
[네이버 부스트 캠프] AI-Tech-re - week4(4)
학습기록 - 18
오늘 한 일
모더레이터
강의 발표정리
알고리즘 문제 - 단지 번호 붙이기,
코드 리뷰 - 모델 코딩 & 코드 리뷰용 주석
회고
1. 강의 복습 내용
강의
Training & Inference (2)
학습과 추론 프로세스가 어떤 과정으로 이루어지는지?
Training 준비
이전에 배웠던 내용에 대한 정리.
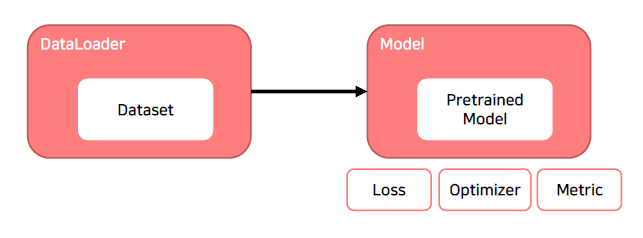
Training 프로세스의 이해
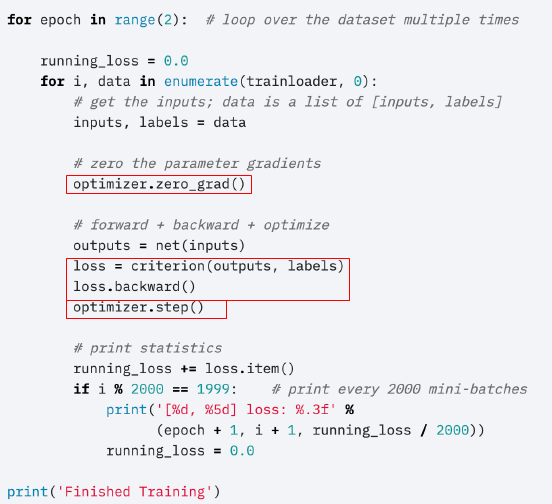
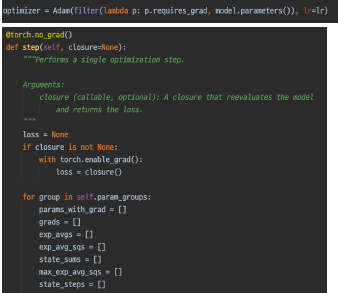
- model.train()
: training mode와 evaluation 모드에 따라 ‘Dropout’ 과 ‘BatchNorm’의 과정이 조금씩 달라진다.

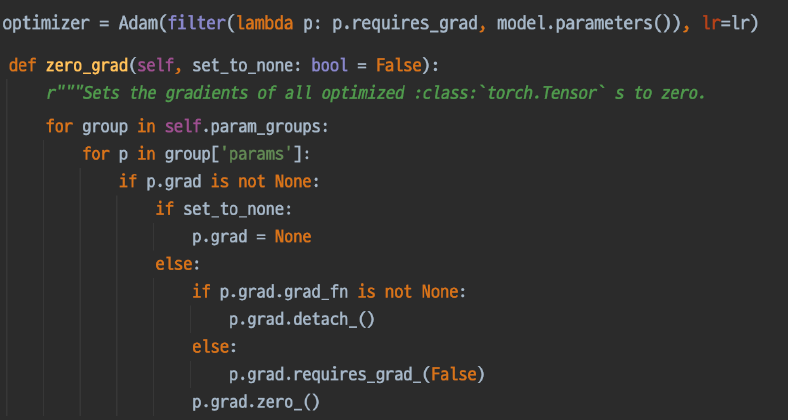
- optimzer.zero_grad()
모델 안에 있는 파라미터의 gradient를 초기화시켜주는 역할이다.
이전 Batch에서 loss를 통해 grad를 발생, Optimizer.step를 수행하면서 Gradient를 컨트롤 하게된다. → 각 Parameter의 grad가 남아있게 되는 상태
이후 Batch에서 이전에 만들어진 gradient를 초기화 시켜줘서 사용하지 않도록 한다. → 현재 Batch에 생성된 Gradient만 쓴다.
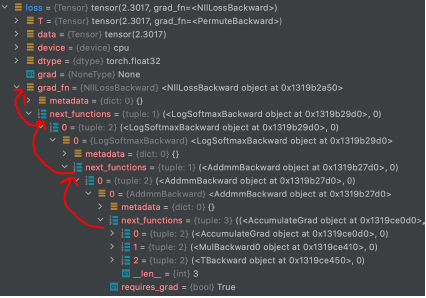
- loss = criterion(output, labels)
model을 통해 만들어진 output과 실제 값이 labels의 CrossEntropy를 통해 손실 함수가 만들어진다.
nn.Module이기 때문에 forward함수를 통해 loss까지 chain이 만들어졌다는 것을 알 수 있다. → grad_fn에 추가 → backward()통해 grad를 업데이트

- optimizer.step()
위에 과정을 통해 Parameter의 모든 grad가 적용이 되어 있다.
optimizer는 적용하는 방식에 따라서 모든 grad에 업데이트를 해주게 된다.
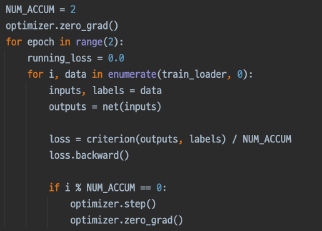
- More : Gradient Accumulation
batch_size가 크고 GPU가 한정적일 경우, batch_size를 작게해서 큰 batch_size와 비슷한 효과를 나타내게 해주는 방법
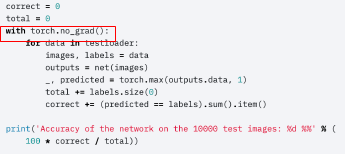
Inference Process
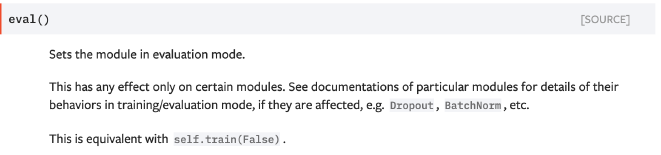
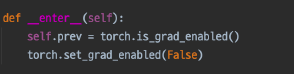
- model.eval()
-
with torch.no_grad()
검증의 결과만 알 수 있도록 gradient를 구하지 않음
-
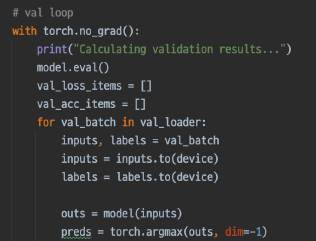
Validation
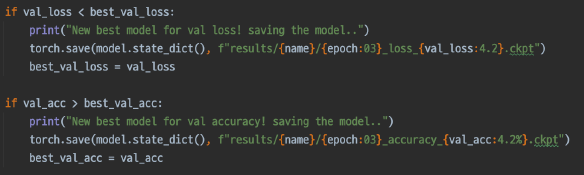
- 최종 Output, Submission
Appendix: Pytorch Lightning
위의 많은 과정들을 한 줄로 축약해서 나타냄. -> keras Tensoflow 처럼 이용
