
[네이버 부스트 캠프] AI-Tech-re - week4(2)
학습기록 - 16
오늘 한 일
- 강의 o
- EDA 데이터 멀티 바 그래프 & 20~30대 묶기
- Dataset에 input, output 클래스 만들기
- 백준알고리즘 - N번째 큰 수, DFS BFS
- 개인회고
1. 강의 복습 내용
강의
overview → 방향성에 대해서 알려준다. 여기서 우리가 해야할 점은?
Pre-processing
Pre-processing 전처리 작업은 다음 그림처럼 모델에 이용하기 전에 작업해야할 가장 중요한 작업이다.

“Data Mining” : 대량의 데이터가 축적되어 있는 데이터베이스로부터 데이터간의 정보 분석, 정보 추출
“Data Analysis” : EDA를 이용, 뽑아낸 data들이 의미하는 바가 무엇인지? 분석하는 역할
Generalization :
위와 같은 분석을 한 이후, 모델의 학습이 어느 한쪽으로 치우치지 않게 ‘일반화’과정을 한다. 일반적으로 Training Set을 이용해서 학습을 하는데 이곳에만 overfitting되는 경우를 방지하기 위해 Validation Set - 검증을 통해 일반화 확인
- Data Augmentation : Data가 다양한 case와 state로 들어올 수 있다. 데이터의 여러 상태 등을 고려해서 데이터를 부풀려 성능을 좋게 만든다. ex) Transform(flipping, cropping, … ) (→ Data Loader 함수 사용 시 parameter로 있다.), Albumentations
모든 것엔 정답은 없다. 실험으로 계속 증명해야 한다.
Data Processing
Data Processing → Modeling을 잘 하는 방법은?
Data Feeding : 모델에게 데이터라는 먹이를 준다는 것은 어떤 의미인가? 그냥 데이터를 많이 준다는 것이 아닌 모델이 갖고 처리량에 따라 데이터를 효율적으로 줘야한다.
그렇다면 Data를 효율적으로 만들기 위해서 쓰는 방법은?
‘torch.utils.data’에서 Dataset을 이용해서 원하는 데이터를 초기화 시켜주고 추출가능하도록 상속함수를 만들어준다. 이를 통해 원하는 데이터를 더 빠르게 뽑아줄 수 있다.
DataLoader에서 빠르게 추출할 수 있는 Dataset을 가져와 Data를 효율적으로 사용할 수 있도록 기능을 추가해준다. (num_workers, batch_size, drop_last … )
이 두가지 기능을 이용해서 모델에서 이용할 데이터를 효율적으로 사용할 수 있도록 만들어준다.
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
과제
Dataset / DataGeneration
Vanilla Data를 이용해서 이미지와 해당하는 클래스 Label (18개 중 하나) Pytorch Dataset Class를 직접 생성해보세요. & 분포
torchvision에 내장된 여러 Augmentation 함수와 albumentation 라이브러리의 여러 transform 기법을 적용해보세요.& plot
-
간단한 Data Viz
age별 남녀 분포 작업 Grouped Bar plot, stacked bar plot 이용해서 만들기
# "gender"를 기준으로 "age" columns count를 sort group = data.groupby('gender')["age"].value_counts().sort_index() # plot, y scale 공유 fig, axes = plt.subplots(1,2, figsize = (12, 7), sharey = True) axes[0].bar(group['male'].index, group['male'], color='royalblue') axes[1].bar(group['female'].index, group['female'], color='tomato') plt.show()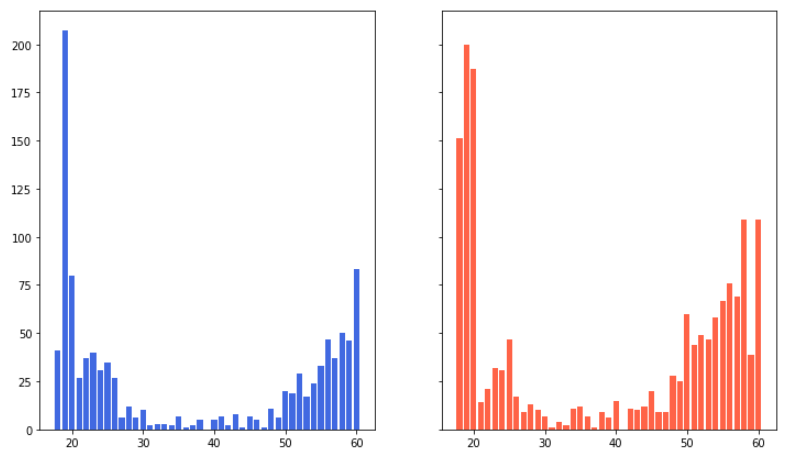
Bar 형태로 Grouping
fig, ax = plt.subplots(1, 1, figsize=(12, 7)) group = group.sort_index() idx = np.arange(len(group['male'].index)) width=0.35 ax.bar(idx-width/2, group['male'], color='royalblue', width=width) ax.bar(idx+width/2, group['female'], color='tomato', width=width) ax.set_xticks(idx) ax.set_xticklabels(group['male'].index) plt.show()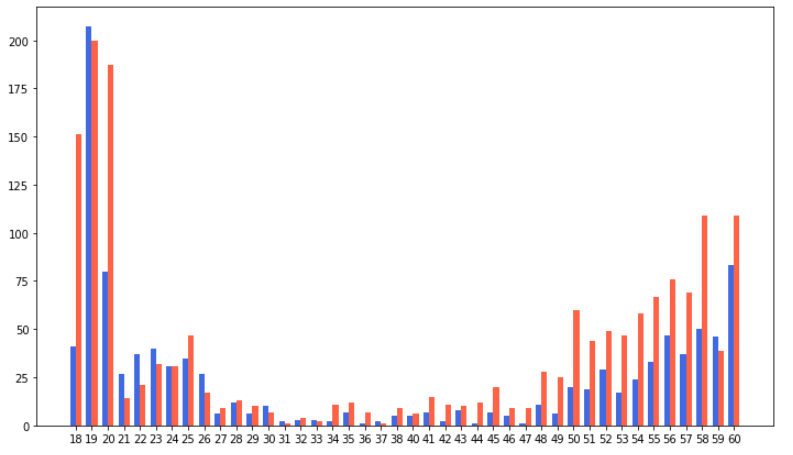
20대 30~50대 60대 묶어서 출력하고 싶다? 나이별로 묶어서 데이터 프레임 재생성하고 출력하면 되지 않을까? -> 실패
#https://emilkwak.github.io/pandas-dataframe-settingwithcopywarning #Warning 일어남 #데이터 프레임을 직접 바꾸면 안된다. fig, ax = plt.subplots(1,1, figsize = (12, 7)) age_list = [[],[],[]] age_dict = {'gender': pd.Series(["female", "male","female", "male","female", "male"], index=['20','20', '30,50','30,50', '60', '60']), 'value':pd.Series([0, 0,0, 0,0,0], index=['20','20', '30,50','30,50', '60', '60'])} # 나이대별로 그룹화 group_A = data.groupby('age').gender.value_counts() new_data = pd.DataFrame(age_dict) """ gender value 20대 male female 30~50대 male female 60대 male female """ sample = age_dict["value"] for i in range(len(group_A)): if group_A.index[i][0] < 30: if group_A.index[i][1] == "female": sample[0] += group_A.values[i] else: sample[1] += group_A.values[i] elif 30<= group_A.index[i][0] <60: if group_A.index[i][1] == "female": sample[2] += group_A.values[i] else: sample[3] += group_A.values[i] else: if group_A.index[i][1] == "female": sample[4] += group_A.values[i] else: sample[5] += group_A.values[i] age_dict["value"] = sample new_data = pd.DataFrame(age_dict) print(new_data) # Seiries 바꿔서 데이터 프레임 재생성 # 그 이후로 plot 실패 # 안되네! 패스! -
Dataset 생성
train.csv에서 주어진 것은 ‘경로’만 있을 뿐 ‘Image’에 대한 내용은 따로 없었다.
그래서 고민한 방법이 train2.csv 데이터를 만들어서 마지막 column에 image name과 결과 class를 추가하는 방법을 생각했다.
하지만 원본 데이터를 pd로 가져와서 조정한 후에 다시 csv로 넣을 이유는 굳이 없을 것 같았다.
새로운 데이터 프레임을 만들었다.#code train = pd.read_csv(os.path.join(train_dir, 'train.csv')) image_dir = os.path.join(train_dir, 'images') image_folder_dir = [os.path.join(image_dir, img_path) for img_path in train. path] image_name = ["incorrect_mask.jpg", "mask1.jpg", "mask2.jpg", "mask3.jpg", "mask4.jpg", "mask5.jpg", "normal.jpg"] # image_path 생성 image_column = [i for _ in range(len(train)) for i in image_name] image_paths = [os.path.join(image_dir, img_name) for image_dir in image_folder_dir for img_name in image_name] # 조건문 이용해서 클래스 생성 condi_list = [] class_column = [] for i in train.path: k = i.split("_") condi_list.append([k[1], int(k[3])]) for condi in condi_list: for j in image_name: if "incorrect" in j: start = 6 elif "mask" in j: start = 0 else: start = 12 if condi[0] == "female": start += 3 if 30 <= condi[1] < 60: start += 1 elif 60 <= condi[1]: start += 2 else: if 30 <= condi[1] < 60: start += 1 elif 60 <= condi[1]: start += 2 class_column.append(start) # img path & img name(mask) & class name 생성 new_data = pd.DataFrame(image_paths, columns=["image_paths"]) new_data["image_name"] = image_column new_data["class_num"] = class_column print() print(new_data.head())image_paths image_name \ 0 /opt/ml/input/data/train/images/000001_female_... incorrect_mask.jpg 1 /opt/ml/input/data/train/images/000001_female_... mask1.jpg 2 /opt/ml/input/data/train/images/000001_female_... mask2.jpg 3 /opt/ml/input/data/train/images/000001_female_... mask3.jpg 4 /opt/ml/input/data/train/images/000001_female_... mask4.jpg class_num 0 10 1 4 2 4 3 4 4 4그리고 만들어진 데이터 프레임을 데이터 셋에 넣어서 input과 output을 만들어 모델이 학습할 수 있도록 해줬다.
class TrainDataset(Dataset): def __init__(self, new_data, transform): self.img_paths = new_data.image_paths self.transform = transform self.y = new_data.class_num def __getitem__(self, index): image = Image.open(self.img_paths[index]) if self.transform: image = self.transform(image) return image def __len__(self): return len(self.img_paths)일단 데이터 셋까지는 얼추된 것 같다.
그 다음은 모델을 어떻게 학습시킬 것인가?에 대한 고민이다.
어떤 모델을 어떻게 사용할 것인지 생각해봐야 한다.
3. 피어세션 정리
- 강의 요약
- 내용: DataSet/Generation
- 알고리즘-DFS, BFS (python and C++)
4. 학습 회고
- 학습을 위한 dataset 만들기 : 고민을 세가지로 만들 수 있었다.
첫번째, image까지의 경로를 어떻게 만들어줄 것인가?
두번째, class 어떻게 라벨링 해줄 것인가?
세번째, 어떻게 Dataset까지 넘겨줄 것인가?
첫번째 Image까지의 경로는 train 폴더 내에 있는 incorrect ~ normal까지 파일명을 파악해서 새로운 list로 만들어줬다.
Image까지의 dir와 list안에 값들을 각각 join시켜서 리스트화 시켰다.
두번째 clas 라벨링은 train.csv에 있는 path를 split 하고 조건을 걸만한 gender와 age를 뽑아내서 리스트 형태로 만들어주고 그것을 다시 리스트 안에 넣었다.(condi_list)
condi_list안에 넣은 것과 image_name list를 이중 for문으로 함께 돌리면서 모든 조건을 확인했다.
여기서 중요한 점은 조건이 mask의 정보를 먼저 골라서 start 위치를 만들어주고 그 안에서 gender, age에 따라 start 위치를 바꿔줬다.
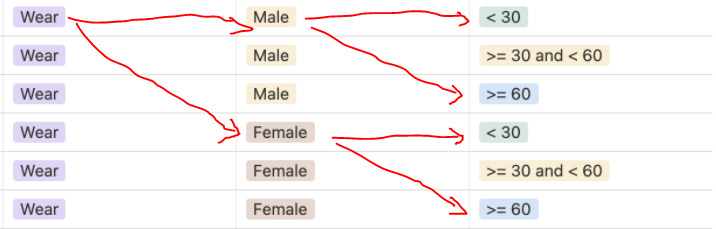
세번째는 이 리스트들을 담을 공간인 pd.DataFrame을 이용했다. Dataset 안에서도 뽑아서 쓸 수 있기 때문에 괜찮은 선택이라고 생각했다.
- EDA :
이건 진짜 너무 어려웠다.
age에 따라 bar, stacked, grouping을 하는 것까진 가능했는 데, 내가 원했던 20대, 30~50대, 60대를 만드는 것은 자꾸 꼬였다.
pandas에서 편리하게 끄집어낼 수 있는 방법이 있을 거라고 생각은 하는데 잘 보이지 않는다.
‘groupby’를 이용해서 age에 따라 끄집어낼 수는 있는 데 여기서 조건을 다는 방법을 못찾겠다..