
[네이버 부스트 캠프] AI-Tech-re - week3(3)
학습기록 - 13
오늘 한 일
- 파이토치 강의 정리 (6강, 7강)
- 필수 과제 2 시작
1. 강의 복습 내용
강의 1,2
모델 불러오기 & Monitoring tools for PyTorch
모델 불러오기
Transfer Learning을 하기 위해서 이번엔 파이토치에서 모델을 불러오고 이용하는 것을 목표로 한다.
학습 결과를 공유하고 싶을 때는 학습 결과를 지속적으로 저장해야한다.
model.save()
- 학습의 결과 저장
- 모델 아키텍처와 파라메터 저장
- 모델 학습 중간 과정 저장 → Early stopping
- drive파일 옮기는거 어떻게?
from google.colab import drive
drive.mount('/content/drive')
내 구글 드라이브와 연결시켜준다. (mount) 파일옮길때 내 구글 드라이브로 파일 가져와서 mount할 때 옮겨주는 방법을 쓰자.
-
모델 정보 확인?
from torchsummary import summary summary(model, (3, 224, 224))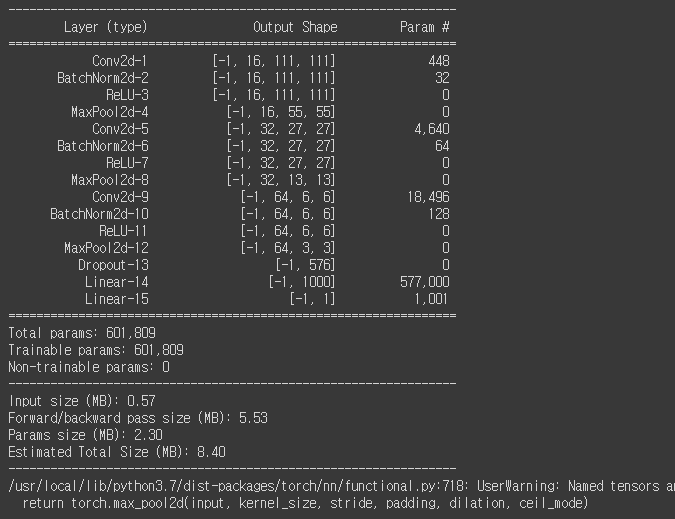
Check points
- 학습의 중간 결과를 저장, 최선의 결과 선태
- Earlystopping 기법 사용 시, 이전 학습의 결과물을 저장
- dict type으로 저장
- Epoch 내에서 원하는 정보를 원하는 위치에 저장 ( drive
for e in range(1, EPOCHS+1): ... ... torch.save({ 'epoch': e, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': epoch_loss, }, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/ len(dataloader)}.pt") # 단계마다 model의 정보 저장 by dict # saved에 저장한다면, 그 정보를 볼 수 없다. # (현재 가상환경이기 때문에) -> 구글 드라이브 이용
Transfer learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
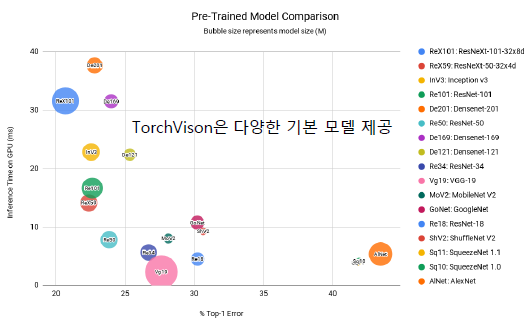
- Torch Vision 을 이용해서 모델 성능 비교 & 가져오기
-
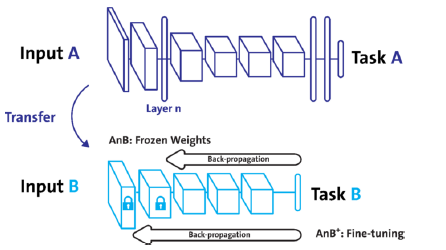
Freezing : pretrained model을 활용 시 모델 일부분 frozen
-
모델 가져와서 할당
vgg 논문의 모델을 torchvision에서 가져온다.
import torch from torchvision import models device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') vgg = models.vgg16(pretrained=True).to(device) # pretrained = true에서 이전 모델 가져옴 print(vgg)마지막 linear layer를 추가한다는 게 무슨 뜻? outfeature가 1이니까 이미지의 yes or no를 분류?
vgg.fc = torch.nn.Linear(1000, 1) # 마지막 linear layer를 추가한다? vgg.cuda() -
frozen
# 모든 파라미터들이 미분 안되도록 하고, # 마지막 linear_layers의 파라미터들만 grad 가능하게 한다. # Frozen, model 성능 검증 for param in my_model.parameters(): param.requires_grad = False for param in my_model.linear_layers.parameters(): param.requires_grad = True -
Pretained Model
data_loader를 이용해서 가져온 모델의 성능을 검증하고, Frozen 시켰을 때 와 시키지 않았을 때의 모델의 성능검증 비교
기존 레이어를 가져가서 레이어를 새롭게 업데이트하는 것보다는
이미 완성된 레이어를 학습을 진행하는 것이 더 나음을 보여준다.
시키기 전
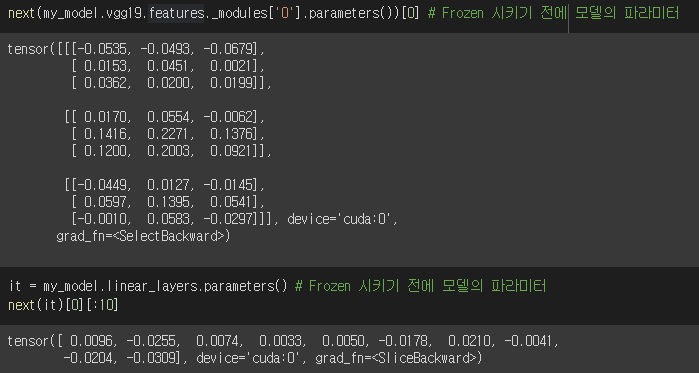
시킨 후
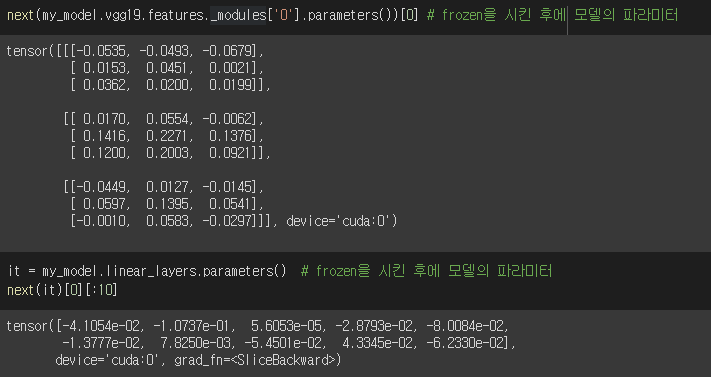
Monitoring tools for PyTorch
딥러닝의 학습시간이 대부분 긴데 이것을 모니터링할 수 있는 기능 소개
→ Tensor Board, Weights & Bias
Tensor Board
-
튜토리얼을 이용해서 사용해보자.
-
반드시 writer.flush()를 통해 저장한 정보를 써야 그래프가 출력됨.
-
홈페이지 튜토리얼 활용도 가능하다.
import os logs_base_dir = "logs" os.makedirs(logs_base_dir, exist_ok=True) from torch.utils.tensorboard import SummaryWriter import numpy as np exp = f"{logs_base_dir}/ex2" writer = SummaryWriter(exp) for n_iter in range(100): writer.add_scalar('Loss/train', np.random.random(), n_iter) writer.add_scalar('Loss/test', np.random.random(), n_iter) writer.add_scalar('Accuracy/train', np.random.random(), n_iter) writer.add_scalar('Accuracy/test', np.random.random(), n_iter) writer.flush() %load_ext tensorboard %tensorboard --logdir "logs"
Weight & bias
- 머신러닝 실험 시 사용
- table 형태로 여러 가지 정보를 바로 제공해줄 수 있다.
- https://wandb.ai/hyunsoo
-
아래 코드 처럼 설정과 활용 방법이 있다. 홈페이지 튜토리얼 활용도 가능하다.
#config------------------------------------ !pip install wandb -q import wandb wandb.init(project="my-test-project", entity='hyunsoo') #learning start & record to wandb-------------------------------------------------------- EPOCHS = 100 BATCH_SIZE = 32 LEARNING_RATE = 0.001 config={"epochs": EPOCHS, "batch_size": BATCH_SIZE, "learning_rate" : LEARNING_RATE} wandb.init(project="my-test-project", config=config) for e in range(1, EPOCHS+1): epoch_loss = 0 epoch_acc = 0 for X_batch, y_batch in train_dataset: ... train_loss = epoch_loss/len(train_dataset) train_acc = epoch_acc/len(train_dataset) print(f'Epoch {e+0:03}: | Loss: {train_loss:.5f} | Acc: {train_acc:.3f}') wandb.log({'accuracy': train_acc, 'loss': train_loss})
새로운 도구들에 많이 도전하자!
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
필수 과제 - Custom Model 제작
apply는 모든 모듈에 함수를 적용시킨다고 생각하면 된다.
그 함수에는 모듈이 파라미터로 들어가는데, 그 모듈을 이용해서 정의해주면 된다.
partial(func, obj)
이 함수는 잠깐 동안 함수의 상태를 어떤 ‘명령어’에 저장해주는 것이다. 아래에서 쓰인 방법은 module.extra_repr 이라는 명령어에 저장해주고, repr을 할 때, extra_repr을 호출하기 때문에 이 방법을 썼다.
“일종의 트릭이라고 봐야하나?” → 새롭게 명명해주는 것이 아닌 본래 있던 함수에 행동을 줘서 호출하는 것
model = Model()
# TODO : apply를 이용해서 부덕이가 원하는대로 repr 출력을 수정해주세요!
from functools import partial
def function_repr(self):
return f'name={self.name}'
def add_repr(module):
module_name = module.__class__.__name__
if "Function" in module_name:
module.extra_repr = partial(function_repr,module)
# 본래 있던 함수 내에서 내용이 있다면, 함수 호출
returned_module = model.apply(add_repr)
model_repr = repr(model)
>>> from functools import partial
>>> class Dog:
def __init__(self, name):
self.name = name
>>> d = Dog('Fido')
>>> e = Dog('Buddy')
>>> def bark(self): # normal function
print('Woof! %s is barking' % self.name)
>>> e.aaa = partial(bark, e) # pre-bound and stored in the instance
>>> e.aaa() # access like a normal method
Woof! Buddy is barking
마지막 문제.. 어떻게 ?? → 해결
def hook(module, input, output):
output = input[0] @ module.W + module.b
return output
hook을 이용해서 input과 output을 조정한다.
과제 2번 - Custom Dataset 및 Custom DataLoader 생성
Data Set 관련 모듈
-
torch.utils.data:
데이터셋의 표준을 정의하고 데이터셋을 불러오고 자르고 섞는데 쓰는 도구들이 들어있는 모듈
파이토치 모델을 학습시키기 위한 데이터셋의 표준을 torch.utils.data.Dataset에 정의 -
torchvision.dataset:
torch.utils.data.Dataset을 상속하는 이미지 데이터셋의 모음
MNIST나 CIFAR-10과 같은 데이터셋을 제공해줍니다. -
torchtext.dataset:
torch.utils.data.Dataset을 상속하는 텍스트 데이터셋의 모음
기본적으로 IMDb나 AG_NEWS와 같은 데이터셋을 제공해줍니다. -
torchvision.transforms:
이미지 데이터셋에 쓸 수 있는 여러 가지 변환 필터를 담고 있는 모듈 -
torchvision.utils: 이미지 데이터를 저장하고 시각화하기 위한 도구가 들어있는 모듈
Dataset의 기본 구성 요소
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self,):
pass
#일반적으로 해당 메서드에서는 데이터의 위치나 파일명과 같은 초기화 작업을 위해 동작합니다.
#일반적으로 CSV파일이나 XML파일과 같은 데이터를 이때 불러옵니다.
#이렇게 함으로써 모든 데이터를 메모리에 로드하지 않고 효율적으로 사용할 수 있습니다.
#여기에 이미지를 처리할 transforms들을 Compose해서 정의해둡니다.
def __len__(self):
pass
#해당 메서드는 Dataset의 최대 요소 수를 반환하는데 사용됩니다.
#해당 메서드를 통해서 현재 불러오는 데이터의 인덱스가 적절한 범위 안에 있는지 확인 가능
def __getitem__(self, idx):
pass
#해당 메서드는 데이터셋의 idx번째 데이터를 반환하는데 사용됩니다.
#일반적으로 원본 데이터를 가져와서 전처리하고 데이터 증강하는 부분이 모두 여기에서 진행됨.
#이는 이후 transform 하는 방법들에 대해서 간단히 알려드리겠습니다.
데이터 셋을 불러온 후, 어떻게 랜덤하게 pick할까?
→ self.np.random.choice(self.X.shape[0], 10)
→ self.X[torch.randint(10, (10,))]
간단하게 생각해도 될 문제였다. index값을 랜덤하게 주면 되는 것을..
class IrisDataset(Dataset):
def __init__(self):
iris = load_iris()
...
pass
def __len__(self):
len_dataset = None
#len_dataset = len(self.X[np.random.choice(self.X.shape[0], 10)])
len_dataset = len(self.X[torch.randint(10, (10,))])
pass
return len_dataset
def __getitem__(self, idx):
...
pass
return torch.tensor(X), y
Data Loader
- Data의 Batch를 생성해주는 클래스
- 학습직전의 Data를 책임
- Tensor로 변환 + Batch 처리가 메인
Data Loader를 통해 데이터 셋을 불러준 후, 데이터의 인자를 뽑아주려면?
Data Loader의 parameter 값에 따라, 데이터를 조정할 수 있다.
→ next(iter(DataLoader(dataset_iris)))
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
next(iter(DataLoader(dataset_iris)))
-> [tensor([[5.1000, 3.5000, 1.4000, 0.2000]], dtype=torch.float64), tensor([0])]
next(iter(DataLoader(dataset_iris, batch_size=4)))
-> [tensor([[5.1000, 3.5000, 1.4000, 0.2000],
[4.9000, 3.0000, 1.4000, 0.2000],
[4.7000, 3.2000, 1.3000, 0.2000],
[4.6000, 3.1000, 1.5000, 0.2000]], dtype=torch.float64), tensor([0, 0, 0, 0])]
next(iter(DataLoader(dataset_iris, shuffle=True, batch_size=4)))
-> [tensor([[5.1000, 3.5000, 1.4000, 0.2000],
[4.7000, 3.2000, 1.3000, 0.2000],
[4.6000, 3.1000, 1.5000, 0.2000],
[4.6000, 3.4000, 1.4000, 0.3000]], dtype=torch.float64), tensor([0, 0, 0, 0])]
num_workers
- 데이터를 불러올 때 사용하는 서브 프로세스의 개수
-
무조건적으로 높인다고 좋지 않다.
dataset_big_random = RandomDataset(tot_len=5000)
dataset_big_random = RandomDataset(tot_len=10000)
collate_fn
- 보통 map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 기능입니다.
- zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 많이 사용합니다.
-
((피처1, 라벨1) (피처2, 라벨2))와 같은 배치 단위 데이터가 ((피처1, 피처2), (라벨1, 라벨2))와 같이 바뀝니다
Example Dataset 이 주어질 때, 다음과 같다.
class ExampleDataset(Dataset):
def __init__(self, num):
self.num = num
def __len__(self):
return self.num
def __getitem__(self, idx):
return {"X":torch.tensor([idx] * (idx+1), dtype=torch.float32),
"y": torch.tensor(idx, dtype=torch.float32)}
dataset_example = ExampleDataset(10)
"""
tensor([[0., 0.],
[1., 1.]]) tensor([0., 1.])
tensor([[2., 2., 2., 0.],
[3., 3., 3., 3.]]) tensor([2., 3.])
tensor([[4., 4., 4., 4., 4., 0.],
[5., 5., 5., 5., 5., 5.]]) tensor([4., 5.])
tensor([[6., 6., 6., 6., 6., 6., 6., 0.],
[7., 7., 7., 7., 7., 7., 7., 7.]]) tensor([6., 7.])
tensor([[8., 8., 8., 8., 8., 8., 8., 8., 8., 0.],
[9., 9., 9., 9., 9., 9., 9., 9., 9., 9.]]) tensor([8., 9.])
"""
collate_fn을 이용해서 다음과 같이 만들기..? batch_size == 2 일 때, 어떤 방식으로 생각을 해야할까?
짜맞추기..? → 정확히 뭘 모르는지 몰라서 그런 것 같다. 여기서 몰랐던 점은, “X”, “y”가 dict 값으로 온다는 점이다. 여기서 계속 막혔던 것 같다. 하나씩 모르는게 뭔지 찾아가자.
def my_collate_fn(samples):
collate_X = []
collate_y = []
######################################TODO######################################
for idx, dict_sample in enumerate(samples):
p1d = (0,1)
collate_X.append(dict_sample["X"])
collate_y.append(dict_sample["y"]) # "X", "y" 에 각각 쌓아준다.
if idx % 2 == 0:
re = F.pad(collate_X[0], p1d, 'constant', 0)
# 홀수번째일 때, "X"에 0을 Padding 추가
collate_X.pop()
collate_X.append(re)
pass
################################################################################
return {'X': torch.stack(collate_X),
'y': torch.stack(collate_y)}
3. 피어세션 정리
- 강의 요약
- 내용: 모델 불러오기 & Monitoring tools for PyTorch
-
필수 과제 2 공유
-
알고리즘 테스트 코드 공유
최소 절대값
-
질문
과제2 -> 문자열이 뭘 뜻하는가? : dict 과제1 -> repr() & extra_repr() 모듈 자체를 생성해주는 것인가? 원래있던 것인가? : default로 있던 것
4. 학습 회고
-
과제1를 이제 끝내고 과제2를 새로 시작하면서 아직 부족함이 많이 느껴졌다.
가장 간단한 torch의 랜덤을 뽑는 일이나 dict를 이용해서 함수를 만드는 것에 자꾸 어려움을 느꼈다.
기본이 아직 문제라는게 많이 느껴졌고, pytorch를 이용한 튜토리얼과 내가 어려워하는 부분을 기록하고 다시 스스로 만들어보는 시간을 가져야겠다.
이전보다 좀 더 나아진 점은 영어 도큐먼트를 읽기 편해졌고, 조금 더 인내심 있게 모르는 것을 찾고 기록하는 습관이 생겼다는 점이다. 아직 부족한게 많지만 하나씩 고쳐 나가는게 있긴 한 것 같다.
그리고.. 운동을 너무 안하게 된다는 안좋은 점도.. 생겼다 ㅠㅠ -
마스터 클래스
- MLOps에 대해서 알게 되었다. 알고리즘 개발이 아닌 주변 에코 시스템을 좀 더 주의깊게 보고
어떻게 미래 방향을 잡아야할 지 다시 생각해보게 되는 계기가 되었다.
문제 정의 → 데이터 정의, 베이스라인 설립, 라벨링, → 모델링 → deploy
머신 러닝 코드보다는 데이터, feature, 서빙 등이 산업에서 훨씬 좋다.

어떻게 하면 ‘자동화’하여 모델에 피딩해줄 수 있을까?
-> Linux, Docker, DB, Cloud
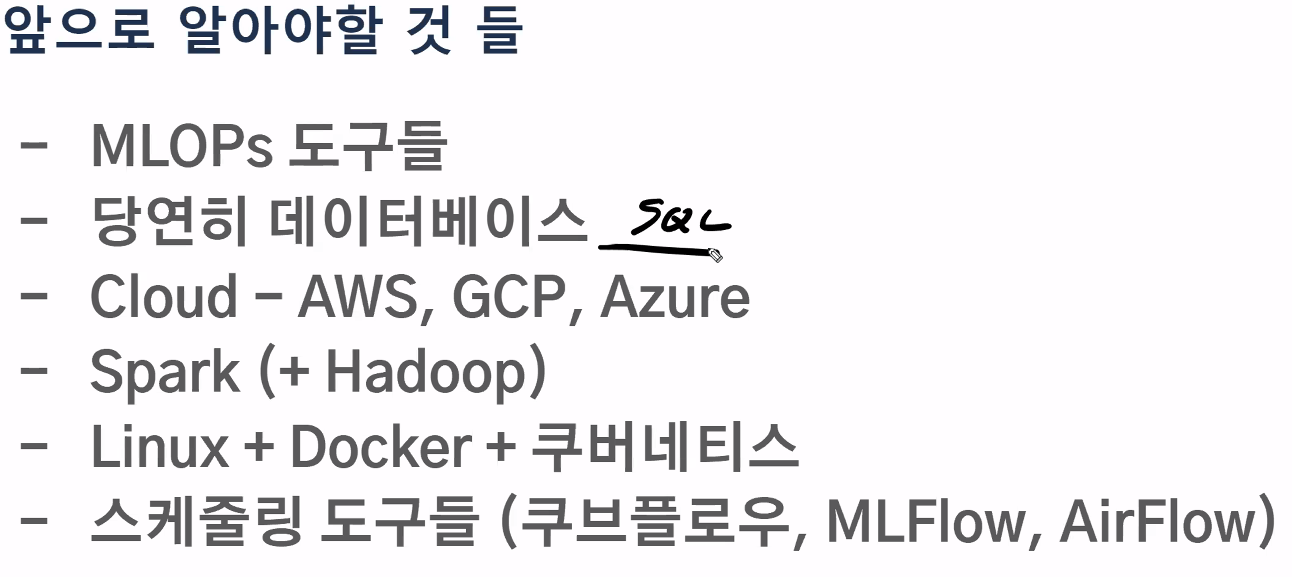

알고리즘이 아닌 앞뒤에서 에코시스템을 파악하자. ( 데이터, 서빙 )

AutoML ?
어떻게 해 나가야할까?
문제를 정의하고 직접 해결하는 경험! kaggle 같은 경험을 통해 직접 문제를 해결하는 경험을 가지자.→ 문서화 시키고 영어로 커뮤니티에 직접 공유