
[네이버 부스트 캠프] AI-Tech-re - week4(5)
학습기록 - 19
오늘 한 일
- 강의
- 모델 - 커스터마이징, vscode 모듈화 & 팀 제출
- 팀 회고, 개인 회고
1. 강의 복습 내용
강의
Ensemble
싱글 모델보다 더 나은 성늘을 위해 여러 학습 모델을 사용.
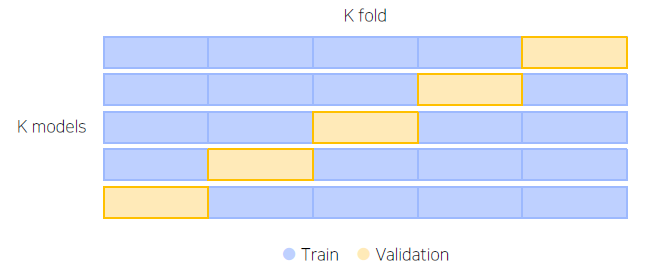
Cross Validation (CV 점수)
여러 Validation Set을 적용해서 앙상블을 하자. (K fold CV)
K-fold CV
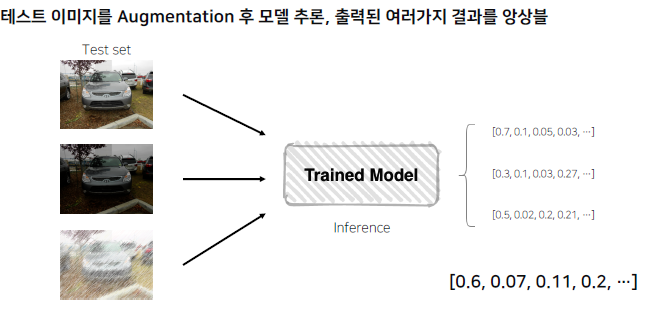
TTA (Test Time Augmentation)
Test할 때, Augmentation을 왜 하지? - Test Set도 다른 상태로 넣어봐서 어느 정도 결과를 테스트
성능과 효율의 Trade-off
Hyperparameter Optimization -> 효과가 뛰어나지는 않다.
- Learning rate, Hidden Layer 갯수, K-fold, .. ,
-
스코어를 높이는 데 적절한 파라미터들을 변경해야한다. (Hyperparmeter Optim) 하지만 계속 학습을 해야한다는 단점이 있다.
-
“내 모델의 성능을 최대한 올릴 수 있는 Hyperparameter를 자동으로 찾는다.”는 관점에서는 상당히 큰 메리트가 있습니다. 그런 의미에서 최근 급부상하고 있는 AutoML분야에서 이 Hyperparameter Opt는 상당히 중요한 요소중 하나
- Optuna
Experiment Toolkits & Tips
Training Visualization
-
Tensorboard from torch.utils.tensorboard import SummaryWriter tensorboard

-
wandb : 사이트 Python IDLE vs Jupyter notebook
tip
-
논문 코드 확인 페이지 : 사이트
논문을 분석할 때는 설명글을 유심히! -
같이 공유하는 것
-
배웠던 것을 잘 습득하자. . .
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
3. 피어세션 정리
4. 학습 회고
주간 회고
활동 :
- P-Stage (EDA, DataSet & Generation, Model, Training & inference, Ensemble)
- 이미지 분류 개인 프로젝트
- 마스터 클래스 (김태진 강사님) & 오피스 아워
회고 (개선사항)
- 지난 주에 회고했던 대로, Pandas, Numpy 강의와 documentation을 많이 보면서, 친해지도록 했다. 아니 그냥 Dataset 생성과 EDA를 통해서 Pandas를 많이 이용할 수 밖에 없었던 것 같다. 데이터 분석은 어려웠지만 직접 조작해서 Dataset을 만들었을 때 결과를 보면서 만족했고 기뻤다.
- 모델링은 아직 부족한게 많았다. Pretained model을 이용해서 했는데, 아직 Customizing을 어떻게 해야할 지 감이 안잡혀서 제대로 시도하지 못했다. 감이 안잡혔다기 보다는 뭔지 모를 두려움(?) 주어진 Baseline을 이용해서 안되더라도 계속 파고 들어야겠다고 생각했다. → 모듈화 & 모델 customizing 시도
- 여러 세부사항에 대해서 따로 지정한 코드를 보고 내가 코드를 너무 대충 갖다 붙였다는 생각이 들었다.과제의 목적이 원래 만들어져 있는 코드를 사용하는 것이 아닌 가능한 세부 사항까지 조정하면서 만들어야 하는 것이었는데,너무 게으르게 했던 것 같다. -> 정확한 문제 정의를 하고 문제 해결하자.
- 마스터 클래스에서 지금 나의 상태에 대해 잘 짚어주는 얘기들을 들었다. 누구보다 뒤쳐져 있는 것 같고, 혼자 힘들어하는 것 같다고 느끼는데,모두가 다 그렇다는 것이라고 알려주셨다. → 자신의 실력을 인정하고, 상황을 인지해서 나에게 적합한 공부 찾아 나가기.
다음 주 계획
- 매일 시간 관리 & 계획
- 매일 쓰는 회고록에 정확한 문제를 정의하고 해결했던 글을 쓰자.
- vscode에 Network 모델 모듈화 & baseline 코드 파악