
[네이버 부스트 캠프] AI-Tech - Lv2 week1(1)
학습기록 - 26
오늘 한 일
- 강의
- 필수 과제
- 이번 목표 : 정보 공유!, 기록, 가설을 세우고 시도를 해보자.
1. 강의 복습 내용
Annotation Data Efficient Learning
Dataset은 대부분 Biased 한 형태로 존재하게 된다. (training data != real data)
이러한 sample data 와 biased data 사이의 차이를 메꾸기 위해서 Augmentation을 이용한다. 이 세상에 찍힐 수 있는 가능성을 높여준다.
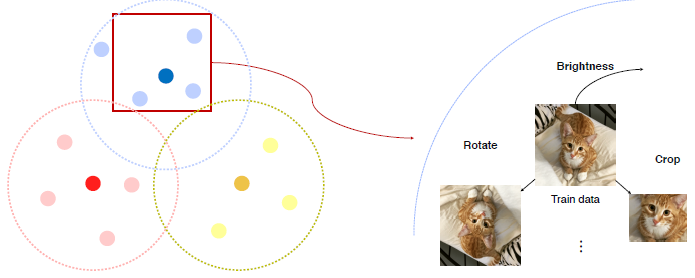
Augmentation
- Brightness, Rotate, flip, Crop,
Affine Transform : 픽셀 위치를 이용해서 Warp시킴 CutMix : 사진의 합성 (입력, 출력의 비율을 함께 준다.) RandAugment : 여러 가지 영상처리의 조합이 중요하다. 모든 가능성이 아닌 자동적으로 최선의 Augmentation Sequence를 찾아주는 기법. 그 sequence를 ‘Policy’라고 한다.
N개의 augmentation 를 Random Sampling해서 Poilcy를 샘플화하고 이 Policy로 Train 후, Accuracy를 측정.
Leveraging Pre-trained information
-
Transfer Learning
- Approach 1 : pre-training model을 가져와서 마지막 FC Layer만 바꿔주는 방법 (적은 양의 데이터일 때 유용)
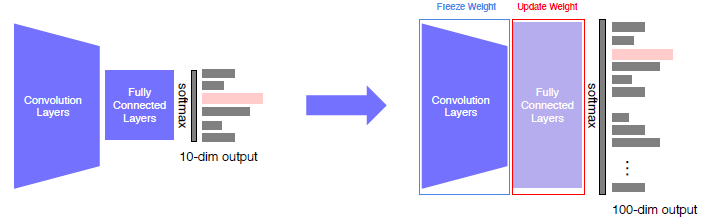
- Approach 2 : Fine-tuning the whole models, Learning rate를 다르게 줘서 전체 모델을 학습시키는 방법 (많은 양의 데이터에서 좀 더 정확해진다.)
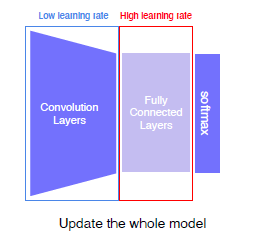
-
Knowledge distillation (증류)
- train된 model의 지식을 다른 작은 모델에 전달해주는 것, 임의의 데이터 사용 가능 & Label이 없는 Unsupervised Learning으로 볼 수 있다.
Teacher의 예측과 Student의 예측의 KL div.Loss를 Student로 BackProp을 진행해서 학습시킨다.
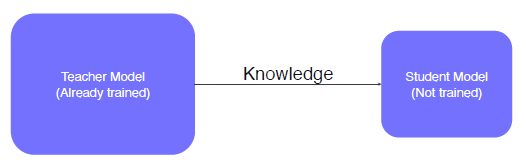
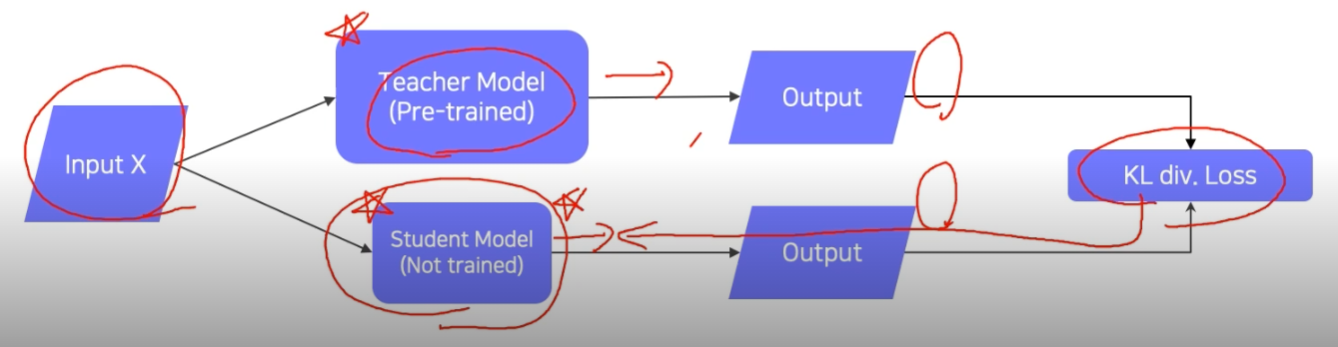
- Label이 있을 경우, Teacher model의 output에 가까운 답을 예측할 수 있도록 한다.
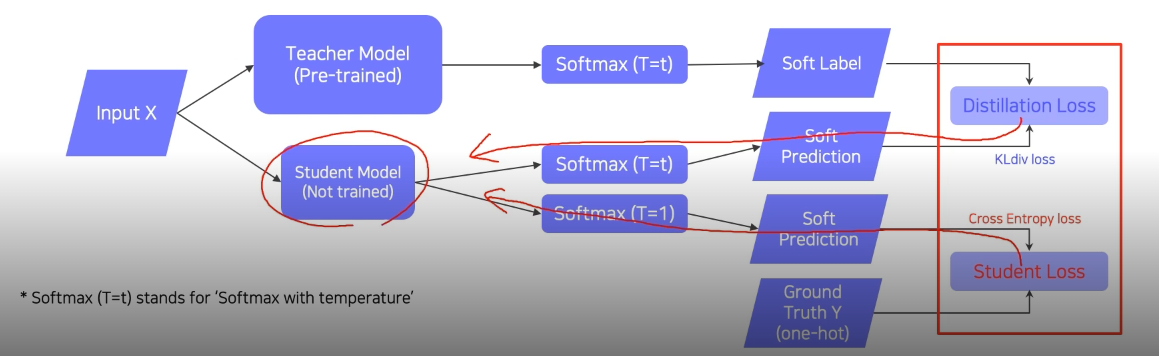
Softmax (T=t) 는 Soft label 방식으로 label이 만들어진다. 이것은 student가 Teacher의 output을 ‘흉내낼’ 수 있도록 만들어준다.
Softmax (T=1) 은 Hard label 방식으로 label이 만들어진다. 실제 값과 비교를 통해 Student 스스로의 학습을 할 수 있도록 한다.
Hard Prediction & Soft Prediction
- train된 model의 지식을 다른 작은 모델에 전달해주는 것, 임의의 데이터 사용 가능 & Label이 없는 Unsupervised Learning으로 볼 수 있다.
Leveraging unlabeled dataset for training
-
Semi-supervised Learning : Unsupervised (No label) + Fully Supervised (fully labeled)
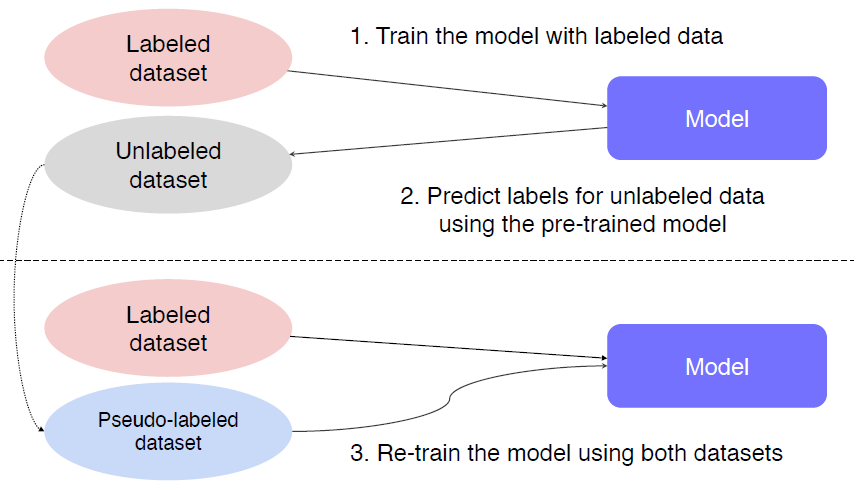
-
Self-training : Augmentation + Teacher-Student networks + semi-supervised learning(pseudo labeling)
pseudo labeling을 이용해서 만들어진 데이터와 labeled data를 “Random Augmentation”을 시켜서 “Student”모델을 학습 시킨다.
학습된 Student Model을 “Teacher”모델로 갖고와서 다시 위의 과정을 반복한다. 이 과정을 통해서 Model이 점점 더 커진다.. ?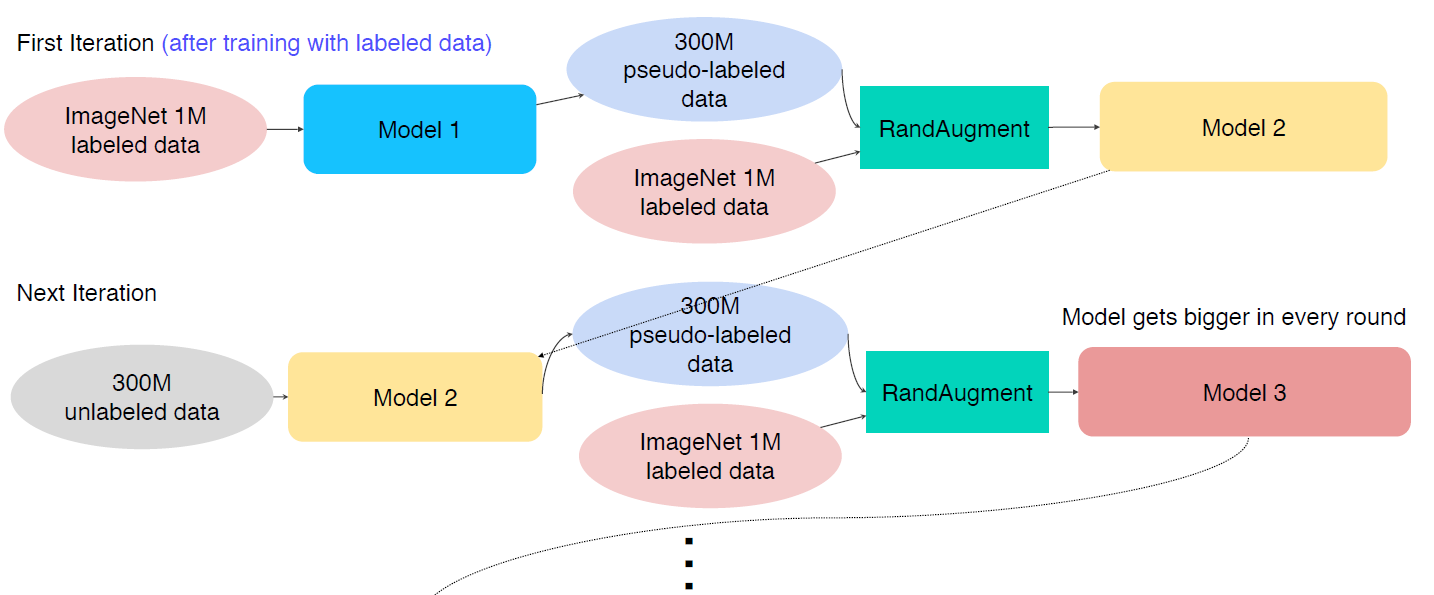
Image Classification (Image-level Classification)
AlexNet
VGGNet
GoogleNet
-
1 by 1 convolution filter
-
Auxiliary classifier Test시에는 사용하지 않는다.
ResNet
- Degradation Problem
DenseNet
SENet
EfficientNet
- deep, wide, high resolution -> 적은 flow에서도
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
3. 피어세션 정리
4. 학습 회고
-
Meet up : 이력서에서 간단한 스토리 라인 Github 링크, 어떤 챌린지가 있었고, 어떻게 개선했을까?
-
지금까지 했던 내용 중 CNN에 관련한 내용에 대해 복습하는 느낌이었다. 가볍게 강의를 들었고, Image Classification에 사용되는 CNN에 대해 조금 깊게 다룰 수 있었다.