
[네이버 부스트 캠프] AI-Tech-re - week4(1)
학습기록 - 15
오늘 한 일
- 이미지 분류 강의 & 가이드 라인 숙지
- 서버 등록
- 개인 회고
1. 강의 복습 내용
강의
overview → 방향성에 대해서 알려준다. 여기서 우리가 해야할 점은?
Problem Definition (문제 정의)
우리가 어떤 문제를 해결해야할 것인지 ‘정의’해야 한다.
데이터에 대한 설명?
Data Description : File 형태, Metadata Field 소개 및 설명
Notebook?
데이터 분석, 모델 학습, 테스트 셋 추론의 과정을 ‘서버’에서 연습 가능
Discussion? 등수를 올리는 것보다, 문제를 해결하고 싶은 마음! 자료를 공유하면서 틀린 부분을 수정하고 새로운 시야를 얻는 것 → 성장하자.
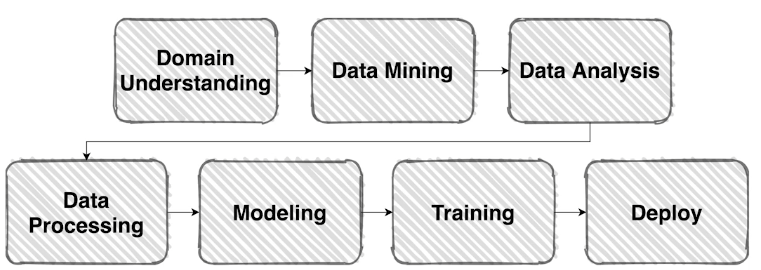
문제 정의를 하고 프로세스대로 생각해보자.
Image Classification & EDA
EDA ? (탐색적 데이터 분석)
데이터가 어떤 특징이 있는지? 왜 이 데이터를 줬는지? 데이터를 이해하기 위한 노력! 내가 데이터에 대해 공부하고 분석하는 일! 중요 중요!
Image → Model → Output 에서 Image(input) 과 Output의 정의를 명확히 해야한다. 스스로 코드를 작성해보면서 성장하자. BaseLine은 예시 코드이긴하지만, 이게 답이 될 수는 없다.
P-stage?
어떻게 P-stage가 돌아가는 것인가?
ssh를 이용해서 서버에 연결한 후, 노트북을 이용해서 model을 구현하고 예측값 (submission.csv) 파일을 만들어서 제출하는 방식이다.
캠프에서 주어진 설명이 너무 길어서 일단 sample_submission에 주어진 내용을 돌려봤다. submission.csv 파일이 나왔고 다운로드 받아 제출했다. 있는 그대로 제출해서 정확성은 확실히 떨어졌다. 여기서 내가 해야할 일은 model의 알고리즘 또는 데이터의 전처리? 등을 이용해서 정확성을 높이는 알고리즘을 구현해보는 것인 것 같다.
Baseline code description?
답안 코드라고 생각하자. 근데 dataset, loss, model, … 다 나눠져있는 거 보니까 sample이용해서 끼워 맞춰야하는 것 같다.
Special Mission?
Data가 어떤 특성을 가지는지 분석을 해보는 것 같다. (EDA) 시각화를 이용해서 input, output 데이터를 구현해보자.
우리가 해야할 목표는
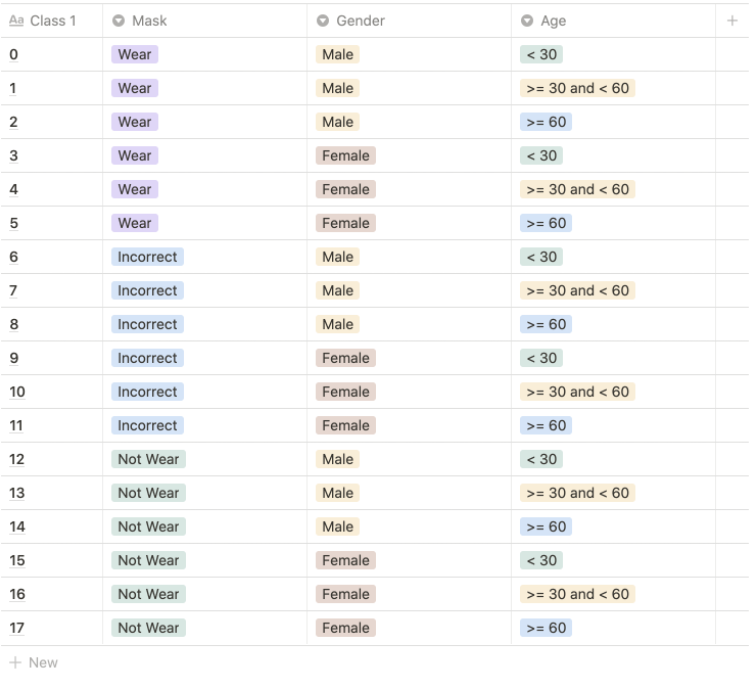
이렇게 총 18개의 클래스로 나누는 것이다.
(train data) 는 다음과 같이 정보가 주어진다.
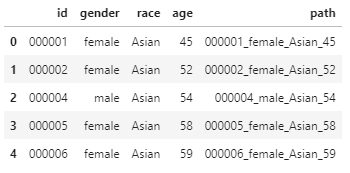
우리가 사용해야할 input data는?
output은 mask, gender, age 로 나뉨
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
-
모델을 처음보고 무슨 문제인지 이해하기 어려웠다. 문제를 하나씩 뜯어보고 주어진 것은 샘플이었는 데 학습한 모델을 평가하는 코드인 것을 이해했다.
-
서버에 연결하고 학습되지 않은 모델을 평가하는 것 자체를 제출했다.
-
정확도는 당연히 떨어졌고, 모델을 학습시키기 위해 주어진 데이터를 파악했다. train.csv 와 image, eval과 info.csv 였고, 나는 train을 이용해서 모델을 학습시켜야 했다. (문제 정의)
-
고민해야할 점은 어떻게 라벨링?을 할 것인가이다. 파일명 자체를 바꿀 생각을 했는데 원본 데이터는 손실내면 안되겠다고 생각했다.
그래서 주어진 경로와 파일명을 뜯어서 조건에 따라 클래스를 나누려했다.
잘 안된다.
이유는 결과값을 만들어서 어떻게 써야할지 감이 안잡힌다. model의 구성에 따라 x, y를 쓰는 게 다르지 않나? sample에 있던 model은 training을 할 수 있는 모델인가?
일단 이게 고민이라 라벨링 한다해서 되나? 생각이 든다.
class TestDataset(Dataset):
def __init__(self, img_folder_dir, image_paths, transform):
self.img_folder_dir = img_folder_dir
self.img_paths = image_paths
self.transform = transform
img_folder_name = [os.path.basename(img_folder_name) for img_folder_name in self.img_folder_dir]
# if 문을 이용해서 mask에 따른 조건문 설정
for folder_name in img_folder_name:
folder_name_split = folder_name.split("_")
if folder_name_split[1] == "female" and folder_name_split[3]:
3. 피어세션 정리
- 강의 요약
- 내용: P-stage overview
- p-stage 관련 질문
4. 학습 회고
- 학습을 위한 dataset 만들기 :
init 부분에서 파일명과 경로를 이용해서 클래스를 나누어주려 했으나, 그 다음을 모르겠어서 시도가 잘 안된다.
이렇게하면 샘플에 있는 모델을 이용한 학습을 할 때, 학습이 가능한건가?
또, 고민이 되는 것은 경로를 어디까지 읽어오고 어디서 image를 읽을 때 분류를 해줘야 하나 생각이 든다. init에서 해주는게 맞다고 생각이 들긴하는데..