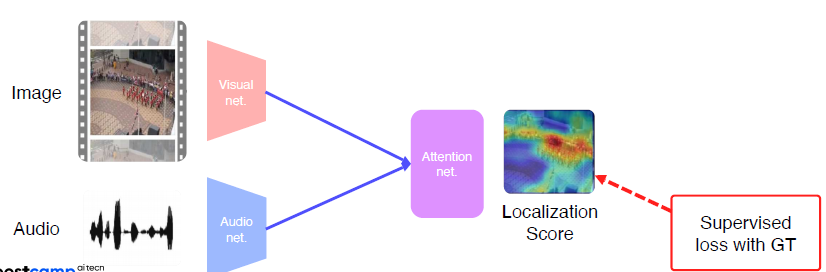
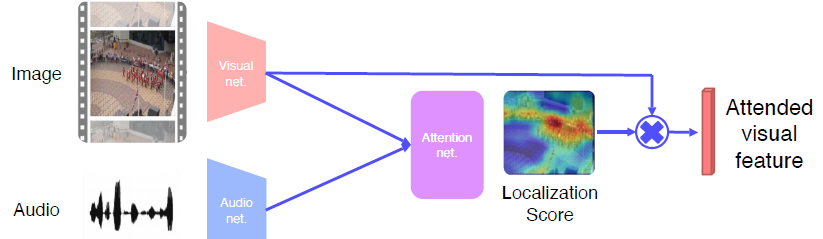
Visual net에서 뽑은 feature과 Audio에서 뽑은 feature의 내적을 통해 Attention Net 생성
loss를 구해서 Ground truth를 따라하도록 학습
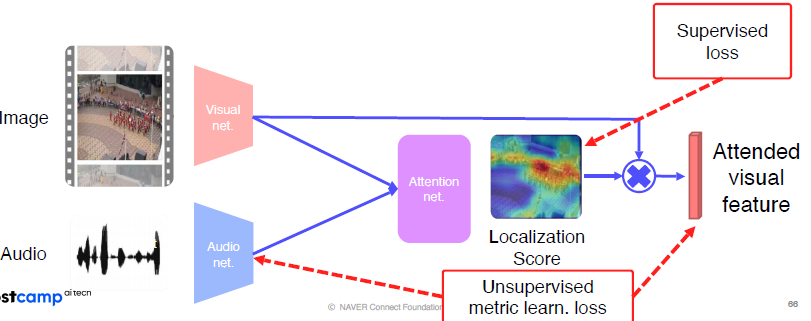
Attended visual feature 을 뽑아내고 sound와 unsupervised metric learn
-
Cocktail party
Speech saparation by Visual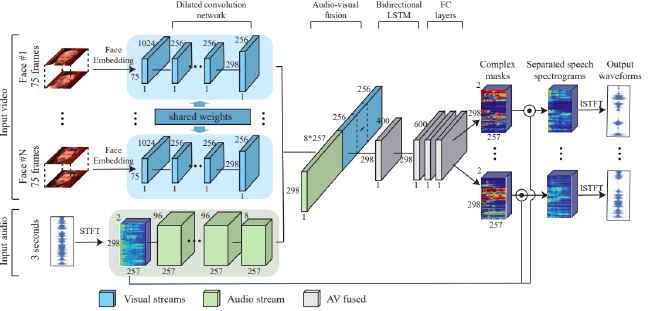
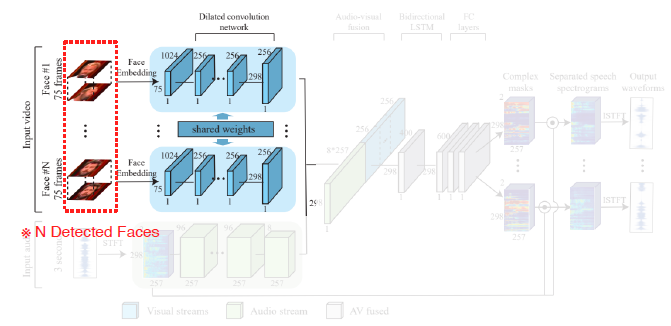
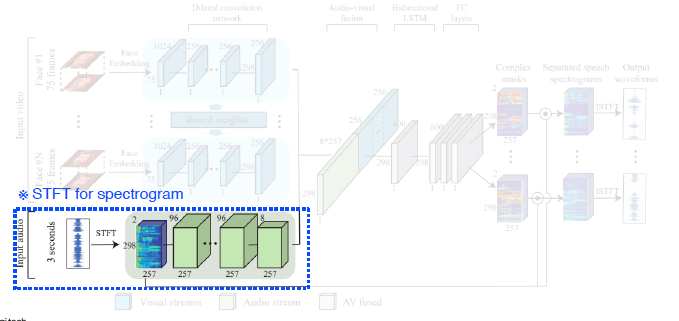
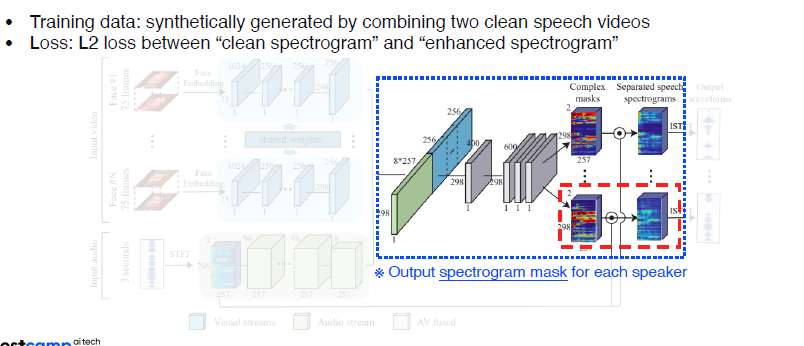
Training Data가 원래부터 분리되어 있을 수가 없다. 그래서 synthetically하게 Clean Speech를 2개 concat해서 사용한다.
-
Lip movements Generation (Obama)
-
Tesla self-driving
-
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
3. 피어세션 정리
[ 2021년 9월16일 목요일 회의록 ]
✅ 오늘의 피어세션 (모더레이터: 백종원)
- 강의 요약
- 발표자: 백종원
- 내용 : Multi-modal Learning
📢 토의 내용
- 필수과제 4번 관련 에러
- GAN Implements : https://github.com/eriklindernoren/PyTorch-GAN (공유: 조준희 캠퍼님)
📢 내일 각자 해올 것
- 모더레이터: 이양재 캠퍼님
📢 멘토링 질문 사항
4. 학습 회고
- 생각보다 양이 많고 어려웠던 게 많았던 과정이다. 그런데 시각화가 아닌 sound 등을 함께 이용할 수 있는 multi-modal learning에 대해 흥미가 많이 생겼던 강의였다.