
[네이버 부스트 캠프] AI-Tech - Lv2 week1(2)
학습기록 - 27
오늘 할 일
- Image Classification (Alexnet, VGG)
- 필수 과제 1 정리
- 이번 목표 : 정보 공유!, 기록, 가설을 세우고 시도를 해보자.
1. 강의 복습 내용
What I learn in this course
-
Fundamental Image tasks Image, Semantic Segmentation, Object detection & segmentation, Panoptic segmentation
-
Data augmentation and knowledge distillation
-
Multi-modal learninng ( 다른 감각 데이터들의 융합 (소리, text))
-
Conditional generative model
-
Neural network analysis by visualization
Image recognition
K Nearest Neighbors (K-NN)
어떤 데이터를 가지고 있을 때, 그 데이터 특징 주변 분포에 따라 구별할 수 있다.
- 영상 간에 유사도 지정 필요 & Complexity 고려
Convolutional Neural Network (CNN)
Fully-connected to every pixel
-
모든 픽셀에 대해서 가중치를 두고, 학습을 시키는 방법
이런 간단한 모델을 영상 구조에서의 문제점은?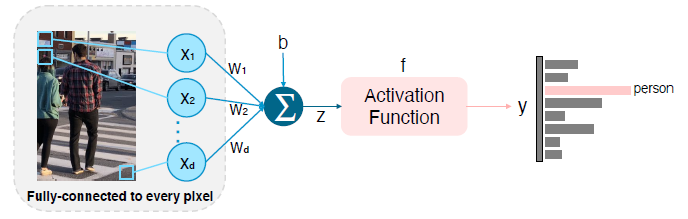
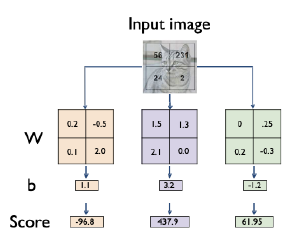
첫째, 평균적인 이미지에서만 가능 (layer 한 층),
둘째, 적용시점에 따라 달라진다. Image 템플릿의 Cropped 또는 scale이 달라지면 예측이 달라진다.
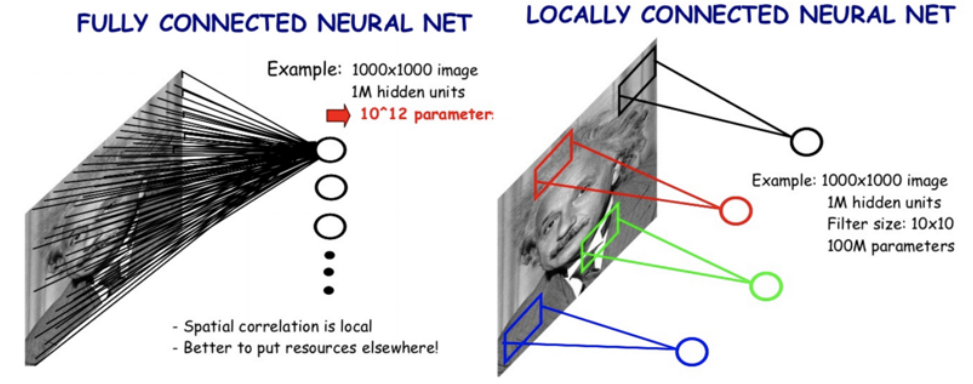
Locally Connected Neural Network
- 모든 픽셀에 대해 가중치를 두지 말고 특정 영역에 대해서만 가중치를 둬서 학습할 수 있도록 한다. (sliding window 방식)
- CNN은 Locally Connected Neural Network의 방식을 따른다. (Architecture)
- Filtering
CNN - Alexnet, VGGNet
LeNet-5
- Alexnet의 기본, Simple CNN by Yann-LeCun in 1998
- Conv - Pool - Conv - Pool - FC – FC
- 우편번호, 문자 예상에 잘 쓰여짐.
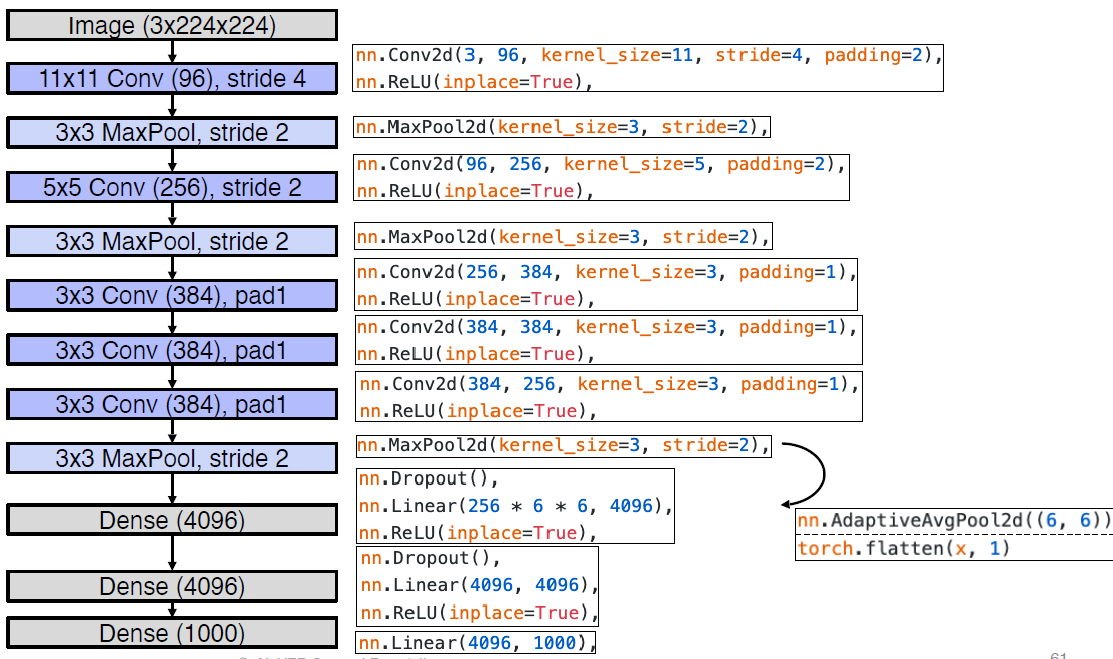
Alexnet
- Lenet 보다 네트워크 크기 증가
- Convolution는 채널 수 증가시키고 MaxPool을 통해 Image 픽셀 수를 줄여준다. ReLU function & Dropout을 통해서 Vanishing Gradient 방지, Regularization.
- Dense Layer 가 2048이 아닌 4096인 이유는 GPU의 개수가 2개 -> 1개인 상황으로 되었기 때문이다. 과거엔 GPU를 2개로 나눠서 사용했었다.
-
Flatten 과정을 통해서 Image를 3D에서 2D로 만들고 (Tensor to Vector) classification이 가능할 수 있게 만들어준다.
-
Local Response Normalization
요즘은 사용하지 않는다. -> Batch normalization - Receptive Field
각 단계의 입력 이미지에 대해 하나의 필터가 커버할 수 있는 이미지 영역의 일부를 뜻한다. Convolution을 할 때, 픽셀이 아닌 특정 영역에 한정해서 처리를 하는 방법
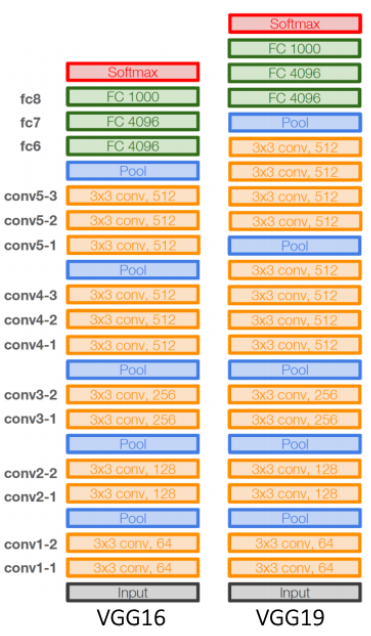
VGGNet
-
Alexnet 보다 좀 더 깊은 Architecture를 가진다. 3X3 Convolution과 2X2 max pooling만을 이용한다.
-
Deeper, Simpler Architecture / Better Performance, Generalization
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
VGG-11 구현
-
VGG-11 Customizing
-
논문의 내용을 토대로 VGG-11를 커스터마이징 한다.
VGG의 특징은 3X3 커널 사이즈를 기준되어있고, 2X2 max pooling을 이용한다. -
Convolution을 통해 채널의 개수를 점점 늘고, max pooling을 통해 이미지 사이즈가 점점 줄게 된다.
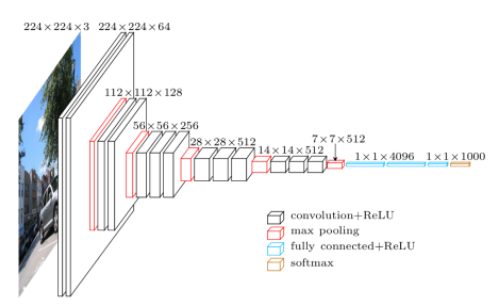
feature들의 Convolution이 끝난 후 Classifier 구간에서 Linear 한 값으로 바꾸기 위해서 flatten을 하게 되는데, 이 때, size는 (1, image size X Channel) 이 된다. (아래의 경우, 7 X 7 X 512 = 25088)채널의 변화 : Conv2D (3channel -> 64 -> 128 -> 256 -> 512 ) -> Linear (25088 -> 4096 -> 4096 -> 10 )
이미지 사이즈의 변화 : image size (224 -> 112 -> 56 -> 28 -> 14 -> 7) -
다음은 VGG-16 (layer)의 예시이다. 11과 비슷하지만, layer의 개수가 더 많다.
-
Training Customized Model을 Training 한다. Training / Validation할 때, 주의할 점..
1) model을 cuda (GPU) 를 이용해서 돌린다. - 이미지 사이즈에 의해 RAM이 감당을 못한다. & Data 또한 cuda 설정을 해주자.
2) model.train()
3) opimizer.zero_grad(), loss.backward(), optimizer.step()
4) model.eval()
5) torch.no_grad() - 평가만 필요하기 때문에 미분 X
-
-
VGG-11 Fine-tunning with pretrained feature extractor
-
torchvision에서 제공하는 pretrained VGG-11을 이용한 fine-tuning 학습을 진행하게 된다. Fine-tuning의 경우도 기본적인 training 방법은 동일하지만, 이번에는 모든 parameter를 처음부터 학습하는 대신 feature extractor는 기존 학습된 상태에서 고정하고 linear classifier만 새로 학습한다는 차이가 있다.
-
freeze를 통해서 기존 학습된 파라미터는 다시 학습하지 않고, 새롭게 추가된 classifier만 학습할 수 있도록 만듭니다. 나머지는 위에서 했던 과정과 같다.
from torchvision.models import vgg11 # torchvision's vgg-11을 가져옴 pretrained = True model_finetune = vgg11(pretrained) # features라는 이름을 포함한 layer만 gradient를 Freeze 시켜준다. for name, layer in model_finetune.named_parameters(): if 'features' in name: layer.requires_grad = False # classifier에 마지막 feature에 dimension을 10으로 만들어 준다. model_finetune.classifier[6] = nn.Linear(4096, 10) # model의 layer의 이름과 freeze되었는 지 상태 점검 for name, layer in model_finetune.named_parameters(): print("=" * 40) print("%-20s == > Train : %s" % (name, layer.requires_grad)) #model 정보 출력 print(model_finetune) -
model에 대한 정보를 출력하는 다른 방법인 torchsummary 방법이다. 위 문제와는 관련 없지만 모델의 파라미터 갯수나 layer에서 output 되었을 때, shape을 정리해서 볼 수 있다.
출처 : pytorch-summaryfrom torchsummary import summary device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') vgg = model_finetune.to(device) summary(vgg, (3, 224, 224))
-
3. 피어세션 정리
[ 2021년 9월07일 화요일 회의록 ]
✅ 오늘의 피어세션 (모더레이터: 김현수)
- 강의 요약
- 발표자: 김현수
- 내용: Image classification - 1
- cnn from scratch : https://setosa.io/ev/image-kernels/
- haar cascading
📢 내일 각자 해올 것
- 모더레이터: 백종원 - 강의 2 강, Data Viz
- 필수 과제 리뷰, 질문
📢 내일 우리 팀이 해야 할 일
- 톡방 이용한 질문 확인
📢 Ground rule 수정사항
- 공유 피피티를 활용해 자유롭게 익명으로 질문을 남긴다. - 익명 질문톡방에 질문을 남긴다
4. 학습 회고
- 간만에 거의 혼자 힘으로 과제를 완성했다. 이제 혼자 논문을 구현해보고 싶은 욕심이 생긴다. 조금만 더 이해를 잘하고 싶다. 아직 이제 완벽히 알겠다!라고는 못하겠다.