
[네이버 부스트 캠프] AI-Tech-re - week3(2)
학습기록 - 12
오늘 한 일
- 우선순위 큐 알고리즘 정리
- 파이토치 강의 정리 ( 1, 2, 3)
- 필수 과제 1 마무리
- 피어) 파이토치 강의 요약 발표 & 알고리즘 - 최소힙 & 필수 과제 풀이 & 질문(Lazy Linear)
1. 강의 복습 내용
강의 1,2
데이터 학습 방법 & 데이터 전처리 방법
AutoGrad & optimizer
어떠한 프로세스로 구현을 해야할까?
-
Layer = Block 처럼 쌓아서 만드는 것이다.
Layer를 학습하고 그 손실 값 (결과) 를 이용해서 BackPropa를 통해 학습한다.
Layer를 만들고, 그 위에 Layer를 만들어서 블록화시키는 것.
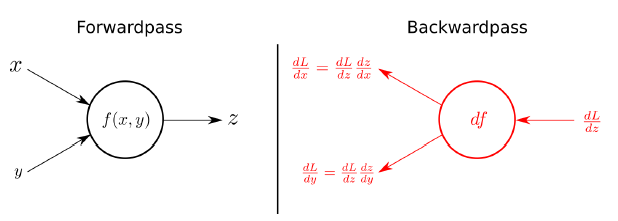
-
nn.Module
Forward(), Backward()

-
nn.Parameter
- nn.Module 내에서 Attribute 될 때, required_grad = True 를 통해 Autograd를 하게 된다.
-
Tensor를 이용해서 파라 미터를 표현할 경우, required_grad가 없어서 표현이 안된다.
Linear
class MyLiner(nn.Module): def __init__(self, in_features, out_features, bias=True): super().__init__() self.in_features = in_features # 입력 개수 (shape) self.out_features = out_features # 출력 개수 (shape) self.weights = nn.Parameter(torch.randn(in_features, out_features)) self.bias = nn.Parameter(torch.randn(out_features)) # Tensor 일 경우, 미분 불가능한 값이 된다. def forward(self, x : Tensor): return x @ self.weights + self.bias # Xw + b (y hat)
-
Backward
이전 gradient (w, b) 값을 초기화 해준다.
→ y hat 생성하고 loss를 만든다.
→ loss에 대한 미분 수행 ( Autograd ) (역전파 알고리즘)
→ 미분해서 나온 파라미터 값 업데이트
-
linear Regression
import torch from torch.autograd import Variable class LinearRegression(torch.nn.Module): def __init__(self, inputSize, outputSize): super(LinearRegression, self).__init__() self.linear = torch.nn.Linear(inputSize, outputSize) def forward(self, x): out = self.linear(x) return out inputDim = 1 # takes variable 'x' outputDim = 1 # takes variable 'y' learningRate = 0.01 epochs = 100 model = LinearRegression(inputDim, outputDim) # 초기 모델 설정 ##### For GPU ####### if torch.cuda.is_available(): model.cuda() # 손실함수 criterion = torch.nn.MSELoss() # SGD Gradient optimizer = torch.optim.SGD(model.parameters(), lr=learningRate) -
backprop
for epoch in range(epochs): # Clear gradient buffers because we don't want any gradient from previous epoch to carry forward, dont want to cummulate gradients optimizer.zero_grad() # 이전의 grad 초기화 # get output from the model, given the inputs outputs = model(inputs) # y hat # get loss for the predicted output loss = criterion(outputs, labels) # loss print(loss) # get gradients w.r.t to parameters loss.backward() # loss 미분 ( 모든 웨이트 값 생성 ) # update parameters optimizer.step() # weight 값 업데이트 -
실제값과 트레이닝된 모델의 예측값 비교 (검사 영역)
with torch.no_grad(): # we don't need gradients in the testing phase if torch.cuda.is_available(): predicted = model(Variable(torch.from_numpy(x_train).cuda())).cpu().data.numpy() # 학습한 데이터에 xtrain을 넣었을 때 예측값(gpu) else: predicted = model(Variable(torch.from_numpy(x_train))).data.numpy() print(predicted) print(y_train) -
logistic Regression
linear Regerssion과 다르게 sigmoid, backward, optimize를 실제로 구현해서 모듈화함. f
class LR(nn.Module): def __init__(self, dim, lr=torch.scalar_tensor(0.01)): super(LR, self).__init__() # intialize parameters self.w = torch.zeros(dim, 1, dtype=torch.float).to(device) self.b = torch.scalar_tensor(0).to(device) self.grads = {"dw": torch.zeros(dim, 1, dtype=torch.float).to(device), "db": torch.scalar_tensor(0).to(device)} self.lr = lr.to(device) def forward(self, x): ## compute forward z = torch.mm(self.w.T, x) + self.b a = self.sigmoid(z) return a def sigmoid(self, z): return 1/(1 + torch.exp(-z)) def backward(self, x, yhat, y): ## compute backward self.grads["dw"] = (1/x.shape[1]) * torch.mm(x, (yhat - y).T) self.grads["db"] = (1/x.shape[1]) * torch.sum(yhat - y) def optimize(self): ## optimization step self.w = self.w - self.lr * self.grads["dw"] self.b = self.b - self.lr * self.grads["db"] -
Training
데이터(이미지)의 shape을 맞추고, data 학습## hyperparams costs = [] dim = x_flatten.shape[0] learning_rate = torch.scalar_tensor(0.0001).to(device) num_iterations = 100 lrmodel = LR(dim, learning_rate) lrmodel.to(device) ## transform the data def transform_data(x, y): x_flatten = x.T y = y.unsqueeze(0) return x_flatten, y ## training the model for i in range(num_iterations): x, y = next(iter(train_dataset)) test_x, test_y = next(iter(test_dataset)) x, y = transform_data(x, y) test_x, test_y = transform_data(test_x, test_y) # forward yhat = lrmodel.forward(x.to(device)) cost = loss(yhat.data.cpu(), y) train_pred = predict(yhat, y) # backward lrmodel.backward(x.to(device), yhat.to(device), y.to(device)) lrmodel.optimize() ## test yhat_test = lrmodel.forward(test_x.to(device)) test_pred = predict(yhat_test, test_y) if i % 10 == 0: costs.append(cost) if i % 10 == 0: print("Cost after iteration {}: {} | Train Acc: {} | Test Acc: {}".format(i, cost, train_pred, test_pred))
-
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
필수 과제 - Custom Model 제작
-
ValueError 처리 파트 Error를 직접 일으키기 위해서는 ? raise Value Error
Error 사용법 : try ~ except 문 사용
Parameter - AutoGrad -
Parameter 파트 변화도 계산할 때, 계산한 변화도는 .grad에 저장
변화도를 계산하는 함수가 .grad_fn
Tensor가 아닌 Parameter를 이용하는 이유? - parameter는 미분을 할 수 있는 속성을 가지고 있다.https://tutorials.pytorch.kr/beginner/blitz/autograd_tutorial.html
Tensor vs Parameter vs Buffer

-
named_children vs named_modules 파트 modules는 전체 모듈들을 다 알려준다. children은 현재 가장 큰 모듈의 child를 다 알려준다.
-
extra_repr module의 설명을 덧붙여 주는 코드! 메소드를 직접 구현하라!
-
docstring 협업 또는 코드 구현 시, 설명을 반드시 쓰자. https://en.wikipedia.org/wiki/Docstring
-
parameter, buffer
각자의 메소드를 이용한 정보 구하기
module.parameters(), module.named_parameters(), module.get_parameter()
module.buffers(), module.named_buffers(), module.get_buffer() -
hook
module을 만들어서 사용할 때, 자신의 custom 코드를 package 중간에 실행할 수 있도록 미리 만들어 놓은 인터페이스
-
module → model.resgister_forward_hook(hook)
hook method가 있을 때, model의 forward 이후에 수행할 수 있게 한다.
forward의 앞에eh 위치시킬 수 있다. (model.resgister_pre_forward_hook)
input, output이 아닌 W의 Gradient를 구하기 위해서는 register_hook(grad)
hook의 인터페이스와 함수를 잘 파악해서 선택하기. -
tensor → tensor : torch.tensor(tuple)
tensor → tuple : (tensor, tensor) -
기능 :
- gradient값의 변화를 시각화
- gradient값이 특정 임계값을 넘으면 gradient exploding 경고 알림
- 특정 tensor의 gradient값이 너무 커지거나 작아지는 현상이 관측되면
해당 tensor 한정으로 gradient clipping
-
-
torch.gather(input(tensor), dim, index(tensor))
""" 가장 헷갈리는 부분이니까 지금 딱 정해놓자. out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0 out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1 out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2 그림으로 생각하지 말고, 저 수식으로 이해하자. dim에 따라, index 값에 위치를 넣는 것이다. 먼저 index값을 보고 (index[i][j]), index의 위치를 본다. (i, j), dim에 따라 위치 값을 찾으면, dim == 0, 찾는 위치는 (index[i][j], j) dim == 1, 찾는 위치는 (i, index[i][j]) """ import torch A = torch.Tensor([[1, 2], [3, 4]]) # dim = 0 일 때, # index 값은 0 일 때, index의 위치는 (0,0) 이다. 따라서 찾는 input[0][0] # index 값은 1 일 때, index의 위치는 (0,1) 이다. 따라서 찾는 input[1][1] output = A.gather(0,torch.tensor([[0, 1]])).squeeze() # dim = 1 일 때, # index 값은 0 일 때, index의 위치는 (0,0) 이다. 따라서 찾는 input[0][0] # index 값은 1 일 때, index의 위치는 (1,0) 이다. 따라서 찾는 input[1][1] output = A.gather(1,torch.tensor([[0],[1]])).squeeze() print(output)
3. 피어세션 정리
- 강의 요약
- 내용: Pytorch AutoGrad & Dataset & DataLoader
- 필수 과제 1 공유
- 퀴즈
- 불 세개짜리 도전
- 알고리즘 테스트 코드 공유
- 최소 합
- 질문
- Linear vs LazyLinear
- gather(input(tensor), dim, index(tensor))
4. 학습 회고
-
오늘은 강의 자체가 과제와 연결된 느낌이라 과제 위주로 공부를 했다.
막히는 부분을 바로 기록했고, 끝까지 붙잡으면서 과제를 풀어나갔다.
어려웠지만 하나씩 알아가게 되는 걸 느꼈다.
그리고 부족했던 점인 documentation을 읽는 것을 꾸준히 하면서 익숙해져야겠다는 생각이 들었다.
어려워도 꾸준하면 바뀌겠지. -
마스터 클래스
Test에 대해서 새롭게 알게 됨. 책) refactoring for patterns
-
Unit Test
- 이게 왜 안되고? 이게 왜 될까?
- 사소한 실수가 쌓이는 경우 : 자동화된 테스트 케이스를 만들어 놓아야 한다.
- Test Case는 개발자가 무조건 할 수 있어야 한다.
- 이게 왜 안되고? 이게 왜 될까?
-
Testing Terminology
-
ATDD(고객) & TDD ( Test-driven development )
TDD는 개발자가 안할 수 없는 것이다.
-
TDD : RED → Green → Refactor
assert를 메소드에 넣어서 직접 테스트 해보기
-
-
느낀점
-
한번도 안해본 주제라 무슨 말인지 못알아들었는데, assert Test를 보고
이전 1주차 때 baseball Game이 생각났다. 그때 Test Case를 통해, 함수별
구성별로 모든 것을 테스트했던 기억이 있었다. 이게 개발자로서 필수적인 일인줄 몰랐다.
많이 궁금해졌고, 한번 해봐야겠다는 생각이 들었다.그리고.. 개발자로써 잘해야할게 많아졌다는 생각이 들었다.
여기 개발자의 길에 들어온 이상, 더 많이 공부해야겠다는 생각이 들었다.
-