
[네이버 부스트 캠프] AI-Tech-re - week2(4) - Transformer
RNN에 이어서 Transformer에 대한 내용이다.
원본 링크 매우 많이 참고
원문 링크 참고
원본 논문 Attention is All you Need 참고
logit, softmax, Sigmoid 관련 설명 참고글
Transformer
문장의 Sequence가 있을 때, 단어가 끊기거나 생략되거나 한다면 ? 어떻게 해야할까? 라는 의문에서 시작되었다.
인코딩 이전에 linear 모델을 통과한 후에 나온 vector를 이용해서 인코딩을 시작한다.
📢모델의 핵심을 정리하자면,
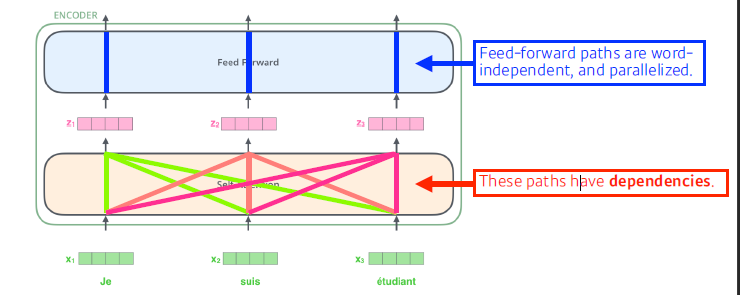
Mutil-head Self-Attention을 이용해서 Sequentail Computation을 줄이고,
많은 부분을 병렬철리가 가능하게 만들어서 더 많은 단어들 간 Dependecy를 모델링 합니다.
-
Overview of Architecture
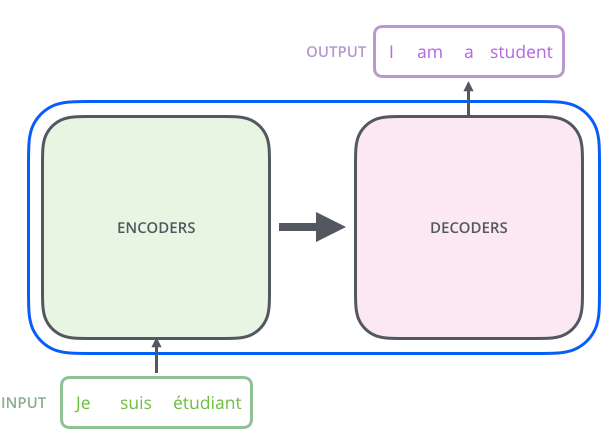
black box를 열기 전에, 전체적인 Architecture는 다음과 같습니다.

위의 TransFormer라는 box를 열어보게 되면, encoding, decoding부분들과 그 사이 connection이 존재합니다. 이미지에서 보듯이 하나의 문장이 Encoder를 통해 들어가서 decoder를 통해 번역되어 나오는 것을 볼 수 있습니다.
-
Sequence to Sequence Transformer
Sequence 하나당 n개의 단어 모두를 인코딩할 수 있다.
a. N개의 단어가 어떻게 인코더에서 처리?
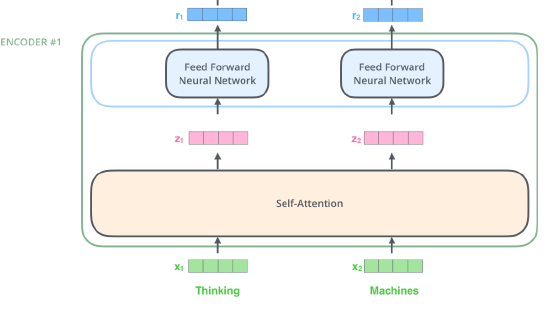
Encoder 내부를 좀 더 자세하게 보면 Self-Attention과 Feed Forward Neural Network라는 2개의 Sub layer를 가지고 있습니다.
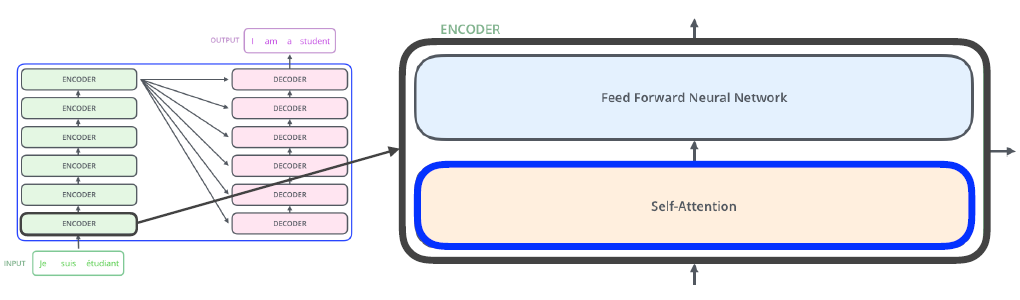
❗Self-attention : 3개의 단어에 대한 3개의 벡터 -> 3개의 벡터를 출력해준다.
여기서 self-attention은 나머지 단어들에 대해 dependencies가 존재한다.
ex) self-attention at high-level❗Feed forward Neural Network : self-attention에서 출력된 vector를 독립적으로 추출합니다.
❗Word Embedding
각 단어들을 Input에 이용하기 위해서 Embedding Vector로 만듭니다.
Embedding Algorithms 관련 링크
-
Encoding 과정
Self-Attention
“Thinking Machines”라는 Sentence가 Encoding 되는 과정입니다.
-
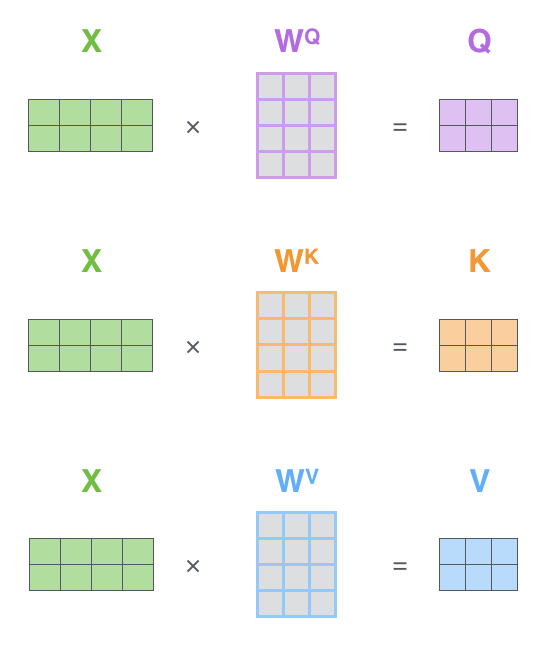
Self-Attention에서 해야할 첫 단계는 3개의 벡터를 만드는 일입니다. 각 3개의 학습 가능한 행렬들을 곱해서 만들어집니다.
여기서 알아두어야할 점은, 기존 입력 벡터들의 크기가 512(그림에서는 4)인 반면 새로운 벡터들의 크기는 64 (그림에서는 3) 이 됩니다. 그 이유는 후에 Multi-head Attention의 계산 복잡도를 맞추기 위해서 head의 개수만큼 dimension을 나눠줬기 때문입니다.
💡64 = 512 / 8 (head)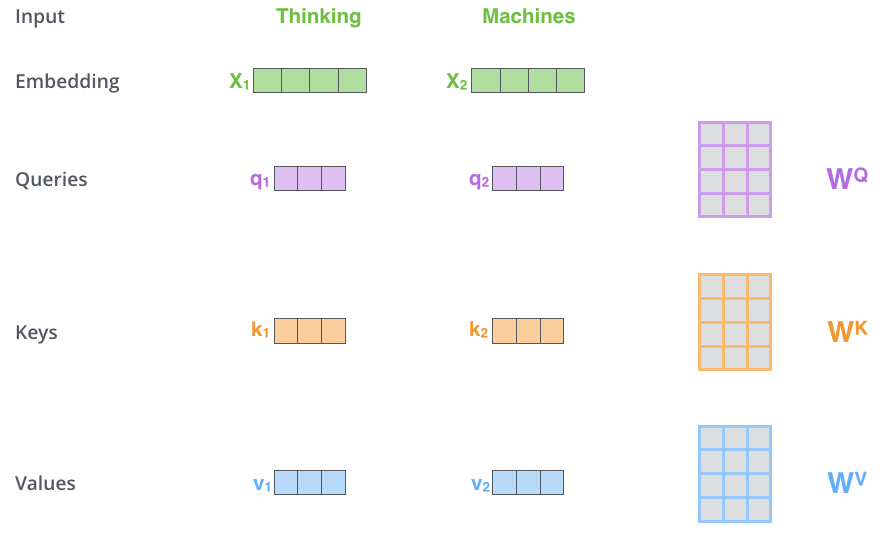
-
Embedding vector / Queries / Keys / Values 의 벡터들을 하나씩 생성해주고 Queries, Keys vector사이의 내적을 통해 Score vector를 만들어준다. (얼마나 관계 있는지)
💡내적을 할 떄는 현재 단어와 이전, 이후 key와의 내적을 통해서 만들어줍니다.
💡여기서 말하는 Queries, keys, values는 추상적인 개념!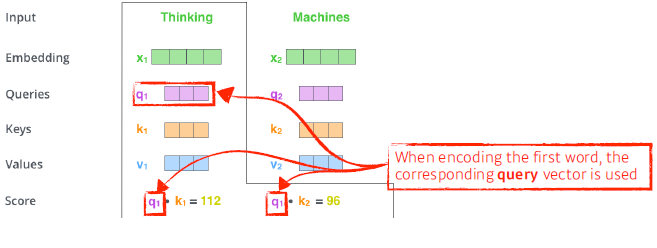
-
그 다음 Score를 Normalization (Key Vector의 dimension의 제곱근) 한 후, Softmax 함수를 통해 계산한 다음에 가지고 있는 Value vector에 곱해준다. (weighted Sum of the value vectors)
💡Normalization의 이유는 각 W의 dimension이 높아짐에 따라 각 요소별로 크기가 커지기에 불안정한 Gradient를 얻을 수 있습니다.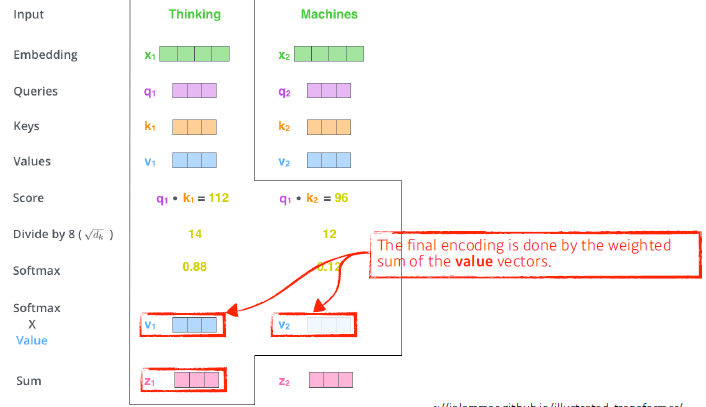
이 구조는 입력과 출력이 고정되어 있는 구조가 아니라, 입력에 어떤 다른 Sequence가 들어오면 출력이 계속 달라지게 된다.
즉, 표현력이 많아진다. -> 많은 computation(계산) 이 필요💡Key, Query, Value vector 각각 찾아내는 MLP가 존재한다.
위의 과정을 행렬 단위로, 다시 나타내면 다음과 같습니다.
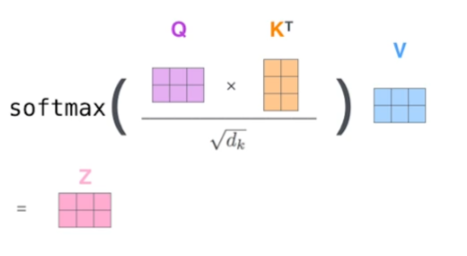
Multi Headed Attention (MHA)
하나의 Input에 위와 같은 Self-attention을 반복해서 N개의 Head를 만들게 되는 데, 이를 MHA라고 한다.
MHA를 하는 이유는
첫번째로, 모델이 다른 위치에서도 집중하는 능력을 향상시킵니다.
예제) “The animal didn’t cross the street because it was too tired”에서 it이 가리키는 것이 무엇을 의미하는 지 알아낼 때 유용합니다.
두번째로, Attention이 여러 개의 representation layer를 가질 수 있도록 해줍니다.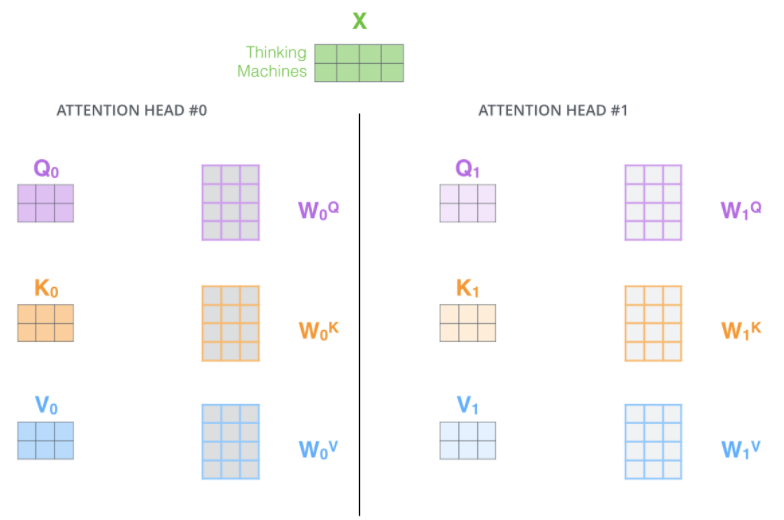
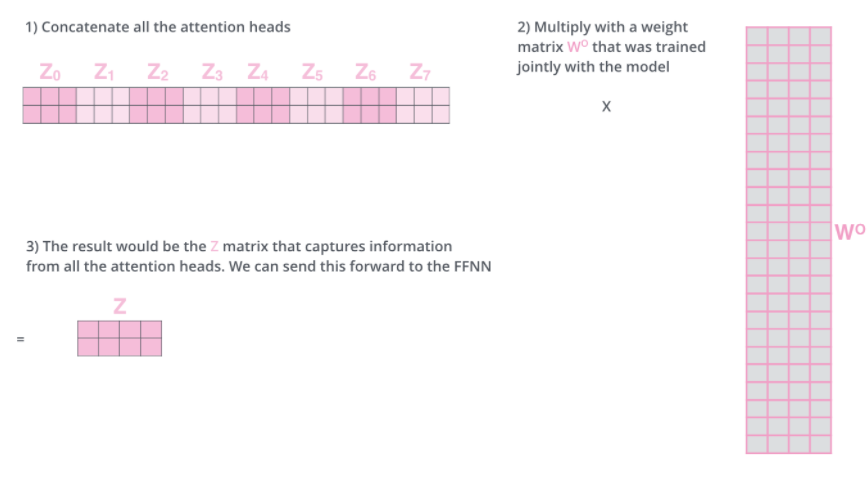
self-Attention 이후, 서로 다른 8개의 z행렬이 나오게 되는데, 이 행렬을 바로 feed-forward layer로 쓸 수 없습니다. 왜냐하면 한 위치에 대해 오직 한 개의 행렬만 Input으로 받기 때문입니다.
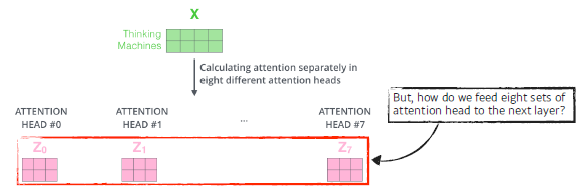
이러한 MHA를 통해 나온 Z 벡터들은 concatenating을 하고 W0라는 큰 가중치 벡터에 의해 output Z 생성하게 됩니다. (CNN의 마지막에 flatten, Concat하는 과정과 비슷)
Self-Attention과 MHA를 통과한 후, it이라는 단어를 encode할 때, 각각의 Attention들이 어떤 단어를 가리키는 지 보면, 다음과 같습니다.
첫번째 그림의 경우, it이 “The”, “animal” 과 “tire”, “-d”에 집중하는 것으로 보아, it의 representation에 포함할 수 있습니다.
두번쨰 그림의 경우, it이 위의 단어말고도 많은 단어를 representaiton에 포함시키는 것을 볼 수 있습니다.

지금까지의 모든 과정을 하나의 그림으로 나타내면, 다음과 같습니다.
여기서 알아야할 점은 첫번째 Attention에서 Embedding 과정이 있고 나머지는 Encoder를 통해 나온 z vector를 그대로 Input으로 합니다.
z vector의 size는 Encoder 과정을 거친 후, Input의 size와 같게 나오게 됩니다.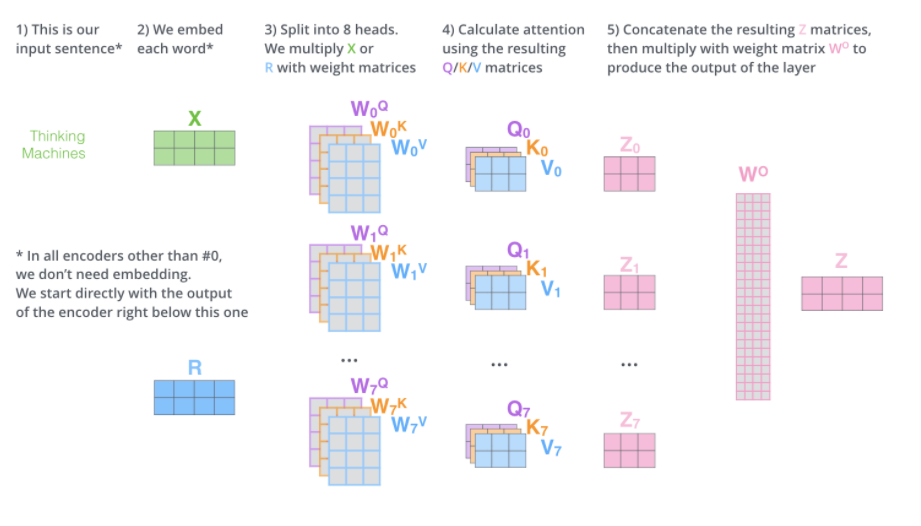
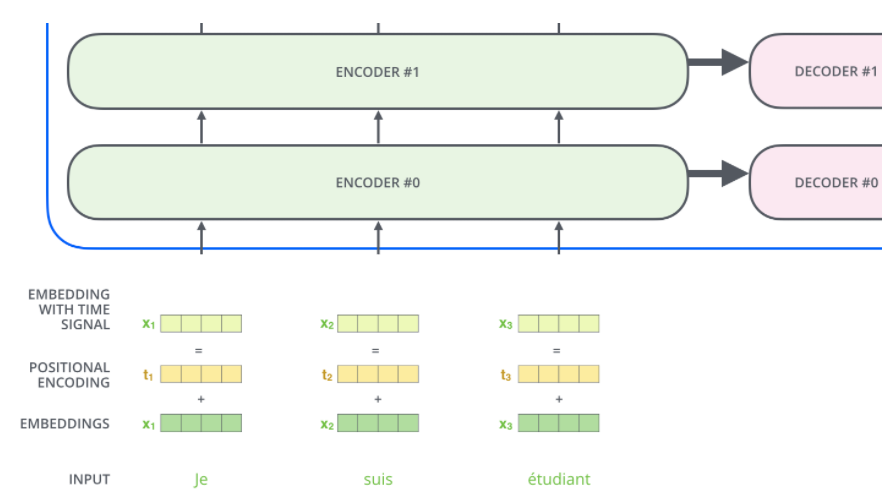
많은 정보를 담고 있지만, 위치에 대한 정보를 고려하지 않고 있습니다. -> Positional Encoding
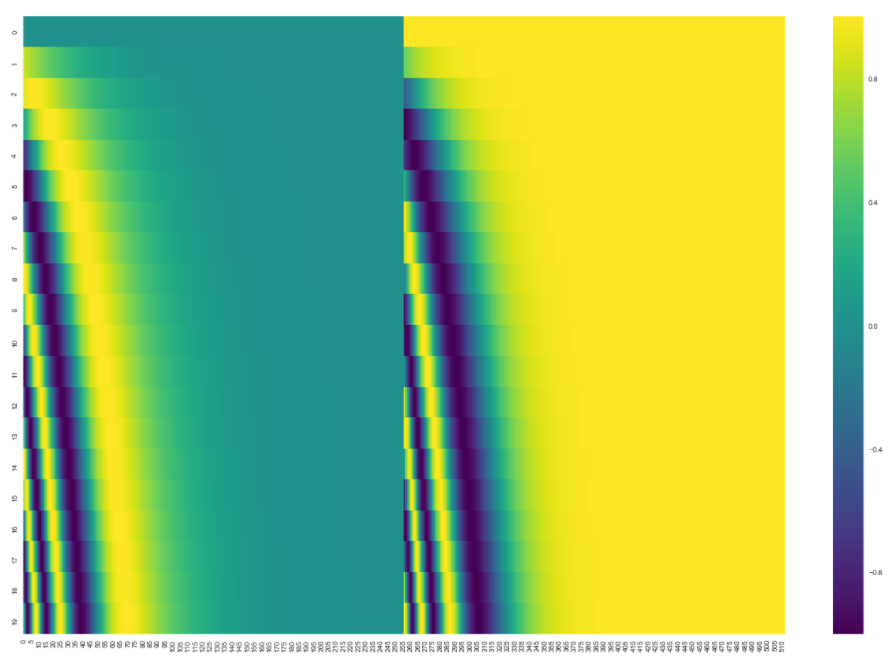
Positional Encoding
Positional Encoding은 모델에게 단어에 대한 순서의 정보를 주기 위해서 위치별로 특정 패턴을 따르는 벡터입니다.
아래 그림은 Embedding 크기가 4일 때 (실제로는 512) 예시입니다.
Sequence는 어떻게 들어오든 값이 encoding에 의해 달라질 수가 없다. (order에 independent)
어떤 단어가 어느 위치에 있는 지 중요하기에 넣어준다. (벡터값에 offset을 줌)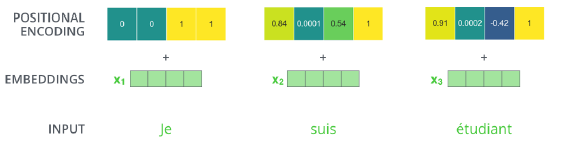
실제 Encoding Vector의 시각화
The Residuals
Encoder를 더 뜯어보면, 다음과 같은 구조로 되어 있습니다.
Self-Attention 이후, Feed Forward를 바로 진행하는 것이 아닌 Layer Normalization 과정을 한번 거치게 됩니다.
Layer Normalization에 관한 논문 링크
Sub layer에도 적용한다면 두번째 그림과 같이 구조를 시각화할 수 있습니다.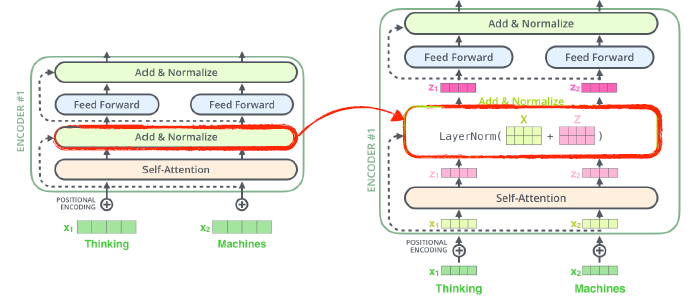
-
b. 인코더와 디코더 사이에 어떤 정보 주고 받음?
-
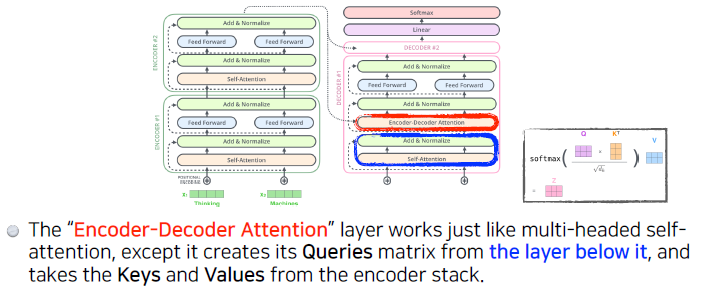
인코더에서 디코더로 어떤 정보를 주고 받는가?
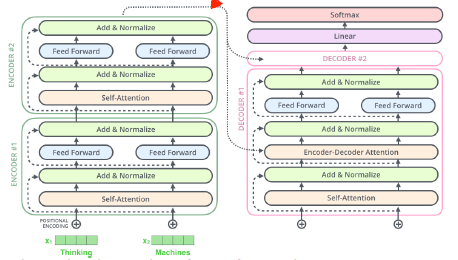
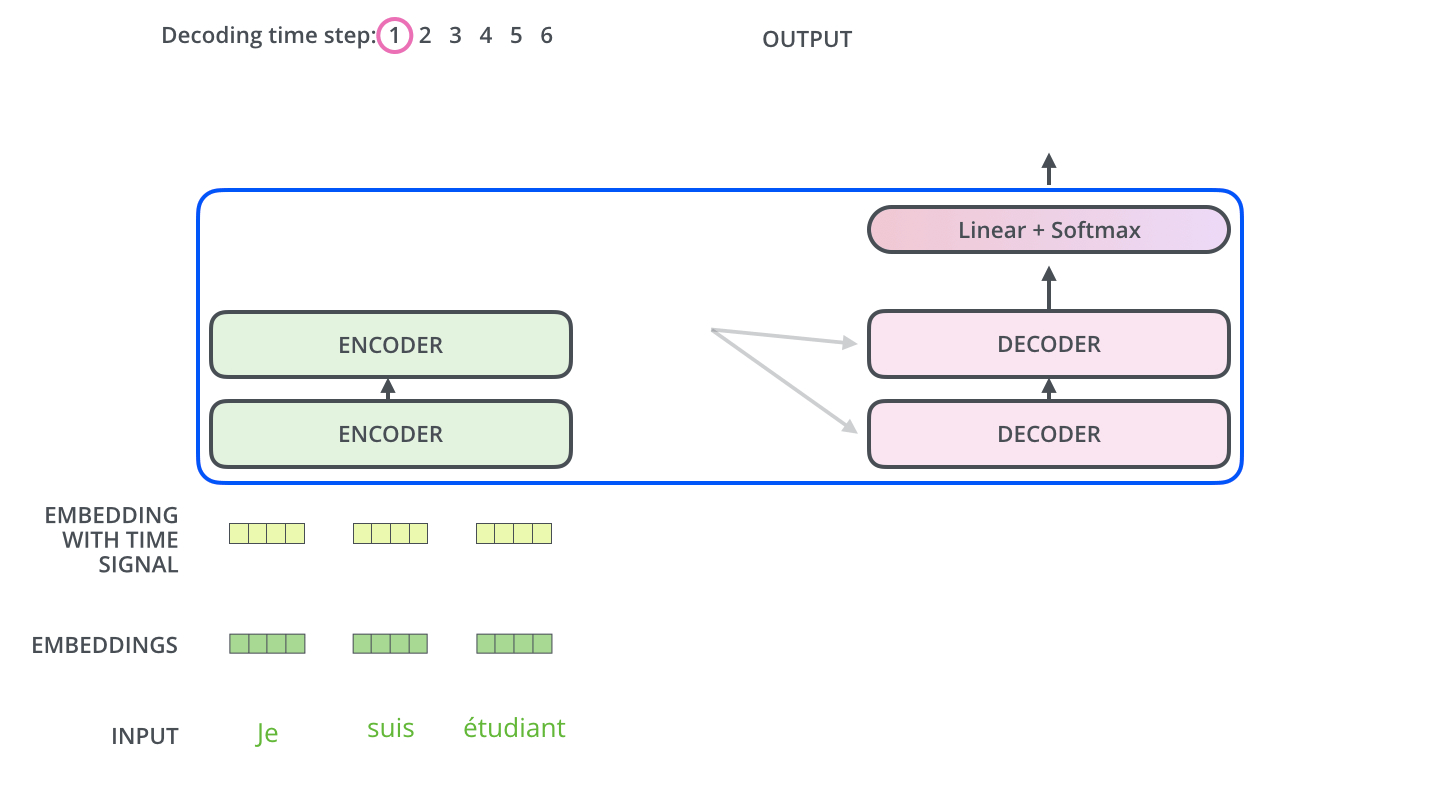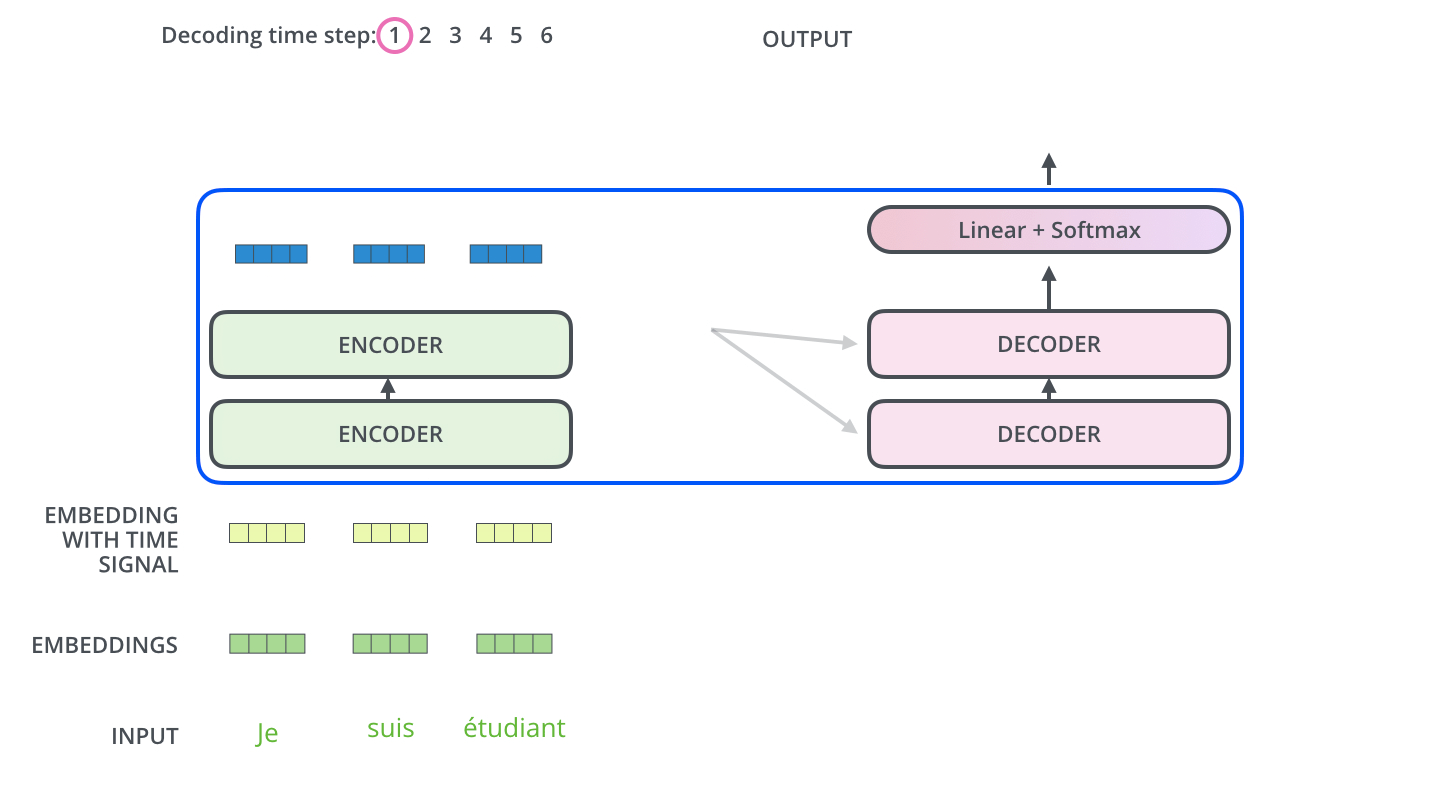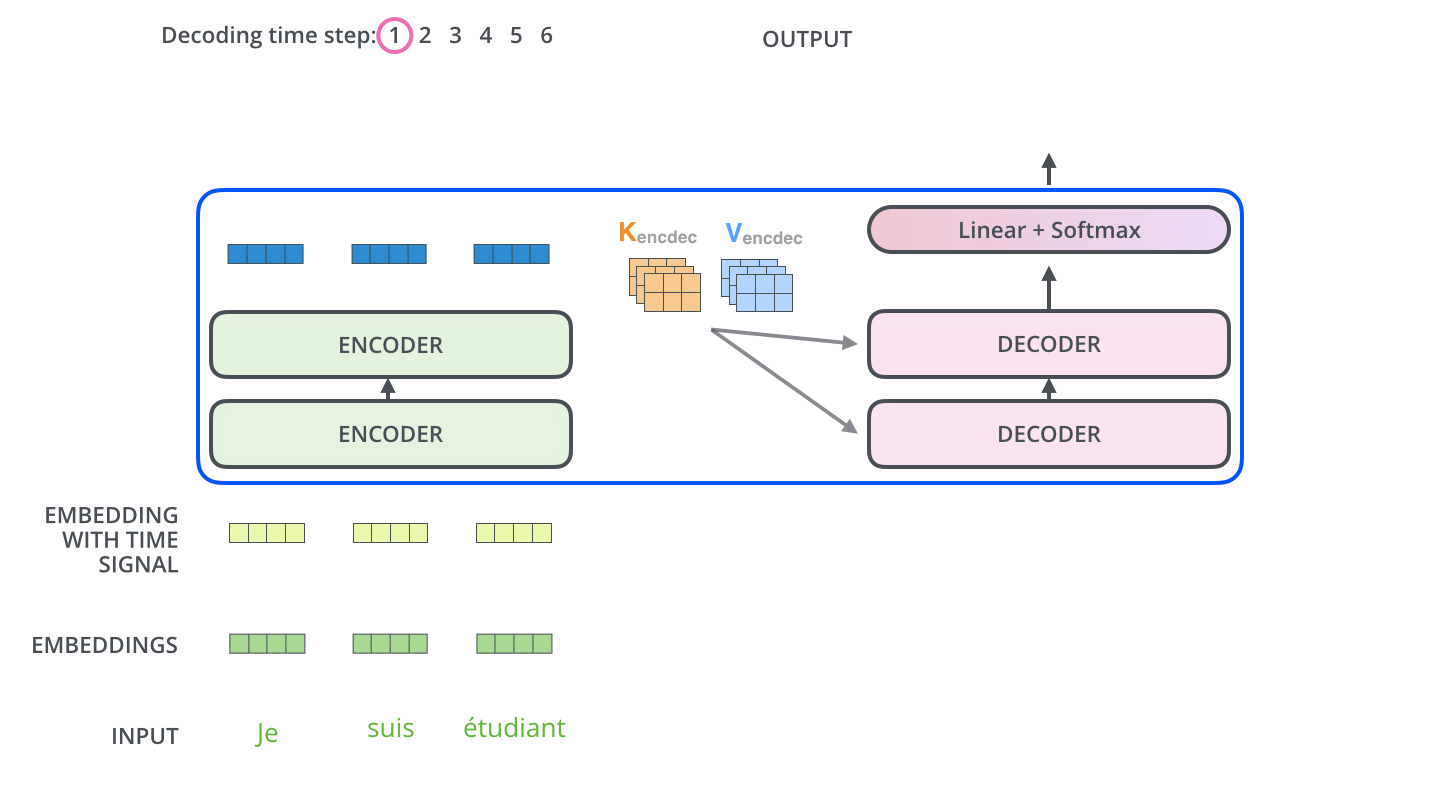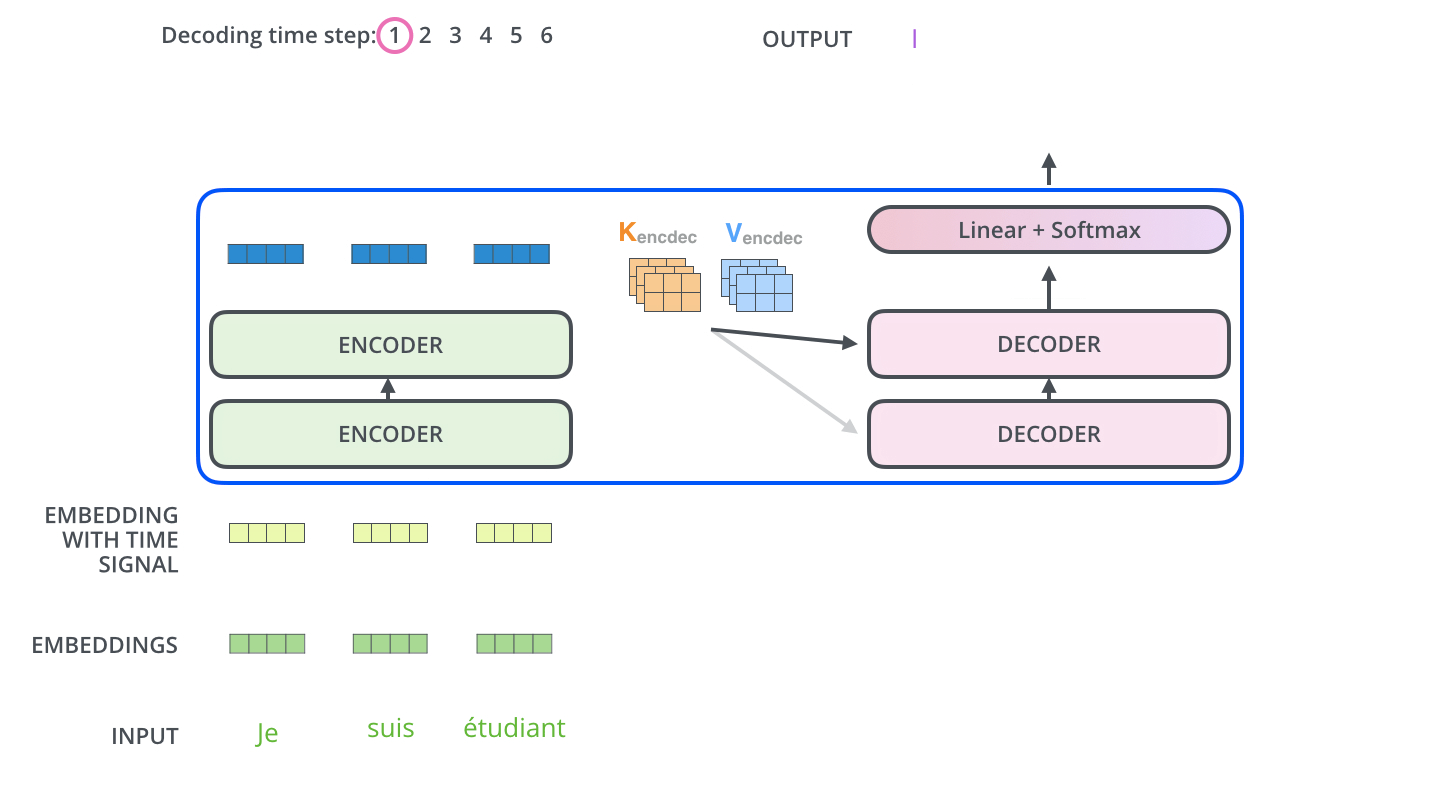
가장 윗단의 Encoder에서 출력되었던 vector는 attention 벡터들인 K와 V로 변형됩니다.
이 벡터들은 이제 각 decoder의 “encoder-decoder attention0 layer”에서 decoder 가 입력 vector에서 적절한 단어를 찾을 수 있도록 도와줍니다.
Key Vector 와 Value vector 값을 Decoder에 전달해서 previous output과 함께 output이 나오게 됩니다.Q : 디코더의 이전 레이어 hidden state
K : 인코더의 output state
V : 인코더의 output state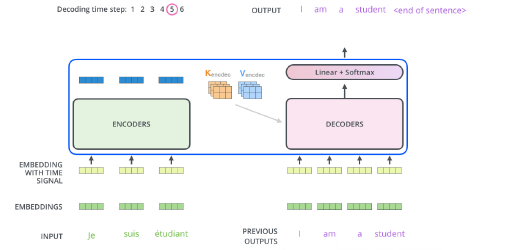
-
Self-attention layer & Encoder-Decoder Attention
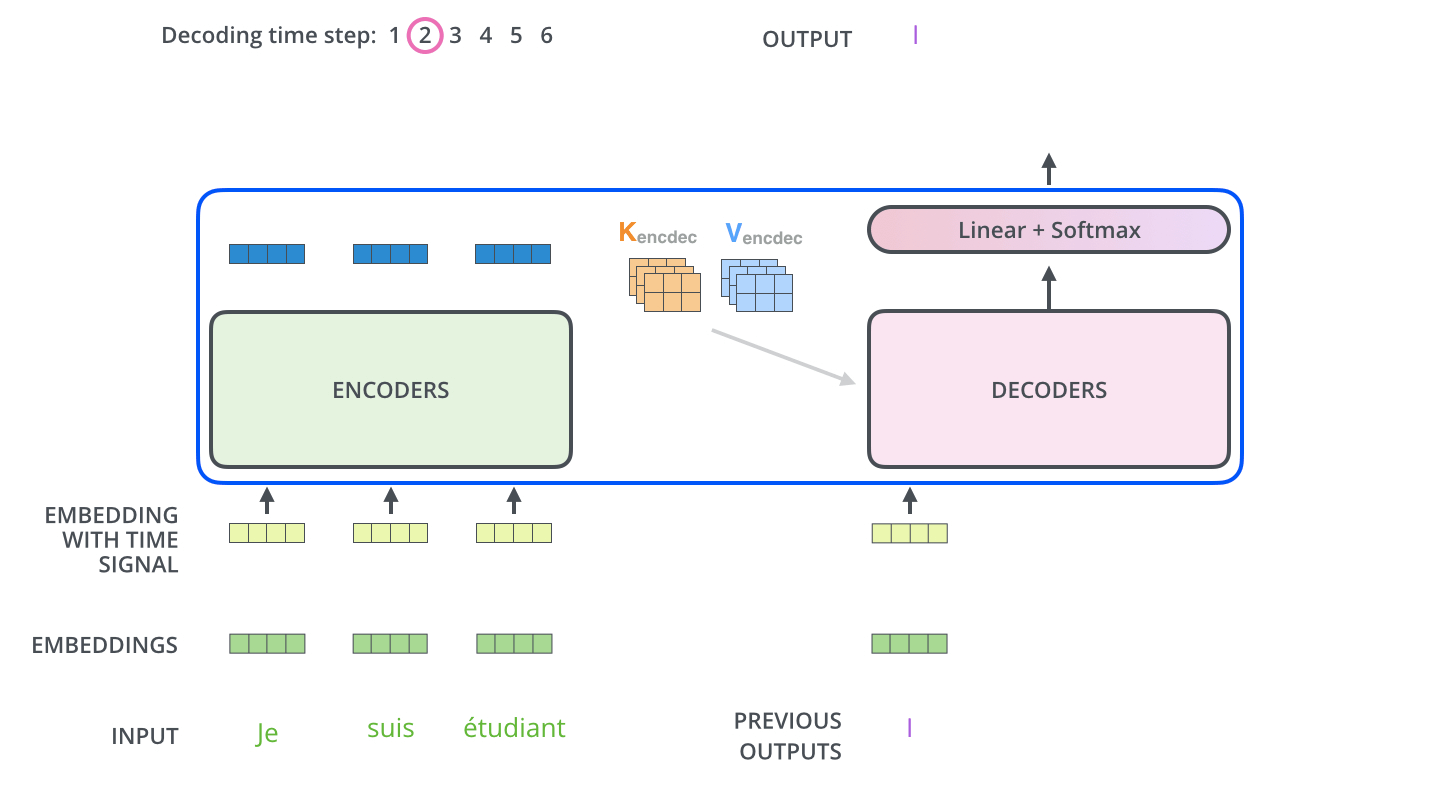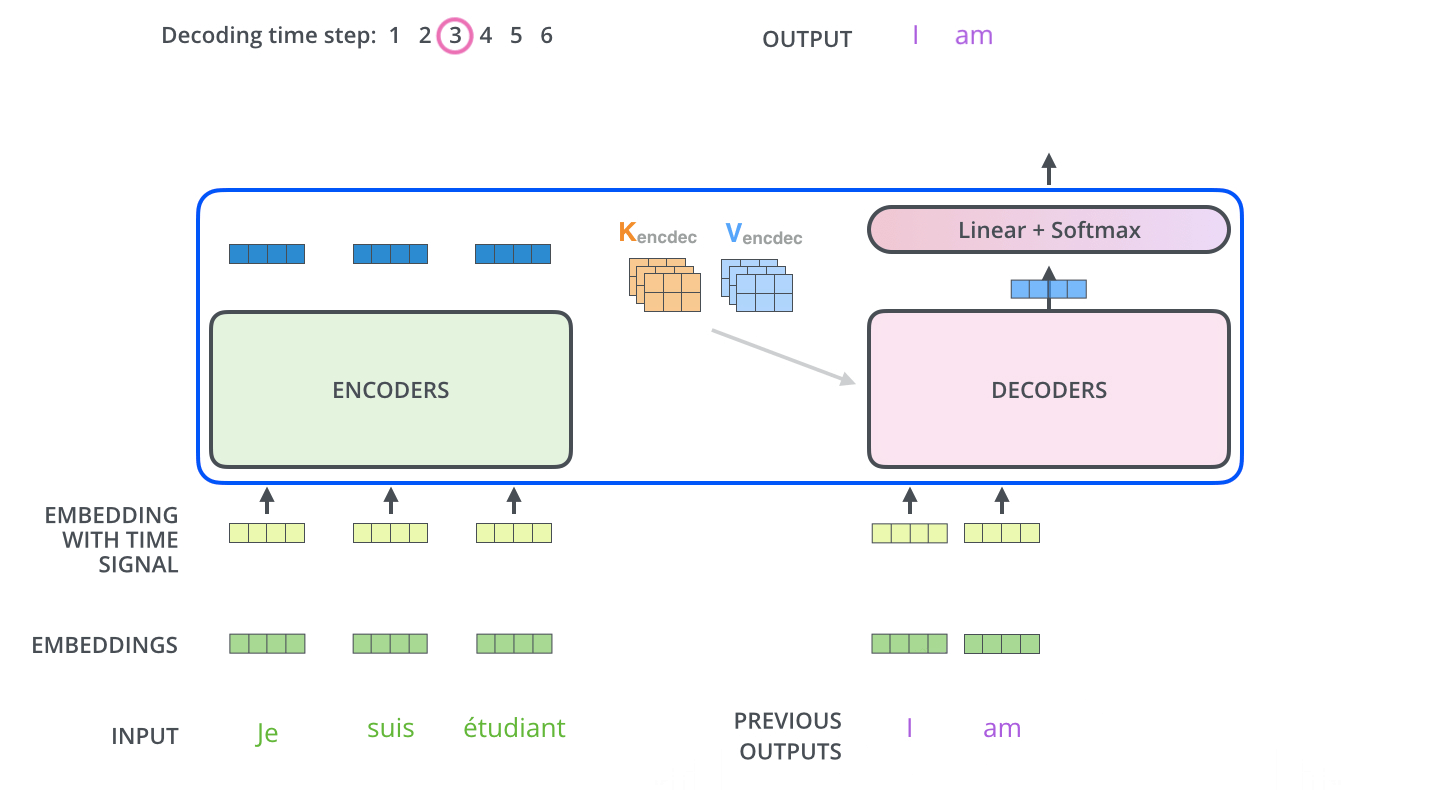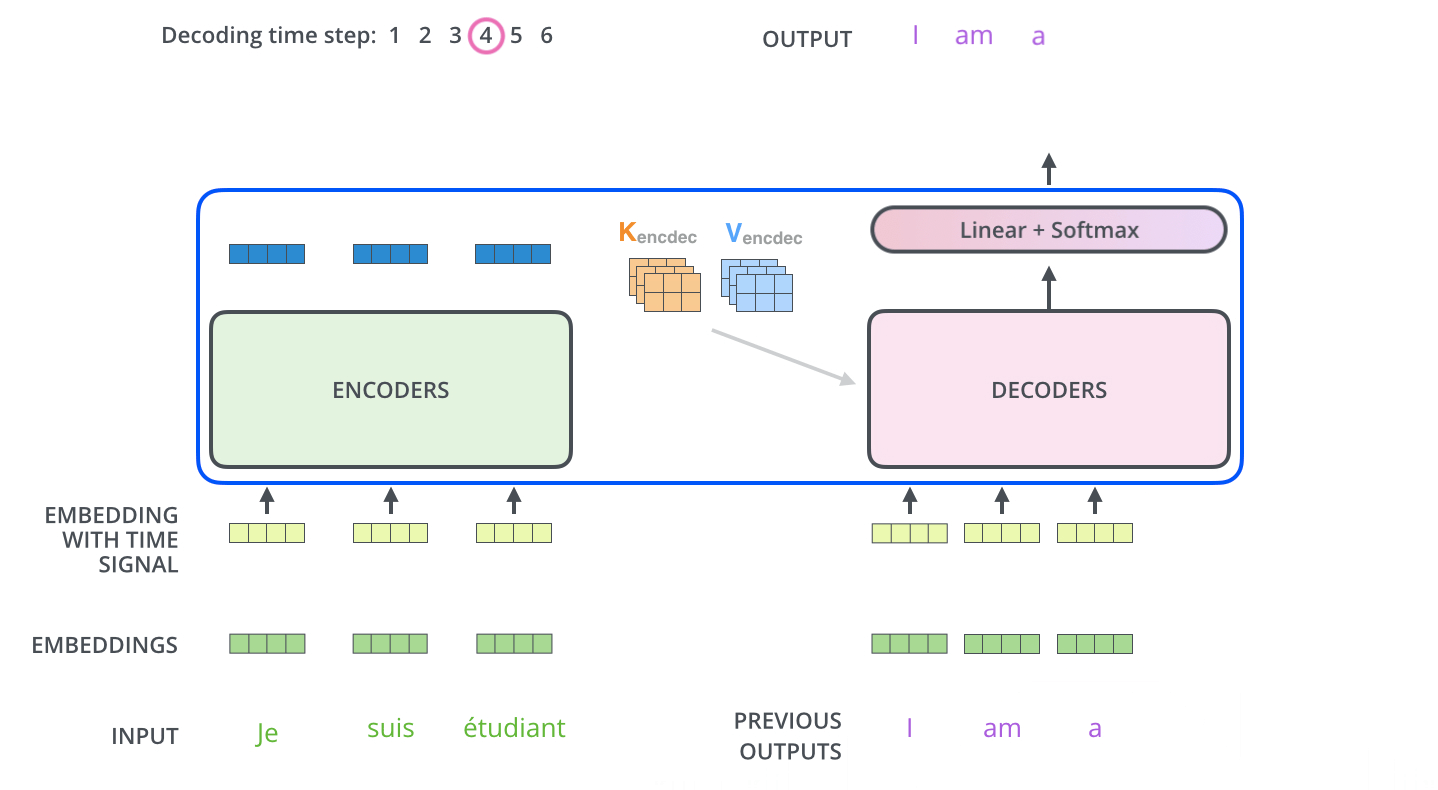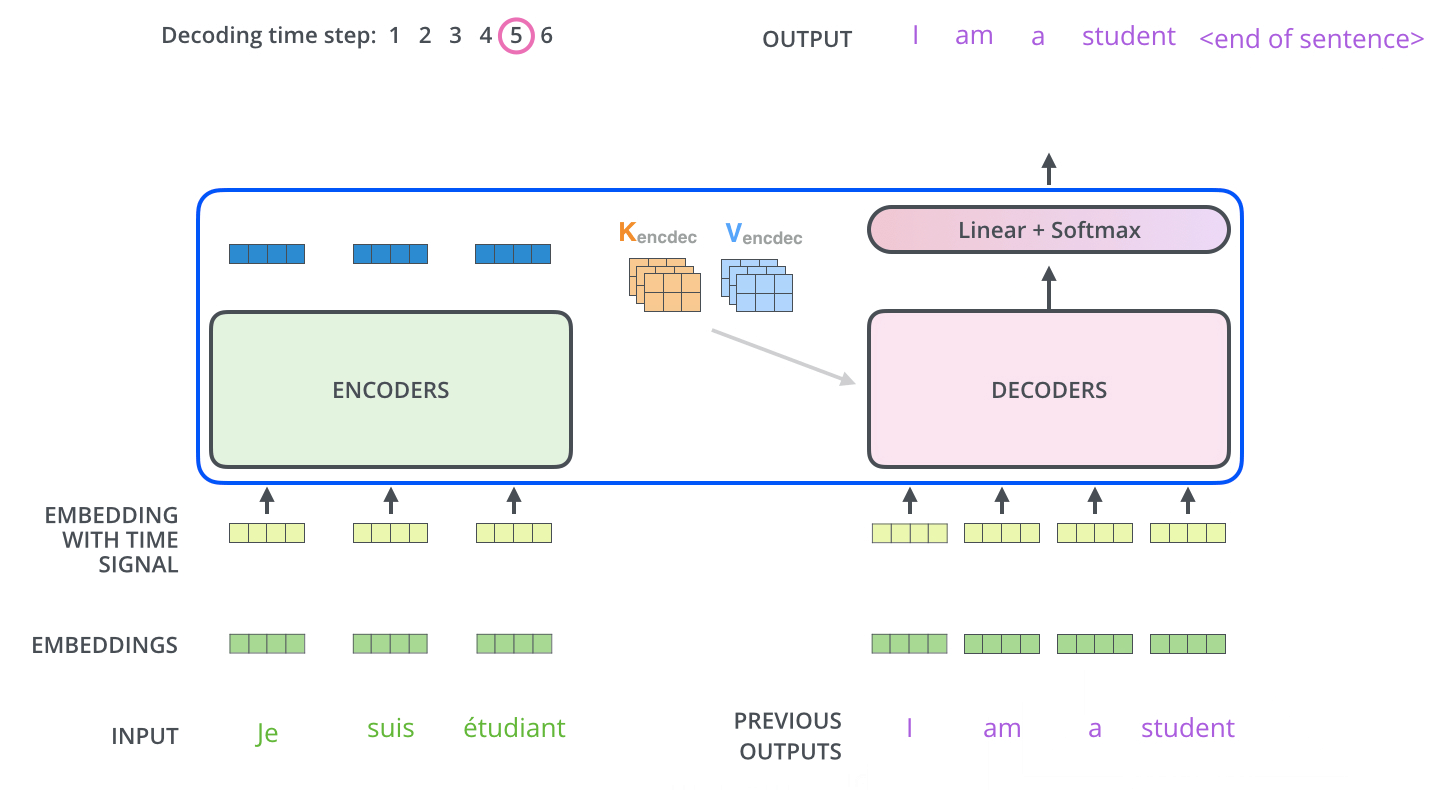
Decoder는 EOS (End Of Sentence)가 나올 때까지 순차적으로 Decoding을 반복합니다.
아래 그림과 같이, Decoder 또한 Output Sequence를 이용해서 가장 먼저 Self-Attention을 진행합니다.
하지만 Decoder의 가장 아랫단인 Self-Attention은 Encoder의 self-attention과 다르게 진행합니다.
Encoder는 한번에 sentence가 들어가서 병렬적으로 처리할 수 있었습니다. 주변 단어와의 depencies를 이용하면서 feature의 정보를 쌓았습니다.하지만 Decoder의 경우, 이전 output vector를 이용해서 순차적으로 진행되기 때문에 병렬 수행이 불가능하게 됩니다.
이를 해결하기 위해서, 다음 출력이 나오지 않은 상황에 그 자리에 -inf와 같이 마스킹해서 attention을 주면 병렬처리가 가능하게 됩니다.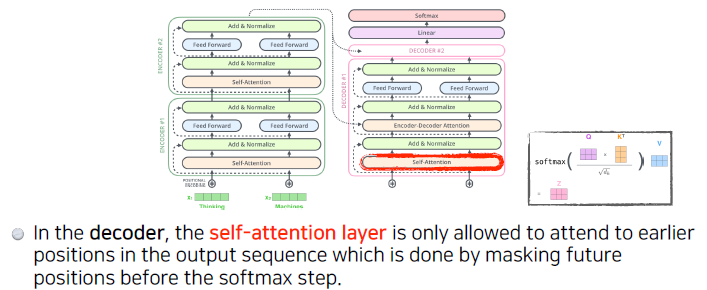
“Encoder-Decoder Attention” layer 은 multi-head self-attention과 비슷하게 작용하는 데, 차이점은 Query 행렬들을 그 밑의 layer에서 가져오고 Key 와 Value 행렬들을 encoder의 출력에서 가져옵니다.
다음은 Decoder 과정에 대한 동작입니다.
c. 디코더가 어떻게 generalize 할 수 있는지?
여러 개의 Decode 과정을 거친 후, Encoder와 비슷하게 하나의 vector로 출력됩니다. 이 마지막 vector를 단어로 바꾸는 것이 Linear Layer와 Softmax Layer가 하는 일 입니다.
Linear Layer는 Output으로 나온 vector의 각 셀을 logits vector로 투영시키는 역할입니다.
logits vector란? sigmoid 함수의 역함수로, Sigmoid가 [0, 1] 사이의 값으로 확률을 나타낸다면, 이러한 logit vector는 Softmax를 이용해서 전체 합이 1이 되는 확률 값으로 만들어줍니다. 이를 통해 확률이 가장 높은 vector셀의 index를 선택해 단어를 선택하는 방식입니다.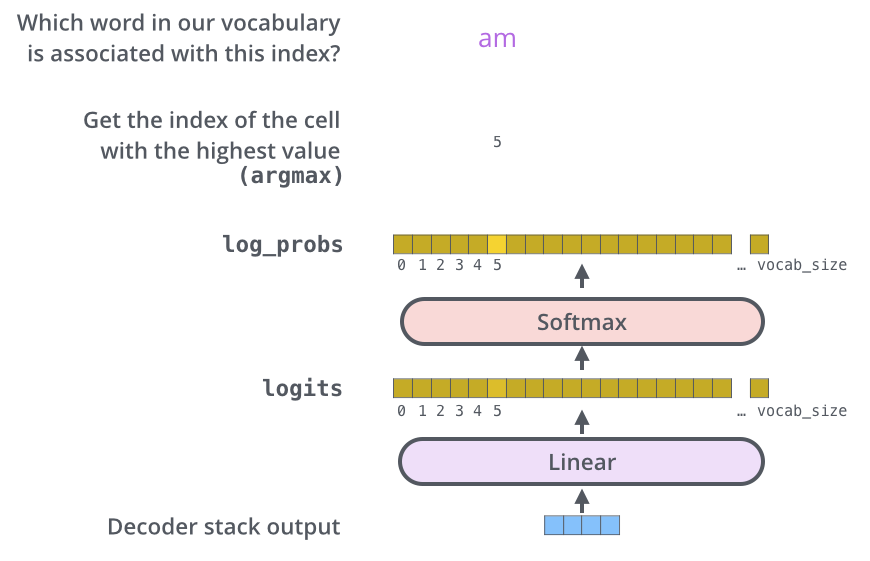
-