
[네이버 부스트 캠프] AI-Tech-re - week3(4)
학습기록 - 14
오늘 한 일
- 멘토링
- 필수 과제 1, 2 제출
- Data Viz 정리
- 강의 3개 정리 (8, 9, 10)
- 오피스 아워 (과제 해설)
1. 강의 복습 내용
Multi-GPU
multi-GPU 상에서 학습을 분산하는 두가지 방법
1) 모델 나누기
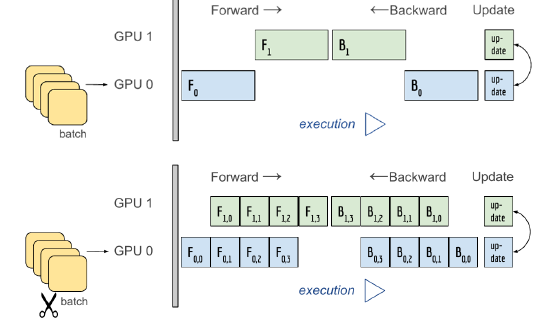
2) 데이터 나누기
- mini-batch 수식과 유사, 데이터를 나눠 GPU에 할당, 결과의 평균을 취함.
- DataParallel : 단순한 데이터 분배 후 평균 → GPU 사용 불균형 & 배치사이즈 감소
- DistributedDataParallel : 각 CPU마다 process 생성하여(CPU도 분배) 개별 GPU에 할당 → 개별적으로 연산의 평균을 구함

3) 코드
- DataParallel 의 경우, torch.nn.DataParallel(model) 을 이용
-
DistributedDataParallel 의 경우, train sampler, pin memory 사용
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
멀티 프로세싱을 위한 개별 코드 필요
from multiprocessing import Pool def f(x): return x*x if __name__ == '__main__': with Pool(5) as p: print(p.map(f, [1, 2, 3]))
Hyperparameter Tuning
학습을 제대로 할 수 있는 방법?
1) 모델을 바꾸는 방법, 2) 데이터를 추가해주는 방법, 3) H/T
‘데이터를 추가’ 하는 방법이 가장 효율적이다.
Hyperparameter Tuning
-
모델 스스로 학습하지 않는 값은 사람이 지정
(learning rate, 모델 size, optimizer 등)
-
많은 성능을 기대하기는 어렵다. → 많은 데이터로 극복
가장 기본적인 방법
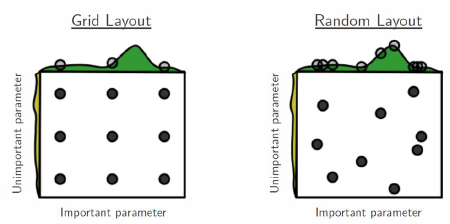
- Grid Search : rate를 0.1 → 0.01 → 0,01 or batch size를 32 → 64 → 128
- Random Search : Random하게 가져다가 쓴다.
- 최근에는 베이지안 기반 기법 주도
Ray ( 실습 )
- multi-node multi processing 지원 모듈
- ML/DL의 병렬 처리를 위해 개발된 모듈
- Hyper Parameter Search 지원
- 어느 정도 성능이 나왔을 때, 마지막 수단으로 하자.
OOM (Out Of Memory)
왜 발생했는지 알기 어려움
Error backtracking이 이상한데로 감
메모리의 이전 상황의 파악이 어려움
1차원적 해결법 : Batch Size를 줄이거나, Colab의 경우 런타임 초기화
또 다른 해결법
-
GPUUtil 사용하기
nvidia-smi 처럼 GPU의 상태를 보여주는 모듈

-
torch.cuda.empty_cache() 써보기
사용되지 않은 GPU상 cache를 정리
Garbage collector의 기능을 강제한다.
계속 쓰는 것보다는 학습 전에 GPU를 먼저 청소하고 학습시킨다.

-
trainning loop에 tensor로 축적 되는 변수는 확인할 것
tensor로 처리된 변수는 GPU 상에 메모리를 사용하게 된다.
loop안에 backward와 같은 연산이 있을 때, GPU에 computational graph (반복 미분을 하는 노드)를 생성하게 된다. ( 메모리 잠식 )
1-d tensor의 경우 python 기본 객체로 변환하여 처리 (GPU에 메모리를 넣지 않음)
total_loss = 0 for x in range(10): # assume loss is computed iter_loss = torch.randn(3,4).mean() iter_loss.requires_grad = True total_loss += iter_loss # iter_loss.item -
del 명령어를 적절히 사용하기
loop을 돌 때, 특정한 경우 loop이 끝나도 메모리를 계속 차지함 → memory를 free
-
가능한 batch 사이즈 실험해보기
batch 사이즈 1로
oom = False try: run_model(batch_size) except RuntimeError: # Out of memory oom = True if oom: for _ in range(batch_size): run_model(1) -
torch.no_grad() 사용
backward pass를 쓰지 않기 때문에 GPU 메모리에서 자유로움
with torch.no_grad(): for data, target in test_loader: output = network(data) test_loss += F.nll_loss(output, target, size_average=False).item() pred = output.data.max(1, keepdim=True)[1] correct += pred.eq(target.data.view_as(pred)).sum() -
예상치 못한 에러 메세지 & 그 외…
https://brstar96.github.io/shoveling/device_error_summary/
사이즈를 너무 크게 잡지 말자 in colab (linear, CNN, LSTM)
CNN → 대부분 에러는 크기가 안맞는다.
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
필수 과제 - Custom DataSet
- CountVectorizer
-
빈도 수를 파악
class IrisDataset(Dataset):
def __init__(self):
iris = load_iris()
######################################TODO######################################
self.X = iris['data']
self.y = iris['target']
self.feature_names = iris['feature_names']
pass
################################################################################
def __len__(self):
len_dataset = None
######################################TODO######################################
#len_dataset = len(self.X[np.random.choice(self.X.shape[0], 10)])
len_dataset = len(self.X[torch.randint(10, (10,))])
pass
################################################################################
return len_dataset
def __getitem__(self, idx):
######################################TODO######################################
X = torch.Tensor(self.X[idx])
y = self.y[idx]
pass
################################################################################
return X, y
Titanic
-
init하는 부분에서 features를 하드 코딩했다. 뽑는 법이 필요한 데
어떻게 뽑는지? features_name이라는 메소드가 있는지? data가 무슨 타입인지?
이런 문제에서 시간을 다 보냈다.
여기서 data가 pandas라는 것을 봤고, pd를 제대로 이용하지 못했다. -
getitem에서 X와 y 값을 어떻게 뽑아야할지, 어떻게 하나의 행씩 뽑아야할 지 감이 안잡혔다.
pandas를 이용해서 어떻게 풀긴했지만 확실하게 모른다는 것을 느꼈다. 기본 강의가 아닌 df에 대한 거부감 없이 pd, np에 대해 찾아보자.
class TitanicDataset(Dataset):
def __init__(self, path, drop_features, train=True):
self.data = pd.read_csv(path)
self.data['Sex'] = self.data['Sex'].map({'male':0, 'female':1})
self.data['Embarked'] = self.data['Embarked'].map({'S':0, 'C':1, 'Q':2})
######################################TODO######################################
self.features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
self.classes = ['Dead', 'Survived']
self.X = self.data[self.features]
self.y = self.data["Survived"]
pass
def __getitem__(self, idx):
X, y = None, None
######################################TODO######################################
X = torch.tensor(self.X.loc[idx])
y = torch.tensor(self.y.loc[idx])
pass
################################################################################
return torch.tensor(X), torch.tensor(y)
해설
class TitanicDataset(Dataset):
def __init__(self, path, drop_features, train=True):
self.data = pd.read_csv(path)
self.data['Sex'] = self.data['Sex'].map({'male':0, 'female':1})
self.data['Embarked'] = self.data['Embarked'].map({'S':0, 'C':1, 'Q':2})
######################################TODO######################################
self.train = train
self.data = self.data.drop(drop_features, axis=1)
self.X = self.data.drop('Survived', axis=1)
self.y = self.data['Survived']
self.features = self.X.columns.tolist()
self.classes = ['Dead', 'Survived']
pass
def __getitem__(self, idx):
X, y = None, None
######################################TODO######################################
X = self.X.iloc[idx].values
if self.train:
y = self.y.iloc[idx]
pass
################################################################################
return torch.tensor(X), torch.tensor(y)
3. 피어세션 정리
- 강의 요약
- 내용: Multi-GPU, Hyperparameter Tuning, Pytorch Troubleshooting
-
질문
-
알고리즘 : 최대 N 찾기
- 팀 회고
4. 학습 회고
주간회고
활동 :
- 파이토치 강의 ( Basic & Dataset & Dataloader & Monitoring .)
- 필수 과제 1, 2 + 선택과제
- 마스터 클래스 (최성철 교수님), (유석문님)
회고 (개선사항) :
- 이번 주는 강의가 이론적으로 파는 느낌이 아니라 실습위주로 흘러가는 느낌이었다. 이론에 있어서 어려운 점은 없었는데 필수 과제를 푸는데 시간이 오래 걸렸다. 하지만 시간에 쫓기지 않고 현재 내 수준에서 완벽히 이해할 때까지 끝까지 다 읽고 풀어서 얻은게 많았다.
- 마스터 클래스를 통해 데이터 사이언티스트 & 테스트(?) 분야에 대해 새롭게 알게 되었다. 미래에 나아갈 방향에 대해 좀 더 생각해볼 수 있는 기회였다.
- 시간 관리 & 계획을 잡았음에도 시간이 오래 걸렸던 부분은 모르는 것을 제대로 파악하지 못한 채 무작정 검색, 도큐만 계속 쳐다봤던 것 같다. 확실하게 모르니까 질문도 하기가 힘들었다. → 정확히 무엇을 모르는 지 파악하자. 그 때 모른다면 질문하자.
- 필수 과제 2를 하면서 numpy, pandas 특히, pandas를 이용한다는 것에 대해 생각을 못했다. 행렬에 대한 기피(?) 같은게 있는 느낌 → numpy, pandas를 자주 보고 만들어보면서 친해지기
다음 주 계획 :
- 매일 시간 관리 & 계획
- 무엇이 문제이고 모르는 지 확실히 알고 따지면서 학습하기.
- documentation (기본) 에 대해 확실히 이해하기.
- 모르면 계속 질문하기
- numpy, pandas와 친해지기
- 알고리즘 제대로 풀기!