
[네이버 부스트 캠프] AI-Tech-re - week2(5)
학습기록 - 10
오늘 한 일
- 필수 과제 MHA
- Generative 1, 2
- Computer Visualization
- Data Viz
1. 강의 복습 내용
Generative Models
생성 모델
-
분류 문제는 크게 Generative Model (Unsupervised) 과 Discriminative model (Supervised) 로 나눠진다.
-
Discriminative model의 경우, 우리가 이전에 했던 회귀 분석처럼 클래스를 나눠서 확률을 통해 분류를 한다.
-
Generative model의 경우, likelihood 나 사후확률 (posterior probability)를 사용해서 분류 경계선(decision boundary)를 만든다.
- 예제로 우리가 강아지 사진들이 있다고 가정한다면,
- Generative model은 Image를 Generation 한다. (Sampling)
- Generative model은 어떤 확률로 분류하는 explicit model을 포함한다. (단순한 생성은 implicit model)
- Unsupervised Representation learning, 어떤 특징을 잡아내는 Feature Learning을 한다.
그렇다면 그 p(x)를 어떻게 나타낼 것인가?
- RGB 모델의 경우, 한 픽셀을 나타내기 위한 Parameter의 개수는 (256 X 256 X 256 - 1) 로 나타낼 수 있다.
Binary Image의 경우 2^n - 1 개의 파라미터로 나타낼 수 있다. 그렇다면, 모든 경우가 independent하다면, 파라미터의 개수는 n개로 나타낼 수 있다. (state는 그대로)
-
-
Chain rule & Bayes’ rule & conditional independence 를 잘 활용해서, fully dependent model and fully independent model 사이에 좋은 모델을 만드는 것이 목표 ( Parameter 의 개수 줄이기 )
-
Conditional Independence - Markov Assumption
sequence에서 어떤 단어가 이전 모든 단어들의 영향을 받는다고 한다면, 만약 x1이 나올 확률이
p(x1)이라고 하면 그 다음 단어x2가 나올 확률은p(x2|x1)가 되고, x3가 나올 확률은p(x3|x1,x2)이다.x784가 나올 확률은
p(x784) = p(x784|x1,x2,x3,...,x783) = p(x1) X p(x2|x1) X p(x3|x1,x2,x3) ...가 된다. -> chain rulesequence에서 어떤 단어가 직전 단어에만 영향을 받고 (dependent) 나머지 단어들에 독립적(independent) 이라고 한다면,
If $x \perp y \mid z$, then $p(x \mid y, z)=p(x \mid z)$ 이와 같이 나타낼 수 있다. -> conditional independence여기서 sequence를 조절하면서 적당한 independent를 가지는 모델
-> Auto regressive model -
Auto regressive model (자기 회귀 모델)
특징 : 직전 뿐만 아니라 더 길게 잡아도 이 모델에 적용된다. 순서에 따라 성능 차이가 달라진다.
자기 회귀 모델은 이전에 있던 sequence가 Input이 되어서 output을 만들게 한다.
여기서 모델은 어떻게 conditional independent하게 할 것인가, 순번을 어떻게 먹일 것인가에 따라 성능이 달라진다.
-
NADE : Neural Autoregressive Density Estimator Autoregressive Model에서와 같이 i번째 pixel을 첫번째부터 (i-1)번째 픽셀을 dependent하게 한다. 이 픽셀들을 다 받아서 Neural Network의 방식을 따라 Sigmoid 함수를 넣어서 추출한다.
Neural Network 입장에서는 weight가 계속 커지게 된다.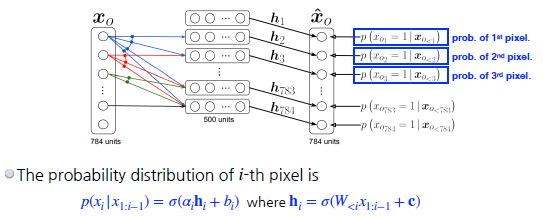
NADE는 Generation만을 하는 implicit model일 뿐만 아니라 확률분포를 계산할 수 있는 explicit model이다.

-
Pixel RNN
RNN을 통해 R,G,B를 만들어 내겠다.
ordering에 따라 pixel을 만들어내는 방법이 달라진다.
Generative Models - 2
- Latent Variable Models
Autoencoder은 generative model인가? 그렇지 않다. Variation Autoencoder가 generative model이 될 수 있다?
Variation Autoencoder
-
Variational inference(VI)
-
목적 ? Posterior distribution에 가장 잘 맞는 variational distribution을 최적화 하는 것
-
이러한 일련의 과정을 Variational Inference 라고 한다.
-
무언가를 잘 최적화하겠다? KL divergence를 이용해서 PD 와 VD를 줄여보겠다.
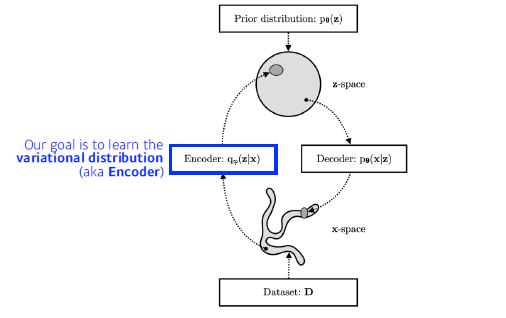
-
문제점 ?
PD가 존재하지 않는 상태에서 VD를 만들어 KL Divergence를 줄일 수가 없다. 따라서 일종의 ‘트릭’을 쓰는 것이 ELBO 다. ELBO (Evidence of Lower BOund) 를 활용해서 Variational Auto-Encoder를 학습하는 것이 Key-Idea다.아래의 식처럼 ELBO를 maximize 해줌으로써 상대적으로 KL-Divergence를 낮춰보이게끔 하는 것이다.
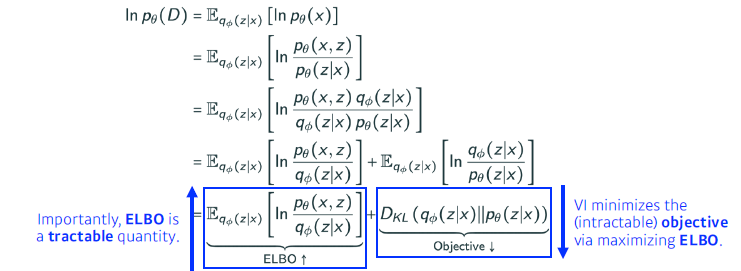
이번엔 ELBO를 나눠보면, 다음과 같이 나타낼 수 있다.
Reconstruction Term : 인코더를 통해 만들어진 latent space로 보냈다가 다시 디코더를 통해 돌아오는 Recontruction loss를 줄이는 것
Prior Fitting Term : Latent space에서의 분포와 사전 분포 사이의 같다(?)(거리)를 의미한다.엄밀한 의미에서 implicit model (Generative model)

GAN
-
Computer Visualization
-
Semantic Segmentation
- 어떤 이미지가 있을 때, 픽셀마다 분류하는 것
- 자율 주행에서 주로 이용
-
Fully Convolutional Network
- Dense layer를 없애고 싶은 것.
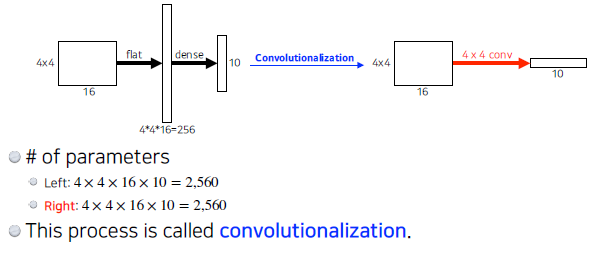
Parameter는 같은데 왜 하는 것일까? Input 이미지에 상관없이 단순히 분류가 아닌 heat map이 나올 수 있도록 한다.
- upsampling 방법 Deconvolution : Convolution의 역연산 Padding을 많이 줘서 할 수 있도록 한다.
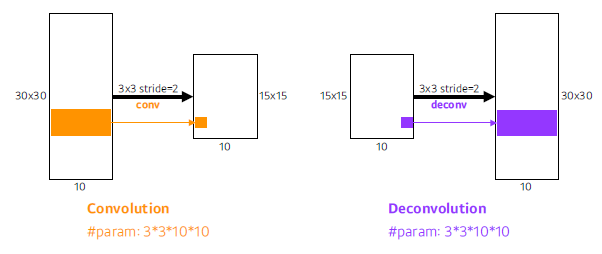
-
Detection
-
R-CNN : Bounding Box를 찾는 것 Image 안에서 바운드리를 친 다음에 각각 분류를 시작한다.
-
SPPNet : R-CNN은 Image안에서 2000개의 바운딩 박스를 뽑으면 비효율적.
Image 내에서 Convolution 으로 feature 생성 후 바운딩된 부분 Tensor을 뽑아내자
-
Fast R - CNN 이미지 내에서 feature map을 뽑아낸 뒤, 각 영역마다 ROI feature을 뽑는다. 그 이후 바운딩 박스를 분류함.
-
Faster R - CNN 바운딩 박스를 뽑는 것도 네트워크를 학습하자. -> Region Proposal Network
-
Region Proposal Network 어떤 영역안에 이 물체가 있을 것 같다? Template을 미리 고정
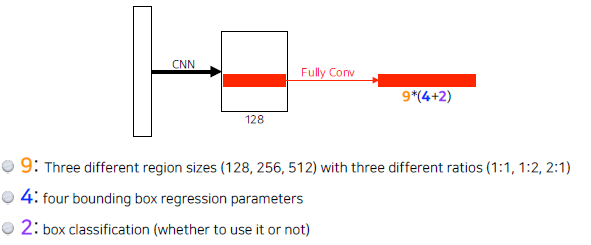
여기서도 fully conv 가 적용된다.
-
YOLO 바운딩 박스를 따로 뽑는 것이 아닌 한번에 다 뽑는다. 바운딩 + 클래스 찾기를 같이 한다.
-
2. 고민 내용, 결과 (과제 수행 과정, 결과물 정리)
-
필수 과제 : MHA
강의 따라 실습 진행, 다시 혼자 보면서 진행해봐야겠다.
코드에 대한 완벽한 이해는 아니었지만, 코드 실습을 통해 Self-attention에 대한 이해와 Multi Head attention에 대한 내용을 이해할 수 있었다.
3. 피어세션 정리
-
스페셜 피어세션 : 다른 팀들과의 피어세션 주제 공유를 통해 다른 방향도 생각해보게 되었다. (논문 정리, 코드 리뷰)
-
Generative Model : 이론 리뷰
-
팀 학습 회고
4. 학습 회고
-
오늘 같은 경우, 어려운 부분이 너무 많았다.
일단 넘어가면서 강의를 듣긴 했는데 나중에 자세하게 보는 일정이 필요한 것 같았다.
아무래도 이렇게해서는 계속 미뤄질 것 같다.
하루 일정은 하루 안에 끝내는 것을 목표로 해야할 것 같다. -
210816 Auto regerssive model ~ Variation Autoencoder 다시 학습