
[네이버 부스트 캠프] AI-Tech - Lv2 week2(3)
학습기록 - 33
오늘 할 일
- Conditional generative model
1. 강의 복습 내용
Conditional Generative Model
-
Conditional Generative Model이란, ‘조건’이 주어졌을 때 그에 일치하는 ‘image’를 생성할 수 있는 모델을 말한다.
아래와 같이 ‘sketch of a bag’이 주어질 때, 확률 분포를 그려서 높은 확률로 ‘X’를 뽑아낼 수 있다.$P(X \mid$ sketch of a bag $)$
-
Generative model
먼저 Generative model은 비지도학습(Unsuptervised Learning) 중 하나로, likelihood와 사후확률를 활용해서 경계선을 만들어서 Image를 sampling 하는 model을 의미한다. 각 샘플 이미지 픽셀의 ‘분포’를 학습해서 학습 데이터와 유사한 데이터를 random sampling을 통해 생성합니다.
따라서, labeling 되지 않은 sample들을 통해서 Image를 생성할 수 있다.
-
Generative model vs Conditional generative model

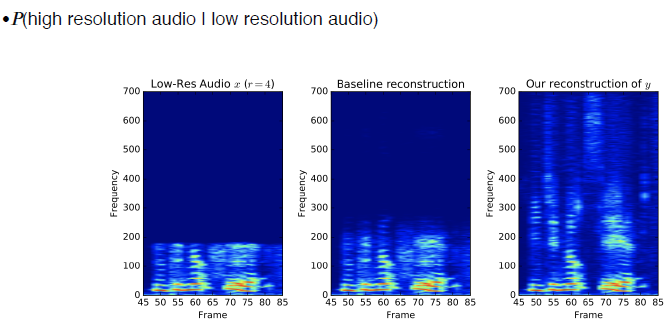
example of conditional generative model - audio super resolution
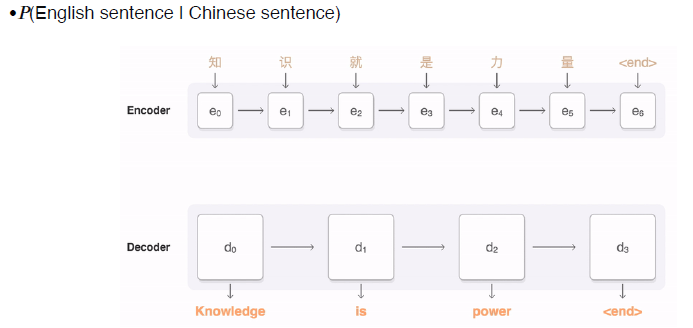
example of conditional generative model - machine translation
example of conditional generative model - article generation with the title

-
GAN - Generative Adversarial Network (생성적 적대적 신경망) 서로 적대적인 관계를 통해서 학습을 하는 방법을 말한다.
위조 지폐범 (Generator) 는 위조 지폐를 만들어 내고, 경찰 (Discriminator) 은 판별사 역할을 한다.
여기서 학습을 통해 Generator는 더 정교한 위조 지폐를 만들어 내고, Discriminator는 더 판별을 잘하게 된다.
이를 통해 더 뛰어난 생성 모델 & 판별 모델을 만들어 내게 된다.
질문) unsupervised learning or supervised learning??? -> unsupervised learning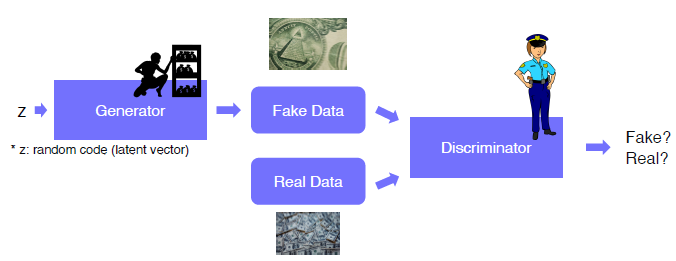
-
GAN & Conditional GAN
GAN의 장점을 그대로 가져오면서 Input에 Condition Input을 추가한다.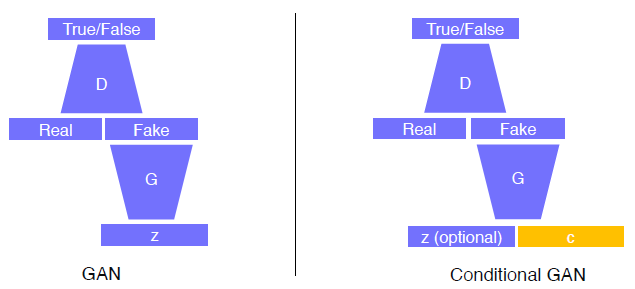
이는 Image-to-Image translation에 쓰이게 된다. Style transfer, Super Resolution, Colorization..

Super Resolution
**질문) 실제 고해상도 이미지와 input image를 쌍으로 같이 학습시켜야 되는 거 아닌가? -> 같이 **
-
Super Resolution GAN as an example of conditional GAN
Generator를 통해 LR Image를 HR Image로 만들고, Discriminator가 Real HR Image와 Fake HR Image를 판별합니다.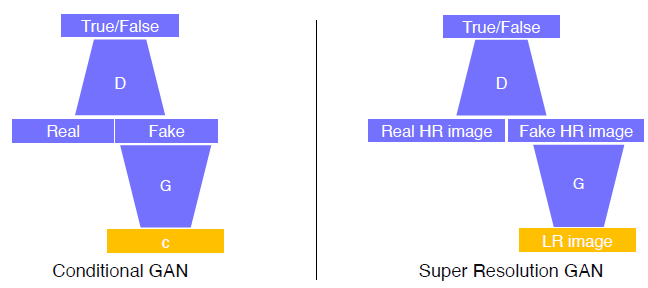
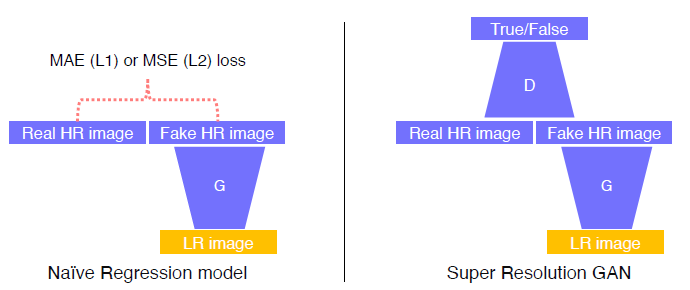
이전에 CNN을 이용할 때는 MAE or MSE를 이용한 Loss로 Regression을 해서 Generator를 학습 시켰습니다. (Regression Model)
MAE $=\frac{1}{n} \sum_{i=1}^{n}\left y_{i}-\hat{y}_{i}\right $ MSE $=\frac{1}{n} \sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}$
Mean absolute error (MAE)
Mean square error (MSE) -
Comparison of MAE, MSE and GAN losses in an image manifold
MAE, MSE는 실제 고해상도 이미지와 생성된 이미지 사이의 평균 차이를 구하는 것이기 때문에, loss는 계속 떨어질 수도 있으나, 모든 고해상도 이미지와 거리가 ‘가까운’ 이미지를 return 하게 됩니다. 따라서 blur된 Image가 나올 수도 있습니다.
하지만 GAN 같은 경우, Generator가 Discriminator의 구별을 피하기 위해 real data에 가까운 이미지를 출력으로 합니다. 그렇기 때문에, 고해상도 이미지가 나올 확률이 매우 크고, GAN Loss가 매우 낮게 나옵니다.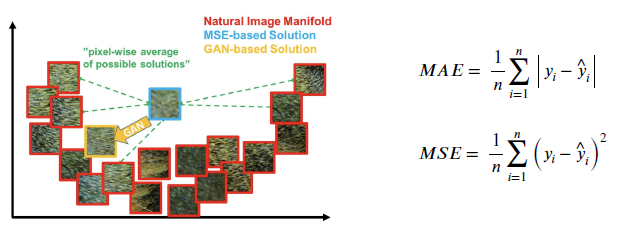
In grayscale Image,
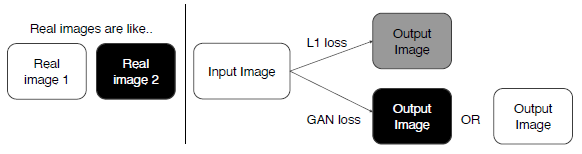
Image Translation GANs
-
Image Translation : Translating an image to a corresponding image in another domain (style, resolution.. ) Task definition을 통해 input image를 다양하게 변화시킬 수 있다.
- Pix2Pix
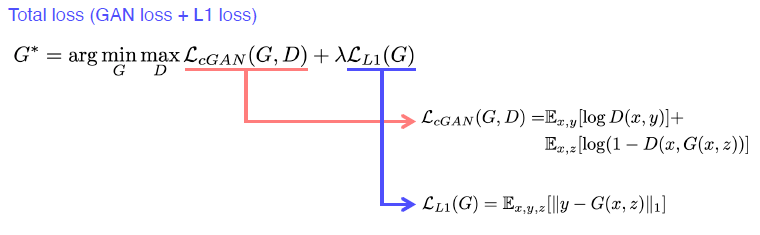
Loss function of Pix2Pix
위에서 얘기 말했듯이, L1 loss만 사용한다면 blurry images 생성 가능성이 있습니다. 그에 비해 GAN은 더 realistic한 ouput을 return 합니다. 여기서 L1 loss를 이용해서 적당한 guide로 이용하는 방법입니다.
why?- x라는 입력을 넣었을 때, 출력 pair를 가지고 있는 학습에 대해서 진행을 하게 된다. (supervised learning) GAN만 사용하면 x와 y를 독립적으로 비교해서 real, fake만 판별하기 떄문에 GAN만 사용해서는 어떤 x가 들어와도 제대로 판별할 수 없다.
- GAN의 학습이 불완전하고 어려웠기에, blurry 하지만 L1 norm을 이용해서 안정화시켰다.
Pix2Pix는 둘의 Loss를 모두 이용해서 Image를 생성한다.

질문) input image가 segmentation image이고 ground truth 모델이 다음과 같을 때, GAN에서의 output은 아예 다른 데이터가 나오게 되는데, 학습된 분포에 있는 데이터들 중에서 가장 가까운 데이터를 뽑아내는 것을 의미하는 건가?
-
CycleGAN
paired data가 아닌 unpaired data를 이용한 방법은 없을까?
CycleGAN은 서로 다른 도메인의 이미지 사이에 tanslation이 가능하도록 만든 모델입니다.
image가 완전히 같은 이미지를 가질 필요가 없습니다.
Loss는 다음과 같습니다.
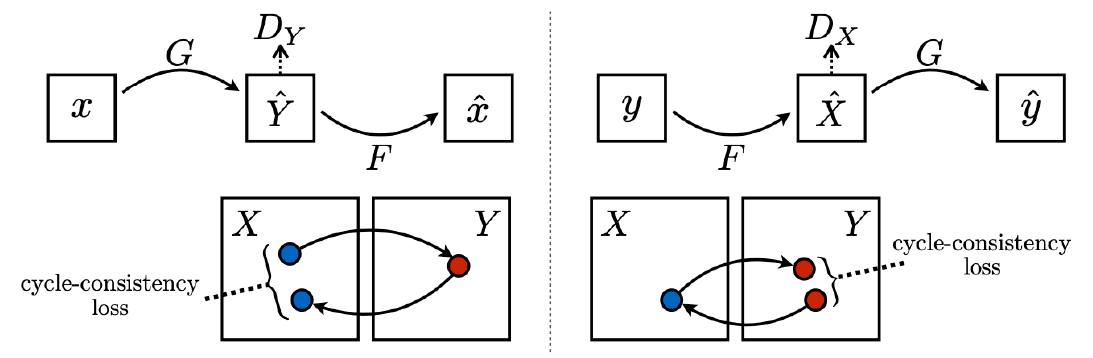
CycleGAN loss = GAN loss (in both direction) + Cycle-consistency loss
Cycle-consistency loss: translation image가 image로 돌아갔을 때, 일치하는 정도의 loss$L_{G A N}(X \rightarrow Y)+L_{G A N}(Y \rightarrow X)+L_{c y c l e}(G, F)$
CycleGAN은 2개의 generator과 discriminator를 가지고 2개의 GAN loss를 가집니다.
그렇기에 아래의 이미지에 따라 총 Loss는 다음과 같습니다.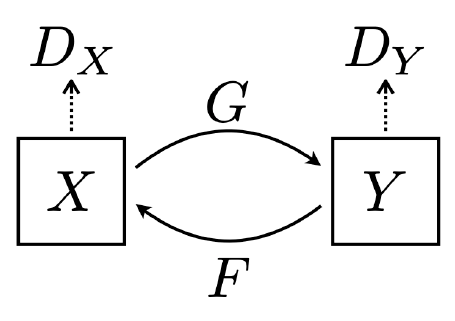
GAN loss $: L\left(D_{X}\right)+L\left(D_{Y}\right)+L(G)+L(F)$
문제점? Mode Collapse의 문제가 생기게 된다. 단순히 맞고 틀림으로 discriminate 하면서 생기는 loss를 줄이기 때문에, 다른 input에도 비슷한 이미지를 계속 생성하게 되는 현상을 말합니다.
즉, 학습이 상호 작용을 해야 하는데 한 쪽의 학습이 너무 잘되어서 다른 한쪽 (generator)이 계속 속일 수 없기 때문에 같은 이미지를 생성하게 된다.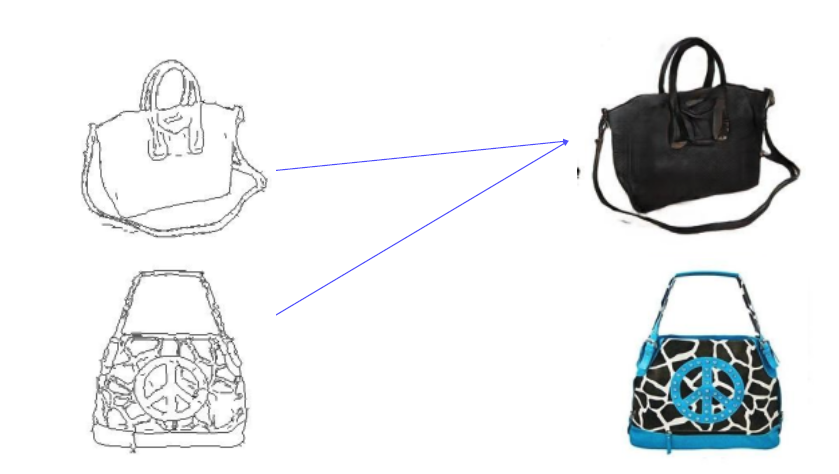
Solution : 새로 만들어진 Image와 원래 image의 cycle-consistency loss를 만들어 차이를 좁혀간다. (No supervision or self-supervision)
-
Perceptual loss
why? GAN은 항상 train하기 어려운 문제가 있다. (discriminator & generator update) GAN이 아닌 방법으로 high-quality 이미지를 수행하는 방법은?
GAN loss (Adverally loss) :
Hard to train, code. pre-trained network의 요구 x (-> data dependency가 존재)
Perceptual loss :
Simple train and code. pre-trained network 필수-
what?
Perceptual loss는 humans’ visual perception과 비슷한 filter respone을 가진 pre-trained classifers를 이용하면서 Image가 들어왔을 때 filter를 통해 Image를 지각 공간으로 transform 시켜준다. (대각선, 방향성, color 등등)
-
how?
Image Transform Net : 이를 이용해서 input으로부터 변형된 output을 생성한다.
Loss network : 다른 target style과 feature loss를 계산한다.
특징은 pre-trained 된 모델이 VGG model을 사용하고, Image Transform Net은 training 진행되는 반면, Loss Network는 Back prop을 통해 y hat만 변형시켜줄 뿐, 학습하지 않는다.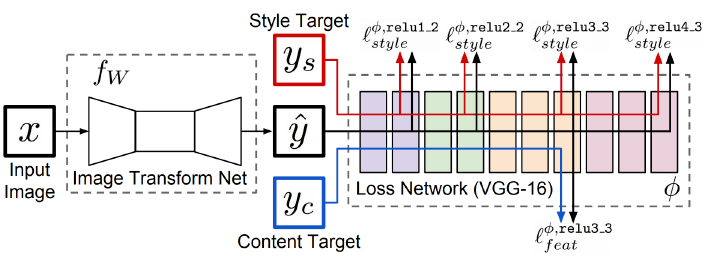
-
Feature Reconstruction loss
위 그림과 같이 Transformed Image의 featrue map과 content target (transform 되기 전 image) 의 featrue map의 L2 loss를 계산하여 back prop을 통해서 Image transform net을 학습한다.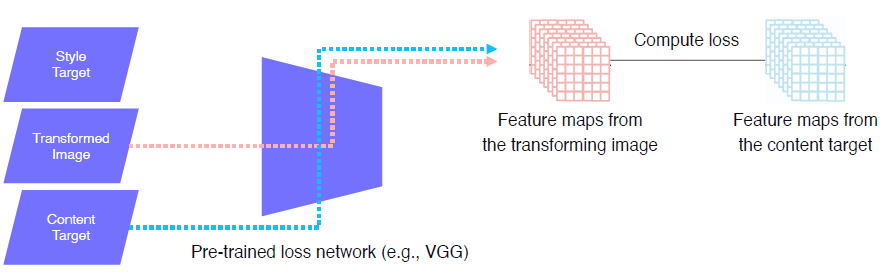
-
Style reconstruction loss
style target과 tansformed Image 모두 VGG를 통해서 feature map을 뽑아준다. style이 무엇인지 디자인 해주기 위해 “Gram matrices”를 이용한다. 전체적인 style을 적용해주는 것이 목표이기에 공간에 따른 정보를 없애주기 위해서 pooling을 시도한다. C X H, W (reshape) -> C X C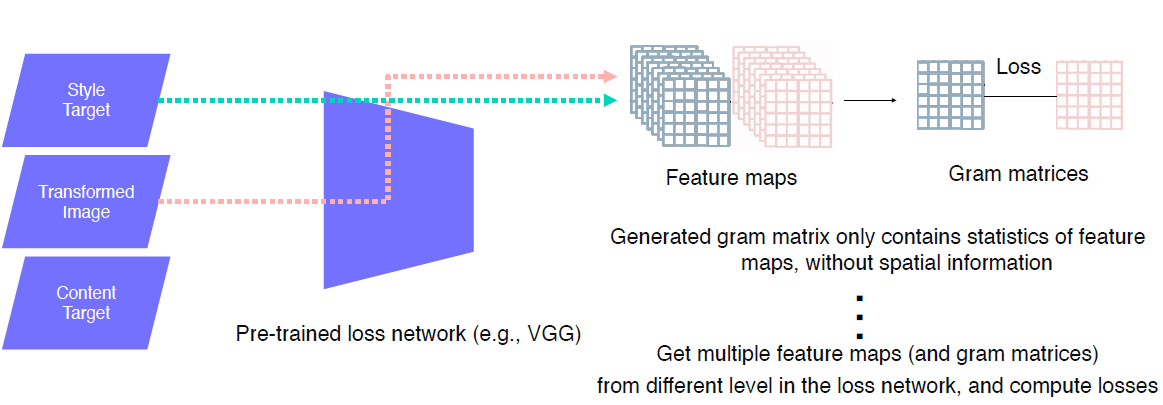
Gram matrices는 어떤 특징을 가지고 있는 것인가 ?
VGG 안에 있는 중간에 여러 layer에서 style feature들을 뽑아서 losses를 측정하고 이 loss를 통해서 style target 간에 correlation을 저장하고 있다.이를 통해 style feature map에 fixed 되고 pooling을 통해 gram matrices로 저장한다. 그리고 transformed image의 feature map의 gram matrices를 style feature의 gram matrices에 loss를 걸어서 이 style에 가까워지도록 만들어준다.
다시 말해서, Gram matrix는 feature map에서 spatial information를 배제하고, 이미지 전체의 전반적인 특징인 statistic만 포함하도록 만들었다고 생각하자.
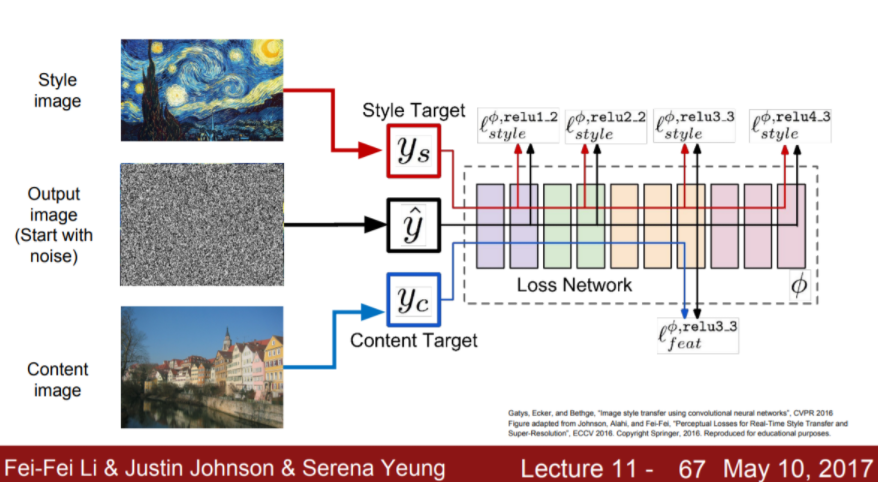

start with noise image로 시작해서 학습을 통해 목표하는 이미지를 얻는다.
-
-
Various GAN applications
-
Deepfake 윤리적인 문제에 대해 GAN을 통한 범죄 예방 기술에 대해 나오고 있다.
-
Face de-identification
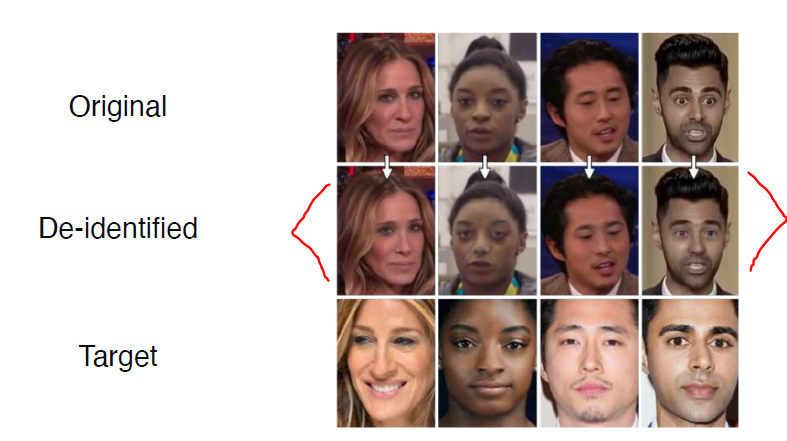
-
Face anonymization with passcode
-
Video translation
-
Voice conversion
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
3. 피어세션 정리
[ 2021년 9월15일 수요일 회의록 ]
✅ 오늘의 피어세션 (모더레이터: 김현수)
- 강의 요약
- 발표자: 김현수
- 내용 : Conditional Generative Model
📢 토의 내용
-
Pix2Pix loss 의 GAN loss 에서 x, y?
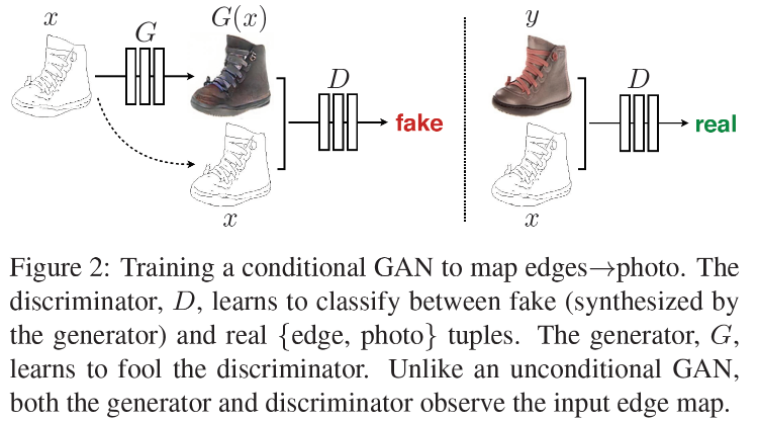
- cGAN에서 L1 Loss를 사용하는 이유?
- Super Resolution - HR (원본) 이미지와 LR (down sampling) 이미지를 cGAN에 학습시켜 super resolution 가능하도록 한다.
- Gram matrices 만들 때 feature map channel 축으로 reshape 한 vector 와 그 vector 를 transpose 해서 곱한 후, C x C 로 만들어 사용한다.
- 멘토링 시간 9/17(금) 4:30pm & 금요일 피어세션 시간 4:00 pm에 팀회고 및 강의 리뷰
📢 내일 각자 해올 것
- 모더레이터: 백종원 캠퍼님
4. 학습 회고
할 일은 많은데 시작 하기가 두려운 매일.. 걱정은 많은데 제대로 된 게 없다.
정신차리자.